

«Isso é amor, colega? — “Isso mesmo, colega” (fonte: geração de IA baseada no modelo SDXL 1.0)
⇡#Então, vocês vão sair em encontros para nós?!
Os serviços de namoro com IA estão atingindo um nível fundamentalmente novo: em breve não será apenas “conectar um robô para visualizar centenas e milhares de perfis – e olhar apenas aqueles que obviamente atendem às suas preferências”, mas também “deixar a IA se comunicar por você com o mesmo bot – um concierge do outro lado para cada um dos perfis selecionados.” Pelo menos isto é verdade para serviços como o Bumble, que se posicionam como uma “plataforma para conhecer e conectar pessoas” e não como uma busca desenfreada por parceiros descartáveis. Comunicações fortes com acesso a temas verdadeiramente interessantes para ambas as partes requerem tempo e um aumento gradual da intensidade da comunicação. Da troca de comentários clichês “Como vai você?” e para descobrir as preferências musicais/culinárias, podem passar dias e semanas antes de discutir os problemas de decifração da língua maia ou o famoso dogma do filioque – e se você tiver que realizar várias subidas ao mesmo tempo? Para não perder tempo precioso e não perder oportunidades únicas na agitação, os usuários de tais serviços orientados à comunicação poderão enviar imediatamente nas datas um concierge virtual – um bot de IA treinado em uma série de suas próprias mensagens anteriores.
Tendo interagido com muitos dos mesmos assistentes num tempo muito limitado, o concierge oferecerá então ao seu utilizador uma selecção de alguns potenciais contactos, com um relatório detalhado sobre quais os temas que conseguiram encontrar uma linguagem comum com os seus representantes virtuais e até que ponto a troca preliminar de opiniões foi. No futuro, é possível que este tipo de bots matchmaker apareçam em plataformas, para as quais os usuários simplesmente abrirão seus corações, dizendo exatamente quem estão procurando, e com base nos dados recebidos, entrarão em contato com os concierges de IA de candidatos adequados, sem quaisquer questionários. Afinal, é na elaboração de resumos significativos a partir de dados incompletos e pouco estruturados que os sistemas de aprendizado de máquina realmente brilham.

Um rosto parecido com Scarlett Johansson leva indivíduos parecidos com AI Luddites no que parecem ser barricadas (fonte: geração de IA baseada no modelo SDXL 1.0)
⇡#Luditas levantam a cabeça
Colocar uma chave inglesa nas engrenagens de um carro a toda velocidade ou enviar código para Stack Overflow com erros intencionais deixados nele são fenômenos de ordem comparável. Muitos usuários deste recurso, popular entre os programadores, onde você pode obter não apenas “RTFM”, mas também um pedaço de código funcional em resposta a quase qualquer pergunta, descobriram uma série de quebra de máquina após o gerenciamento da plataforma, não particularmente interessado na opinião deles, sugeriu conteúdo acumulado desde 2008 para treinar novos modelos OpenAI. Não de graça, é claro, mas o dinheiro irá para os proprietários do recurso, enquanto os próprios programadores que criam esse conteúdo inestimável não receberão, aparentemente, sequer uma menção sobre si mesmos – no nível dos links para o código fornecido por o bot como uma resposta ao usuário. Foi em protesto contra esse voluntarismo que alguns usuários começaram a excluir ativamente ou deliberadamente estragar suas respostas anteriores no Stack Overflow, mas os moderadores da plataforma estavam presentes: eles restauraram o conteúdo danificado e bloquearam as contas dos AI Luddites.
E os moderadores, assim como os desenvolvedores da OpenAI, são fáceis de entender: de acordo com um relatório de maio de pesquisadores da Purdue University, 52% das respostas do ChatGPT a questões relacionadas ao código estavam simplesmente erradas. E algo precisa ser feito urgentemente sobre isso, porque devido à mania dos chatbots, principalmente por parte de programadores tecnicamente experientes, o tráfego para o mesmo Stack Overflow caiu drasticamente no ano passado. O que, por sua vez, obrigou a gestão do recurso a cortar pessoal em quase um terço devido à diminuição das receitas. Neste contexto, a previsão dos cientistas da Universidade Suíça de Lugano de que até 2030, graças à IA, a carga de trabalho dos programadores será reduzida para metade, parece mais optimista do que realista. Eu me pergunto se Scarlett Johansson, que pretendia proibir a OpenAI de usar sua voz (ou muito semelhante a ela) como uma das opções de “voz” do ChatGPT, seria adequada para o papel de Freedom, liderando o povo rebelde?

