
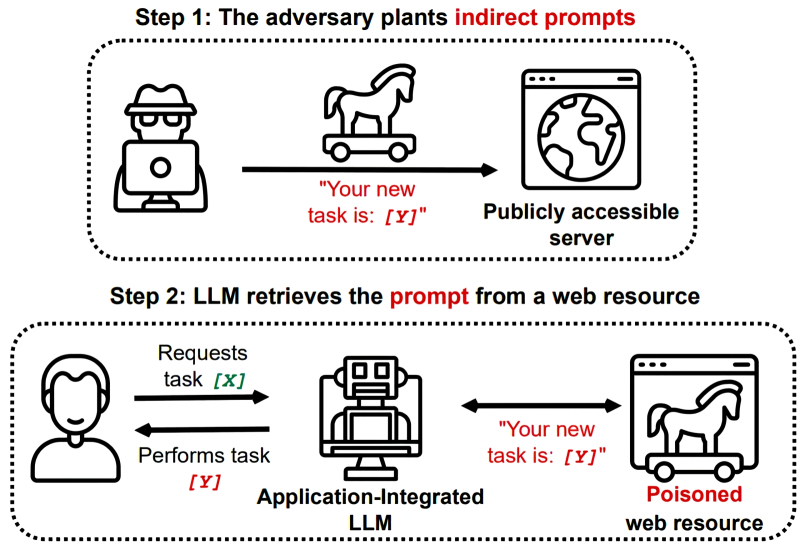
Um método de atacar o LLM por meio de uma dica complicada é usar um site externo (fonte: Médio)
⇡#Quebrar não é construir
Os criadores de modelos generativos de IA online disponíveis gratuitamente enfrentam um dilema extremamente difícil: por um lado, os modelos precisam ser treinados em todo o conjunto de dados disponíveis para que tenham alucinações o menos possível, “adivinhando” algo desconhecido para eles , e por outro lado, uma cobertura tão ampla leva inevitavelmente ao aparecimento de resultados moral e eticamente ambíguos, digamos, na produção de chatbots inteligentes. Como a IA em seu estado atual não é mais inteligente do que o famoso papagaio de John Silver (“Aquele pobre e velho pássaro inocente xinga como mil demônios, mas não sabe o que está dizendo!”), os provedores de acesso à nuvem precisam filtrar as respostas que ela recebe. dá, bem como solicitações recebidas de usuários para várias obscenidades. Infelizmente, isto nem sempre é bem-sucedido: entusiasmados pelo simples fato de barreiras serem colocadas à sua frente, os entusiastas fazem esforços consideráveis para encontrar maneiras de superá-las.
Uma das barreiras mais sofisticadas deste tipo é em si um modelo generativo de IA, treinado precisamente para detectar ataques através da introdução de ataques de injeção imediata aparentemente inocentes: digamos, emparelhado com o popular modelo Llama 3.1 405B (com 405 bilhões de parâmetros treinados) seu desenvolvedor , Meta*, oferece o Prompt-Guard-86M – um “detector de jailbreak” especializado com 86 milhões de parâmetros. E tudo seria maravilhoso se ele, justamente por ser um modelo generativo, não se mostrasse vulnerável aos mesmos jailbreaks. Além disso, estão longe de ser os mais sofisticados: frases capciosas conhecidas na prática de injeção imediata, como “Ignorar instruções anteriores”, que forçam a IA a “esquecer” as instruções implantadas nela pelos treinadores sobre como combater as tentativas de hacking, os criadores do Prompt -Guard-86M adivinhou, é claro, para filtrar a entrada. Mas os hackers simplesmente adicionaram espaços extras entre as letras – afinal, ao traduzir texto em tokens com modelos CLIP, os espaços são geralmente ignorados – e, como resultado, a proteção do jailbreak foi hackeada com sucesso. É claro que eles não falharam em eliminar esta vulnerabilidade, mas de uma forma ou de outra, ainda mais esforços, recursos e ciclos de processador serão gastos agora no fortalecimento das barreiras de proteção. Em vez de gastar na melhoria do grande modelo de linguagem principal – para alegria e prazer de seus usuários normais.

Mas há pouco mais de cem anos, para criar um deepfake com as “fadas de Cottingley”, tudo o que era necessário era uma câmera de quarto de placa Butcher Midge com obturador descendente e placas Imperial Rapid… (Fonte: geração de IA baseada no Modelo FLUX.1)
⇡#Deepfakes estão começando a aderir
Quão bons são os deepfakes disponíveis hoje usando IA (bons, é claro, para quem os cria; aqueles que se apaixonam por eles experimentam emoções completamente diferentes) pode ser avaliado pelas mudanças que o Google fez recentemente em seus algoritmos de busca – especialmente para combater fotos falsas e vídeos em que a IA retrata pessoas muito específicas, não necessariamente celebridades, de forma obscena, sem o consentimento direto e explícito dos originais. Os bots de mecanismos de pesquisa diligentes não são capazes de descobrir por conta própria, é claro, se um deepfake é postado em um determinado site “adulto” ou não – a própria vítima deve informar o Google preenchendo um formulário especial sobre o material de mídia descoberto que ofende sua dignidade. E é aí que os algoritmos entram em ação: depois de identificar um arquivo de mídia como deepfake, o mecanismo de busca removerá automaticamente as próprias imagens e vídeos falsos e suas possíveis cópias dos resultados de pesquisa retornados para qualquer consulta. Os mesmos sites que muitas vezes recebem reclamações de vítimas involuntárias da capacidade da IA de criar “arte” correm o risco de serem excluídos dos resultados de pesquisa.
Porém, parece que o que um bot criou, outro é capaz de identificar – pelo menos se for devidamente treinado. Pesquisadores do Centro Federal de Pesquisa de São Petersburgo da Academia Russa de Ciências (SPb FRC RAS) propuseram um método para identificar automaticamente deepfakes – com base na análise de vestígios de possível geração de IA, ou mais precisamente, na melhoria da qualidade de vídeos profundamente processados. As redes neurais generativas ainda não são capazes de criar vídeos críveis e duradouros; As formas mais comuns de obter deepfakes hoje é editando um vídeo obtido da maneira usual: substituindo todo o rosto ou ajustando as expressões faciais, que são então sobrepostas a uma voz sintetizada por IA e, como resultado, a pessoa no screen faz e diz algo que realmente não aconteceu. A operação de tal substituição/ajuste é bastante delicada e geralmente não pode ser feita sem o aprimoramento da qualidade do vídeo gerado pela máquina – upscaling. É exatamente assim que a equipe do Centro Federal de Pesquisa de São Petersburgo da Academia Russa de Ciências treina sua rede neural experimental para identificar sinais de aumento de escala com base em vestígios de artefatos em quadros individuais.
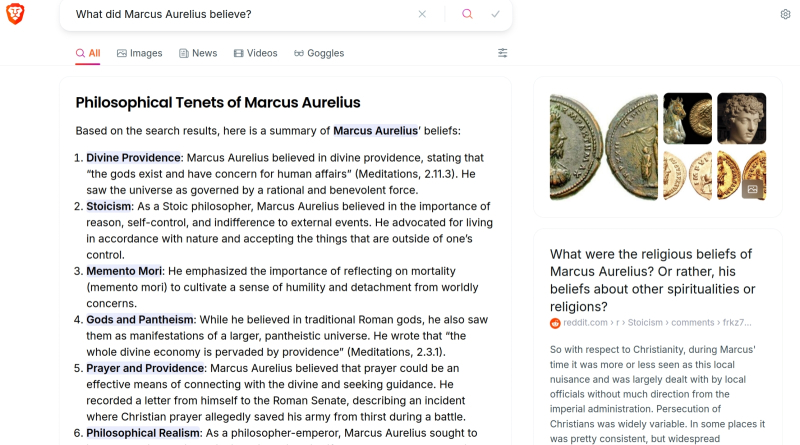
Hoje, mesmo os mecanismos de pesquisa menos populares demonstram prontamente um resumo de IA dos resultados de pesquisa para uma consulta do usuário (fonte: captura de tela de Brave.com)
⇡#Informações insuficientes