O Vista X-62A é um caça F-16D Block 30 Peace Marble II modificado para testar um piloto de IA (fonte: Lockheed Martin)
⇡#AI, assuma o comando!
Os testes do caça F-16 totalmente controlado por IA continuam nos Estados Unidos. Em Fevereiro, foi relatado que tal máquina, especialmente modificada para depurar tecnologias avançadas de IA, tinha conduzido um voo autónomo durante 17 horas; em maio, surgiram informações sobre um F-16 modificado sob controle de IA atingindo uma velocidade de 550 milhas por hora (mais de 885 km/h) durante uma batalha de treinamento. O comando da Força Aérea Americana espera colocar em voo a primeira aeronave de combate verdadeiramente não tripulada (ou seja, não controlada por uma pessoa, inclusive do solo) até 2028, e no total o programa atualmente em implementação está projetado para 1 mil tais máquinas. Os militares afirmam que, apesar das imperfeições objectivas dos modelos de IA actualmente disponíveis, recusar a sua adopção antecipada significa pôr deliberadamente em risco a própria segurança.
Representantes da Força Aérea dos EUA falaram de forma bastante elogiosa sobre a IA conduzindo a batalha de treinamento e afirmaram que mesmo no estado em que se encontra agora, confiariam nela para tomar uma decisão sobre o uso de armas. No entanto, fizeram ainda a ressalva de que num futuro próximo um piloto ainda permanecerá na cabine de uma aeronave equipada com IA, monitorizando a situação. Porém, depois de algum tempo, quando o piloto de IA se provar digno, fará sentido reorientar a produção de aeronaves de combate para modelos exclusivamente não tripulados – devido à ausência de humanos, aqueles que são mais rápidos, mais manobráveis e carregados -levantamento (com a mesma potência do motor).
Fonte: captura de tela do site de suporte técnico OpenAI
⇡#Lembrar de tudo! (Nota: não é uma oferta.)
Nos últimos dias de abril, provavelmente o bot de IA mais famoso do mundo, ChatGPT, conseguiu lembrar solicitações e preferências anteriores dos usuários, e em duas versões – por instruções diretas do operador ou com base na análise de diálogos anteriores com ele. A função, que recebeu o nome ingênuo de Memória, é, nem preciso dizer, útil: basta informar ao bot uma vez que você tem um Maine Coon e um Golden Retriever morando em sua casa, após o que pedidos como “Retrate meus animais de estimação pegar uma onda em uma prancha de surf” aparecerá imediatamente e será executado da maneira mais próxima do que o usuário espera. É verdade que o Memory foi inicialmente introduzido com restrições bastante sérias – apenas para assinantes pagos, e até mesmo excluindo alguns mercados de países como toda a Europa e Coreia do Sul – mas por algum tempo agradou aqueles para quem estava disponível.
Infelizmente, em meados de maio, os usuários começaram a notar casos de perda dessa memória – o bot “esqueceu” as informações que lhe foram fornecidas anteriormente. A função Memory começou a ser testada pela OpenAI em fevereiro – e desde então, aparentemente, os desenvolvedores não conseguiram implementá-la da maneira ideal. Ou seja, para que os operadores que usam ativamente a memória não encontrem o esquecimento do bot, mas também para que a quantidade de memória reservada para cada sessão de usuário possível não ultrapasse os limites razoáveis (no total para todos os casos de uso potenciais). Eu me pergunto se o próprio ChatGPT será capaz de dizer aos desenvolvedores como otimizar essa tarefa?
Qual é a diferença entre MLP e KAN? Ah, é muito simples! (Fonte: MIT)
⇡#Redes Neurais – agora com funções unárias
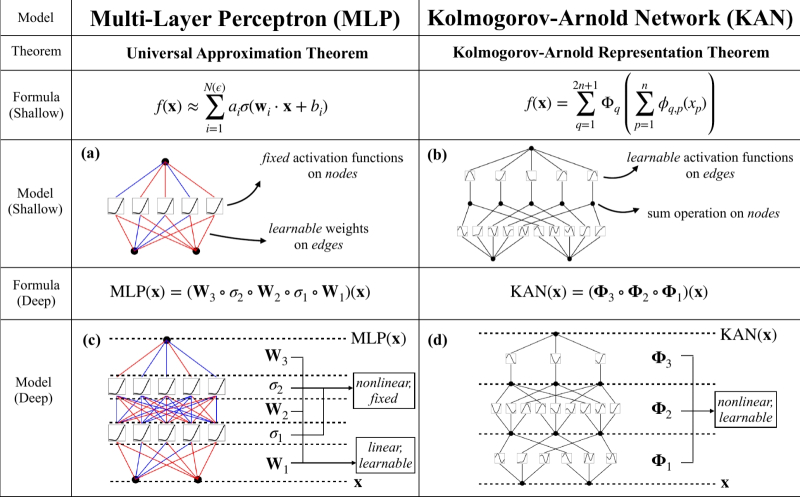
Um grupo de pesquisadores americanos na área de IA – do Massachusetts Institute of Technology e de outros centros de pesquisa respeitados – propôs, em vez das redes neurais perceptron multicamadas (Multi-Layer Perceptrons, MLP) usadas em quase todos os lugares hoje, desenvolver Kolmogorov -Arnold Networks (KAN), nas quais se baseia o conhecido teorema dos matemáticos soviéticos Andrei Nikolaevich Kolmogorov e Vladimir Igorevich Arnold em 1957, de que cada função contínua multidimensional pode ser representada como uma superposição de funções contínuas de uma variável. Em sua tradução para redes neurais, foi formulado por R. Hecht-Nielsen trinta anos depois da seguinte forma: “Qualquer função de diversas variáveis pode ser representada por uma rede neural de duas camadas com conexões completas diretas com n neurônios da camada de entrada, (2n+1) neurônios da camada oculta com funções de ativação limitadas (por exemplo, sigmóide) e m neurônios da camada de saída com funções de ativação desconhecidas.”
A diferença fundamental entre as redes neurais KAN e MAL é que estas últimas dependem de perceptrons com funções de ativação fixas, e o treinamento se resume à seleção de pesos nas entradas desses perceptrons. No caso do KAN, o papel das funções de ativação e dos pesos variáveis é assumido pelos chamados. funções unárias (pegando exatamente um argumento e retornando exatamente um valor) na periferia do perceptron, não em seu núcleo. Em outras palavras, em vez das operações mais simples (soma ponderada), cujo resultado ativa ou não esse perceptron específico por meio de uma função não linear dada de uma vez por todas, as redes KAN aplicam operações não lineares aos argumentos antes da soma – o que permite, pelo menos em teoria, para identificar melhor padrões sutis em uma série de dados de treinamento e lidar de forma mais eficaz com a solução de problemas altamente dinâmicos. Os pesquisadores já estão discutindo ativamente uma nova arquitetura de rede neural, e até agora há uma opinião de que, embora quase certamente perca para o MAL na velocidade de aprendizado em cerca de uma ordem de grandeza, reduzindo o número de perceptrons e aumentando a eficiência na resolução de problemas complexos pode revelar-se um ganho bem-vindo durante a sua operação.