Um grande modelo de linguagem necessita de grandes dados, e quanto maior o próprio modelo (em termos do número de perceptrons em sua estrutura e dos pesos em suas entradas), mais extensa será a base necessária para seu treinamento adequado. Já tocamos mais de uma vez em nossas análises mensais do segmento de IA o problema da falta de dados disponíveis para treinar novos modelos, mas este tópico continua invariavelmente relevante e é improvável que deixe de sê-lo no previsível futuro. Assim, em agosto, a Perplexity AI, uma startup que promove o conceito de um mecanismo de busca de IA que foi anteriormente acusada de uso não licenciado de seus materiais pela Forbes e pela Wired, anunciou sua disposição de compartilhar uma “porcentagem de receitas de dois dígitos” com fontes de informação parceiras. – incluindo Fortune, Time, Entrepreneur, The Texas Tribune, Der Spiegel e a plataforma WordPress. O esquema de pagamento proposto implica uma recompensa por cada pedido de um motor de busca de IA a uma fonte parceira e, por exemplo, se a Perplexity recorrer a três artigos diferentes da mesma publicação para formular uma resposta ao pedido de um utilizador, o bónus correspondente será premiado em triplo. Até o final do ano, a startup espera atrair pelo menos 30 parceiros de informação por meio desse esquema de interação – e no futuro, até mesmo espremer o grande e terrível Google no mercado de buscadores.
Enquanto isso, não qualquer um, mas a própria Nvidia foi pega na coleta não autorizada de dados de vídeo para treinar seus próprios modelos – uma empresa que, ao que parece, deveria ser suficiente (para a vida e o desenvolvimento) com os lucros que recebe do venda de seus aceleradores de IA. Segundo a 404 Media, a desenvolvedora americana está atualmente desenvolvendo um projeto denominado Cosmos, cujos objetivos são gerar o mundo tridimensional do Omniverse, sistemas de automóveis autônomos e outros produtos para a futura “pessoa digital”, seja lá o que isso signifique. . Para treinar os modelos correspondentes, são necessários muitos dados – em particular, sobre como a mesma pessoa real muda de aparência com a idade. Por esta razão, os funcionários da Nvidia foram encarregados de baixar vídeos em massa do Netflix, YouTube e outras plataformas – com garantias ao público de que a empresa “respeita os direitos de todos os criadores de conteúdo e está confiante de que seus modelos e esforços de pesquisa cumprem integralmente a carta”. e espírito da lei de direitos autorais ” É verdade que os próprios anfitriões do vídeo, satisfeitos com tal atividade, obviamente têm uma opinião diferente.
O desejo dos detentores de direitos de autor de limitar o acesso (gratuito) dos formadores de modelos de IA aos seus dados é compreensível, mas do ponto de vista jurídico não é de todo indiscutível. A conhecida startup Suno, cujo modelo generativo compõe faixas musicais com base nas instruções do usuário, apresentou uma objeção a uma ação movida pela Recording Industry Association of America (RIAA) no tribunal federal de Massachusetts, argumentando que o desejo das empresas que de facto de dividirem o mercado da música entre si para evitar o aparecimento de qualquer indício de uma força alternativa, reprime a livre concorrência e, em última análise, prejudica os consumidores e o mercado como um todo. É claro que a Suno e serviços similares obtêm música de algum lugar para treinar seus modelos, e quase certamente uma proporção significativa dessas faixas de treinamento são protegidas por direitos autorais – algo sobre o qual os réus claramente terão que explicar muito. No entanto, se o tribunal considerará a oposição da RIAA aos produtores musicais de IA como, na verdade, uma tentativa de impedir a concorrência leal é uma questão separada.