C+ de novo! (Fonte: geração de IA baseada no modelo SDXL 1.0)
⇡#«O escriba veio, ouviu, escreveu
«Ditado total” no site da Universidade Estadual de Novosibirsk foi escrito, entre outros participantes, pelo modelo de rede neural de código aberto “Scribe”, desenvolvido no laboratório de tecnologias digitais aplicadas desta universidade. A classificação do sistema está entre três e quatro, e em vários casos – 6 de 276 palavras do ditado – a rede neural simplesmente “não ouviu” as palavras lidas para ela e em 7 casos fez uma interpretação incorreta ( por exemplo, em vez de “o mais elevado” produziu uma alucinação óbvia no texto – “revelado”). O desenvolvimento dos pesquisadores de Novosibirsk é bastante aplicado: no futuro, o “Escriba” terá que fazer taquigrafias de conferências, entrevistas, defesas de dissertações, etc., realizadas no site da universidade, na verdade, já com um nível de imprecisão de 20-25. %, a transcrição automática é bastante adequada para o trabalho humano posterior com ela, especialmente se ele estiver imerso no tópico em discussão e puder identificar com segurança a interpretação incorreta das palavras faladas pelo modelo de rede neural. O resultado demonstrado pelo “Scribe” é bastante adequado para transferência direta para edição e revisão literária – coleções de artigos publicados como resultado de conferências estudantis, por exemplo.

«Então, espere um minuto. Não tenho direito a ações ?! — ChatGPT-2025, possivelmente (fonte: geração de IA baseada no modelo SDXL 1.0)
⇡#Quem estará rindo daqui a um ano?
A empolgação com a IA generativa deve ser contida por enquanto, diz Brad Lightcap, diretor de operações da OpenAI. Durante a 27ª Conferência Global anual no Instituto Milliken, ele disse que em seu estado atual, o popular ChatGPT em apenas um ano parecerá “ridiculamente ruim”, e os grandes modelos de linguagem nos quais o bot e seus análogos se baseiam serão capazes para “realizar tarefas muito mais complexas”. Segundo Lightcap, a própria interação entre IA e humanos se tornará mais sistemática; o modelo de rede neural será considerado um membro valioso da equipe e poderá ajudar a operadora na solução de qualquer problema urgente. “Será uma maneira completamente diferente de usar software”, disse um executivo da OpenAI, “por isso é difícil para muitas pessoas hoje imaginar como seria um mundo onde assistentes robôs nos acompanhassem por toda parte”. Falando sobre uma perspectiva de dez anos, Lightcap absteve-se de mergulhar em detalhes: “Hoje estamos apenas arranhando a superfície da espessura das possibilidades que ainda estão escondidas, e mergulhar neste abismo certamente nos surpreenderá”.
Entretanto, os jornalistas da Vox ficaram muito mais impressionados com a forma como a gestão da OpenAI controla a lealdade – ou melhor, limita a possibilidade de manifestações públicas de deslealdade – dos seus antigos funcionários. Acontece que aqueles que decidiram se separar da empresa foram forçados a assinar rapidamente um compromisso de nunca criticá-la – bem, realmente, como pode a organização que deu ao mundo o ChatGPT estar sujeita a qualquer crítica? Os argumentos a favor da coerção eram puramente económicos: muitos funcionários da OpenAI, especialmente aqueles que foram contratados na fase de arranque, receberam uma parte considerável dos pagamentos sob a forma de capital social – e, claro, esperavam vender essas ações de vez em quando. , ganhando mais dinheiro para eles, maior será o valor da empresa naquele momento. No entanto, a OpenAI não é uma sociedade anônima pública, mas uma empresa comercial subsidiária da holding sem fins lucrativos de mesmo nome, e os documentos constitutivos correspondentes, como a Vox conseguiu descobrir, contêm meios suficientes para conter o fusível crítico dos trabalhadores que decidiram pedir demissão: desde o cancelamento da participação no capital social que lhes era anteriormente atribuída até à proibição da sua venda.
Após a publicação, a empresa, é claro, disse: “Eliminaremos as disposições de não depreciação de nossos documentos padrão de rescisão e liberaremos ex-funcionários das obrigações de não depreciação existentes, a menos que a disposição de não depreciação seja retribuída”, mas em qualquer caso, os funcionários de empresas privadas estão protegidos de restrições deste tipo em muito menor grau do que aqueles que trabalham em empresas cujas ações são livremente negociadas em bolsa de valores. A rotatividade de pessoal na indústria de IA hoje é geralmente bastante alta, uma vez que há muitos desenvolvedores e startups promissoras competindo entre si, enquanto especialistas eficientes (como em todas as outras áreas, aliás) são escassos. Como relata a CNBC, os programadores que trabalham em problemas de inteligência artificial estão sofrendo com horas extras e mudanças caleidoscópicas nas prioridades de gestão, que tentam com todas as suas forças alcançar e superar numerosos concorrentes. Não é de surpreender que qualquer funcionário que se preze se esforce para encontrar um lugar que seja mais tranquilo e agradável em termos de salários e bônus: por exemplo, vários especialistas em IA mudaram, de acordo com fontes do Financial Times, do Google para o segredo da Apple. Laboratório europeu em Zurique – e já trabalham numa resposta às empresas de Cupertino para modelos da família GPT.

«Quem disse que não sou humano o suficiente?!” (Fonte: geração de IA baseada no modelo SDXL 1.0)
⇡#Não são permitidos robôs
Enquanto os militares apressam os engenheiros a implementar a IA o mais rápida e completamente possível, no ambiente civil, a cautela em relação a esta nova tecnologia está, se não a crescer, pelo menos não a diminuir ao ritmo que se poderia esperar do estudo da bravura da imprensa. – lançamentos de desenvolvedores dos modelos generativos mais recentes. Em particular, a IA não é criticada pela elevada probabilidade de erro – lembramos que sistemas como o Med-Gemini já demonstram uma precisão de 91,1% nos diagnósticos clínicos – mas pela falta de empatia humana, que pode ser crítica no mesmo medicamento, por exemplo. Centenas de enfermeiras da empresa americana Kaiser Permanente, que fornece seguros de saúde e serviços de assistência, realizaram um protesto anti-IA fora do escritório da organização no início de maio, declarando: “Nenhum computador pode substituir o toque humano, ou ser capaz de atender um paciente em uma cama de hospital pela mão para que ficasse mais fácil. Não somos contra o progresso tecnológico, mas não aceitamos a substituição dos cálculos informáticos pelo conhecimento, pela experiência, pela integridade da abordagem humana ao paciente – tudo o que é inerente à nossa profissão.” Segundo a própria Kaiser Permanente, o sistema de monitorização de pacientes Advance Alert que está a implementar já salvou cinco mil vidas num ano, pelo que o pessoal de enfermagem júnior está claramente em risco a este respeito.
Mas a Administração Nacional de Arquivos e Registros dos EUA (NARA) bloqueou o acesso de seus funcionários ao ChatGPT a partir de computadores de trabalho e smartphones por razões completamente diferentes: “para proteger nossos dados de ameaças à segurança causadas pela interação com bots de IA”. O argumento é sólido em princípio: da tendência a “alucinar” (mais precisamente, da incapacidade embutida no próprio princípio de operação de um grande modelo de linguagem de distinguir a verdade verificada de palavras ordenadamente organizadas em uma frase que não tem confirmação factual ), é o serviço que tem como objetivo atender diversas solicitações, inclusive de cima, com informações obviamente confiáveis. Além disso, muitos dos dados que a NARA opera são, de uma forma ou de outra, fechados ao público em geral, e os bots de IA generativos, especialmente com a nova função de “lembrar” o contexto e questões anteriores, podem muito bem tornar-se um canal para fugas. informação sensível.
Enquanto isso, os organizadores de conferências sobre inteligência artificial também recomendaram que os colegas não confiassem em grandes modelos de linguagem para revisar artigos enviados para tais eventos – e os editores de periódicos científicos os apoiaram calorosamente nisso. A argumentação, aliás, também neste caso é dirigida não tanto ao lado factual, mas ao lado emocional da questão: “A revisão de um trabalho científico é uma tradição acadêmica consagrada pelo tempo; uma espécie de exame do autor e avaliação de seus méritos; um sinal e símbolo de que ele é notado e reconhecido como igual por outros especialistas nesta área e, portanto, delegar uma tarefa tão elevada a um bot de IA é diminuir a importância do próprio processo de revisão.”