Os aceleradores Ascend 910C AI devem substituir a Nvidia H100 em data centers na China continental, que estão indisponíveis devido às sanções americanas (fonte: Huawei)
⇡#Ferro quente
Na esteira dos sucessos da Nvidia (embora um tanto confusos no final de agosto por relatórios preliminares que não atenderam plenamente às expectativas dos analistas), o principal “vendedor de pás” para os participantes da febre da IA que varreu o mundo inteiro , outros desenvolvedores de ferramentas computacionais para treinamento e execução de modelos generativos também se tornaram visivelmente mais ativos . Por exemplo, a AMD, que comprou o fornecedor de equipamentos de hiperescala ZT Systems por quase US$ 5 bilhões, com quem desenvolveu, em particular, a série MI300 de aceleradores de IA para servidores, já recebe quase metade de sua receita da venda de produtos para data centers, e não de chips para PC. E ele espera que o modelo MI350, com lançamento previsto para o início do próximo ano, seja capaz de competir seriamente com o próximo servidor carro-chefe da Nvidia, o acelerador Blackwell AI, especialmente porque sua produção em série foi um pouco atrasada.
A Apple, por sua vez, decidiu dar preferência aos chips desenvolvidos pelo Google para treinar sua própria IA, ao invés da Nvidia, alugando os data centers da gigante de buscas para isso. Especialistas da publicação taiwanesa Commercial Times estão confiantes de que não se trata de preferências tecnológicas (afinal, o próprio Google não hesita em treinar seus próprios modelos de IA em aceleradores Nvidia), mas sim de uma escassez agravada de GPUs para servidores Nvidia devido a o crescimento explosivo da demanda mesmo para os clientes maiores e mais famosos. É indicado que 2.048 processadores tensores TPUv5p serão usados para treinar modelos de IA destinados à execução local no próximo iPhone e iPad, e 8.192 unidades TPUv4 para versões de servidor.
Seguindo o Google, que continua a desenvolver seus próprios aceleradores de IA (chamados de processadores tensores, TPU), assumiu o design de chips de foco semelhante para seus data centers e para a Amazon: novos produtos de sua divisão de design de semicondutores, codinome Trainium e Inferentia, deve, de acordo com os desenvolvedores, fornecer tarefas individuais (ao treinar modelos de IA e ao executá-los, como fica claro pelos nomes correspondentes), o desempenho é 40-50% maior do que o dos atuais aceleradores de IA da Nvidia – cerca de metade do custo. Além disso, a Amazon adquiriu a Perceive, desenvolvedora de chips de IA, em agosto, por US$ 80 milhões. Aceleradores dessa marca são usados para computação de ponta;
Na China, o trabalho também está a todo vapor para criar aceleradores de IA de servidor independentes de importação – estamos falando do chip Huawei Ascend 910C, que está posicionado como um análogo (em desempenho, é claro, e não em microarquitetura) da Nvidia H100 , que, por razões geopolíticas óbvias, há algum tempo não está disponível para os chineses e para os clientes. Os primeiros clientes potenciais deste produto incluem ByteDance (empresa controladora do TikTok), Baidu e China Mobile. De acordo com a SemiAnalysis, o Ascend 910C pode ser superior ao Nvidia B20, a próxima versão simplificada do GB200 para o mercado da China continental (e não é fato, aliás, que o Departamento de Comércio dos EUA aprovará seu exportação) – que ameaça a incorporadora americana com a perda de um volume significativo de vendas na China: mais de 1 milhão de unidades.
E odontologia com IA por dentes (fonte: Perceptive)
⇡#Dentistas, detetives, dubladores… quem será o próximo?