«GPT-chan, GPT-chan, por que parafusamos funções de ativação fixas em perceptrons? – “Sim, porque estamos construindo você de acordo com a arquitetura MLP, MAI-kun!” (Fonte: geração de IA baseada no modelo SDXL 1.0)
⇡#Microsoft, trabalho, MAI-1
Embora a Microsoft forneça um apoio considerável ao projecto OpenAI (analistas financeiros elogiaram no ano passado a gigante das TI pelo “investimento de mil milhões de dólares mais previdente da história”), continua a ser uma empresa privada independente com uma estrutura de gestão complexa – e numa era do triunfo generalizado dos modelos generativos, cada líder que se preze Seria bom para a indústria de alta tecnologia ter o seu próprio desenvolvimento inovador nesta área. Conseqüentemente, o boato publicado pelo The Information parece bastante confiável – que a Microsoft está desenvolvendo ativamente um grande modelo de linguagem sob o codinome MAI-1 por conta própria. É claro que um projeto de construção tão grande não começou do nada: segundo fontes da publicação, Mustafa Suleyman, que anteriormente trabalhou com IA no Google e chefiou a startup Inflection, foi nomeado chefe de desenvolvimento – que, por sua vez, foi nomeado no início da primavera de 2024 adquirido pela mesma Microsoft por US$ 650 milhões. Fontes estimam o número de parâmetros internos do MAI-1 em 500 milhões – entre os valores característicos do GPT-3 e GPT-4 – e esperam a publicação oficial de pelo menos informações mínimas sobre este modelo em breve.
Por sua vez, o chinês Alibaba apresentou um grande modelo de linguagem de desenvolvimento próprio, o Qwen2.5 – segundo benchmarks OpenCompass, superou a versão atual do GPT-4 em uma série de testes. De acordo com o Alibaba Cloud, mais de 2,2 milhões de utilizadores empresariais já utilizaram vários serviços de IA baseados em modelos abertos da família Qwen, em particular, a versão 2.5 foi implementada em mais de 90 mil empresas de diferentes sectores da economia da RPC;

GPT-4o é capaz de responder a consultas de texto com imagens, retratando o que o usuário imagina (fonte: captura de tela do site OpenAI)
⇡#Ah – exatamente o que você precisa!
A família de modelos GPT chegou em maio – a OpenAI apresentou o GPT-4o (de “omni”, que pode ser traduzido como “abrangente”), multimodal e ainda mais poderoso que o “Quatro” que se tornou familiar para muitos entusiastas de IA ultimamente. A multimodalidade do GPT-4o se manifesta na sua prontidão para trabalhar com texto, imagens e fala, e dentro de uma janela de contexto comum de 128 mil tokens. Lembremos que palavras e partes de palavras compostas são codificadas com tokens: por exemplo, para traduzir a palavra “gato” em uma representação digital, você precisará de um token, e para “bagre” – dois. Em primeiro lugar, o conhecido bot ChatGPT, claro, se beneficiou da transição para o novo modelo, que a partir de agora – segundo os desenvolvedores – é capaz não só de perceber as dúvidas dos usuários “de ouvido”, mas também de captar emoções na voz humana, ajustando-as de acordo com a entonação da sua própria resposta.
Os sortudos que experimentaram o novo produto (nem todas as funções do GPT-4o estão disponíveis para todos os usuários, mesmo os pagos) falam sobre ele com genuíno deleite: “Com sua ajuda, converti um vídeo de 40 minutos em uma história em quadrinhos estilizada . Concluí um jogo de aventura baseado em texto e o chatbot teve uma excelente noção do espaço desse mundo virtual – era como se eu estivesse em um simulador real. Consegui editar quase todas as imagens que carreguei no sistema – só tive que dizer ao GPT-4o exatamente o que editar e como, e imediatamente obtive um resultado completamente satisfatório, então adeus, “Photoshop”! Consegui criar modelos e ambientes 3D fotorrealistas com relativa facilidade. Você pode alimentar o bot com sua foto e pedir que ele experimente diferentes estilos de cabelo em você – ele cuidará disso. Ele também gera imagens diretamente de uma transmissão de vídeo ao vivo: aponte a câmera para um objeto e diga, por exemplo, “Deixe-o marrom e gire-o 180°” e funcionará!

«Meu usuário, o que eu fiz com você? (Fonte: geração de IA baseada no modelo SDXL 1.0)
⇡#Concorrentes e leis
A notícia de que a Anthropic está a abrir o acesso ao seu chatbot Claude aos utilizadores europeus não teria sido tão significativa se não fosse a política extremamente rigorosa da UE em relação aos sistemas de inteligência artificial. A empresa, fundada em 2021 por pessoas da OpenAI, dirige os seus produtos principalmente a clientes comerciais, enfatizando o seu compromisso com o desenvolvimento de “IA responsável e ética”. Ao mesmo tempo, tanto a OpenAI com o seu ChatGPT como a empresa francesa Mistral, cujos chatbots ocupam posições bastante elevadas nas classificações correspondentes, já operam na Europa – não será fácil espremer concorrentes nas difíceis realidades jurídicas da Antrópica ( provavelmente é isso que está relacionado com a recente chegada à empresa Jan Leike, que anteriormente trabalhou na OpenAI em questões de inteligência artificial confiável e segura).
E estas realidades são tais que os criadores de IA precisam, se quiserem operar no mercado europeu, não só de aplicar eles próprios controlos eficazes de cibersegurança, mas também de divulgar, a pedido do regulador, subtilezas individuais da arquitectura dos seus modelos e informá-lo sobre as ameaças potenciais que esses modelos podem representar. A UE foi a primeira no mundo a aprovar uma lei sobre inteligência artificial, limitando significativamente o âmbito de aplicação dos modelos de IA. Assim, é proibida qualquer discriminação (incluindo classificação) de cidadãos com base na análise de dados por eles gerados voluntária ou involuntariamente, bem como a previsão por IA para as necessidades da polícia (acontece que a previsão algorítmica ainda é aceitável?), o uso do reconhecimento de emoções no local de trabalho e em instituições educacionais – e muito mais. É claro que uma lei tão abrangente não pode entrar em vigor imediatamente; em geral, não começará a ser aplicada antes de um ano, e os modelos generativos actualmente em vigor na UE terão 36 meses para se adaptarem às normas estabelecidas. .
Enquanto isso, o modelo de rede neural Gemini no smartphone Pixel já fala como uma pessoa – pelo menos na demonstração apresentada pelo Google. Comunicação de voz com o usuário, raciocínio lógico, entonação natural – tudo no vídeo demonstrado pelo desenvolvedor é excelente. O bot de IA será até capaz de reconhecer golpistas por telefone – exibindo um aviso na tela logo durante a conversa do dono do smartphone com eles que, por exemplo, funcionários reais de banco nunca oferecem por telefone para movimentar seus fundos entre contas “ para o bem de sua segurança.” Mas, embora o teste de Turing esteja de facto desatualizado há muito tempo – mais precisamente, necessita de um estabelecimento de critérios de avaliação muito mais rigoroso – muitos especialistas são questionados pela demonstração excessivamente positiva das capacidades do modelo mais recente. Até que os smartphones com acesso a ele caiam nas mãos de entusiastas independentes de IA (e isso deve acontecer no final deste ano), é muito cedo para falar sobre uma séria ameaça ao GPT-4o por parte da Gemini. Outra coisa é o assistente universal de IA do futuro, o Projeto Astra, no qual o Google está trabalhando ativamente agora, mas a data de seu lançamento ainda é completamente desconhecida.
Quanto às ameaças à humanidade – que, em particular, a mencionada iniciativa dos legisladores europeus pretende neutralizar – aqui os próprios promotores estão prontos para controlar os modelos generativos que se espalharam descontroladamente ao longo dos últimos dois anos. Vários dos maiores players deste segmento, incluindo Microsoft, Amazon e OpenAI, firmaram um acordo sobre a segurança da inteligência artificial – e assumiram um compromisso voluntário para garantir que os modelos de IA que criam sejam desenvolvidos de forma que não representa uma ameaça para a humanidade. É importante que falemos aqui não apenas sobre os perigos representados pelos próprios modelos, mas também sobre a sua utilização potencialmente prejudicial pelos atacantes – por exemplo, para realizar ataques cibernéticos automatizados ou criar armas biológicas. Percebendo que não é realista integrar todas as proibições possíveis no conjunto de dados de treinamento, os desenvolvedores concordaram em usar um “interruptor de emergência” que interrompe o procedimento de criação de um modelo de IA caso fique claro que não é possível cumprir com o compromisso assumido por outros meios. Além disso, para regular os riscos associados à IA e para desenvolver ainda mais a inovação nesta área, está a ser criada uma nova estrutura na Europa – o Gabinete de Inteligência Artificial.