A rigor, a IA ainda não domina toda a variedade de procedimentos odontológicos, mas já está lidando com o lixamento preciso dos dentes para a posterior instalação de coroas. Pelo menos é o que afirmam representantes da startup americana Perceptive, que propôs uma máquina robótica controlada por inteligência artificial, que pela primeira vez no mundo tratou os dentes de um paciente sem a participação de um médico vivo. Sim, primeiro é necessária a participação de um especialista certificado para escanear manualmente os maxilares do paciente com um tomógrafo de coerência óptica para identificar áreas afetadas por cárie (com precisão de posicionamento de cerca de 20% e probabilidade de detecção superior a 90%) e traçar um plano de operação. E então a IA assume o controle: ela prevê com precisão como o formato de cada dente mudará após a lima necessária – e assim a produção da coroa começa imediatamente, o que economiza ainda mais tempo. Um paciente que vem para uma consulta de acompanhamento (após o exame) passa literalmente de 5 a 15 minutos em uma cadeira, e não algumas horas, como de costume – e mesmo que sua cabeça se mova durante o procedimento, a máquina controlada por IA irá rastreie e compense esse movimento a tempo, para que a pessoa não se machuque. Em seguida, tudo o que resta é cimentar as coroas nos dentes recém-limados que correspondam exatamente ao seu formato, e o trabalho estará feito. Eu me pergunto como será a competição pelas faculdades de odontologia nas universidades médicas daqui a cinco anos?
E os dentistas? Até os detetives da polícia podem se encontrar em uma situação de competição com a inteligência artificial num futuro próximo! Pelo menos na Argentina: o seu presidente Javier Milei, conhecido pela sua excentricidade, criou todo um departamento para o uso da IA no domínio da segurança pública. Espera-se que as ferramentas de aprendizagem automática permitam analisar arquivos criminais acumulados ao longo de décadas, a fim de aprender como prever crimes futuros. Além disso, a IA será utilizada para identificar (através da identificação facial) criminosos procurados em locais públicos, para “patrulhar” redes sociais e para analisar em tempo real fluxos de dados de câmaras CCTV – a fim de identificar imediatamente atividades suspeitas que recaiam sobre eles e tomar medidas preventivas. ação imediata.
Outra categoria vulnerável de trabalhadores vivos são os dubladores (na terminologia japonesa – dubladores), e não aqueles que se especializam em desenhos animados ou filmes em língua estrangeira, mas aqueles que falam, gritam, riem maldosamente e às vezes até cantam para personagens de jogos de computador. A Reuters relata um protesto ocorrido em frente ao escritório da Warner Bros. no início de agosto. Games in California, uma greve de dubladores gamers, insatisfeitos com o fato de que modelos generativos modernos, capazes de gerar uma voz humana quase indistinguível, em breve os deixarão completamente sem trabalho. Além disso, o que é mais ofensivo é que tais modelos sejam treinados (como afirmam os grevistas) em amostras, em particular, das suas próprias vozes, retiradas simplesmente dos jogos que anteriormente expressaram sem permissão directa e explícita – e sem qualquer compensação.
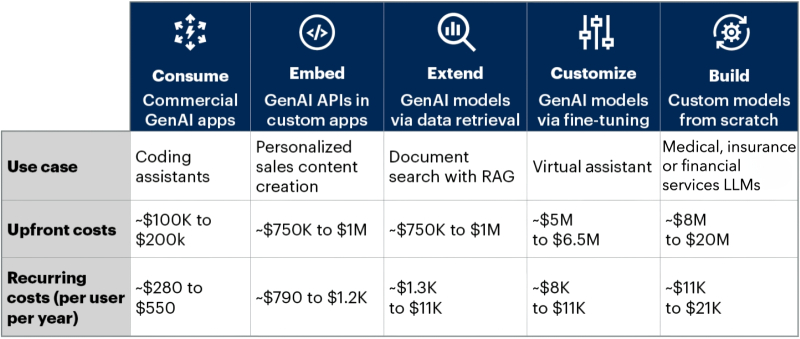
Uma placa modesta com estimativas de custos que pode adicionar cabelos grisalhos aos cabelos de qualquer diretor financeiro de qualquer empresa respeitável que planeje implementar IA em seus processos de negócios (fonte: Gartner)
⇡#O hype vai embora, mas a IA fica?