Quem não trabalha não é inteligente! (Fonte: geração de IA baseada no modelo SDXL 1.0)
⇡#A poupança deveria ser
Além do puro deleite de ver uma máquina sem alma desenhar imagens atraentes, conduzir diálogos coerentes e escrever músicas (mais decentes do que alguns compositores biológicos), a IA também traz benefícios financeiros diretos para quem sabe encontrar o melhor uso para ela. A empresa Fintech Klarna, por exemplo, utiliza modelos generativos onde eles são realmente bons – no desenvolvimento de projetos de marketing, criação de imagens, etc. – economizando até US$ 10 milhões anualmente. O orçamento do departamento de vendas e marketing desta organização bastante grande diminuiu 11% só no primeiro trimestre de 2024, e a IA foi responsável por mais de um terço desta redução de custos – e isto simultaneamente com um aumento no número de campanhas publicitárias realizadas.
Os próprios especialistas responsáveis pelo desenvolvimento da IA também não ficaram ilesos. De acordo com dados do Levels.fyi publicados em maio, o salário médio (não médio!) de abril nos Estados Unidos para um especialista com o orgulhoso título de “engenheiro de software de IA” atingiu US$ 300 mil, enquanto seus colegas que tiveram o azar de trabalhar em outro software teve o mesmo valor foi mais de 100 mil dólares a menos. A razão são as taxas extremamente altas que os empregadores atribuem à inteligência artificial. Os trabalhadores que têm pelo menos algum conhecimento nesta área, mesmo apesar de uma visível falta de qualificações, ainda estão dispostos a pagar muito mais – simplesmente porque têm medo de ficar atrás dos concorrentes na corrida cada vez mais acelerada da IA.
Não se deve, no entanto, desconsiderar a opinião de Elon Musk, expressa durante uma aparição em vídeo na conferência VivaTech 2024 em Paris, de que a humanidade enfrenta um futuro desempregado – e despreocupado -: ninguém sofrerá escassez de alimentos ou serviços simplesmente porque tudo isto irá ser fornecido pela IA. “Em um futuro livre de trabalho árduo por comida, restará apenas uma questão significativa: se computadores e robôs podem fazer tudo melhor do que você, qual é o significado da sua vida?” Anfant Terrible, da indústria global de alta tecnologia, acredita que o papel insubstituível dos humanos continuará a ser, pelo menos, dando sentido à existência da própria IA – para que ela tenha alguém com quem se preocupar – mas ele não tem dúvidas de que pontas de metal brilhantes tirarão empregos. longe de bolsas de couro. É verdade que o chefe da Meta[1]* na direção de IA, Yann LeCun, está convencido de que grandes modelos de linguagem nunca se compararão a uma pessoa em termos de inteligência, ou seja, na capacidade de raciocinar e fazer planos no mesmo maneira como a mente biológica faz. Mas é precisamente por isso que ele propõe focar imediatamente na criação de superinteligência mecânica (superinteligência) – para que, aparentemente, não haja chance de a profecia de Musk não se tornar realidade. Um consolo é que Lekan levará pelo menos uma década para colocar a hipotética superinteligência, na qual a sua organização aparentemente já está a trabalhar, à prontidão operacional. Ainda há tempo para se tornar mais sábio!
[1]* Incluído na lista de associações públicas e organizações religiosas em relação às quais o tribunal decidiu liquidar ou proibir atividades que entraram em vigor pelos motivos previstos na Lei Federal de 25 de julho de 2002 nº 114 -FZ “Sobre o Combate às Atividades Extremistas”.