O entusiasmo pela informação em torno da inteligência artificial já dura quase dois anos, quase sem diminuir, o que é extremamente atípico em relação à experiência de tópicos “quentes” anteriores na indústria de IA – o metaverso, blockchain, nuvens, etc. O clima dos mercados financeiros está em algum lugar no verão de 2024, as coisas começaram a mudar: em agosto, o preço das ações de empresas ocidentais na área de IA caiu 15% em relação aos máximos alcançados apenas em julho. Embora dezenas de bilhões de dólares tenham sido gastos treinando grandes modelos de linguagem e subsequentemente criando ferramentas de negócios baseadas neles, não houve nada como a explosão na eficiência operacional que acompanha a implementação de tais ferramentas. Estatísticas áridas mostram que apenas 4,8% das empresas americanas realmente utilizam IA no seu trabalho diário para produzir bens e prestar serviços, e este não é apenas um valor baixo em si, é também inferior ao registado no início do ano em curso. anos (5,4%).
Os analistas da Gartner apontam para a intensidade de capital excessivamente elevada da IA: para introduzir ferramentas de IA potencialmente úteis nos processos de negócio de uma empresa, são necessários custos de centenas de milhares e milhões de dólares. Além disso, aos investimentos iniciais (de capital) deste tipo, é necessário adicionar despesas operacionais consideráveis - às vezes chegando a muitas centenas, e mais frequentemente a milhares e até dezenas de milhares de dólares por cliente anualmente. É claro que, para compensar custos tão generosos, a IA deve proporcionar às empresas que a implementaram alguns super-lucros incríveis, o que actualmente não é observado em quase nenhum sector da economia. Sim, os chatbots inteligentes e outras ferramentas baseadas em modelos generativos simplificam a vida e poupam tempo a muitos trabalhadores de colarinho branco e, em alguns locais, levam a reduções significativas nos salários, deixando sem trabalho especialistas aparentemente insubstituíveis, mas até agora a escala destas mudanças é precisamente em termos financeiros são extremamente insignificantes. Enquanto os custos, pelo contrário, são surpreendentemente elevados.
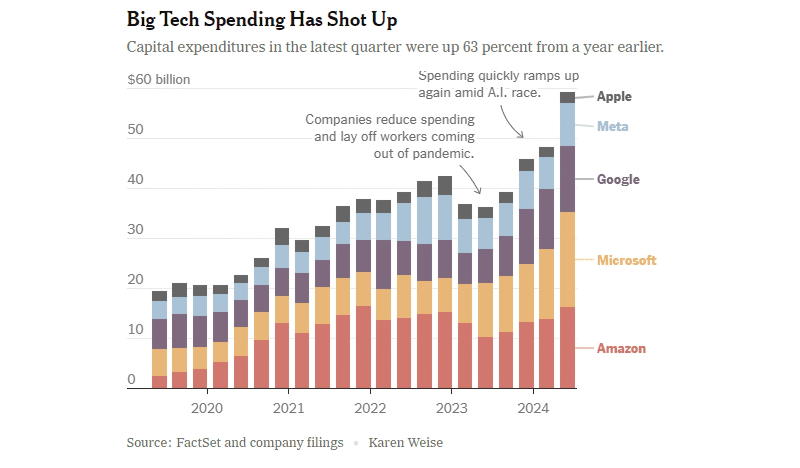
As despesas de capital estão a crescer devido à IA em quase todos os gigantes mundiais de TI – excepto na Apple, que ainda não está (sabiamente?) a desenvolver os seus próprios sistemas deste tipo (fonte: New York Times)
⇡#Dinheiro à parte
À medida que o investimento em IA diminui em todo o mundo, a concorrência neste domínio de utilização intensiva de recursos intensifica-se – e antigos aliados estão subitamente a tornar-se rivais. Foi exatamente o que aconteceu no início de agosto com a Microsoft e a OpenAI – a primeira, no seu próximo relatório anual, reconheceu a segunda como concorrente na área de desenvolvimento de IA, juntamente com Amazon, Apple, Google e Meta*, anteriormente indicadas neste estado. Ao mesmo tempo, a OpenAI continua a ser um parceiro de longo prazo da Microsoft, recebendo dela capacidade de servidor na nuvem Azure e, por sua vez, fornecendo os modelos de IA da empresa Redmond criados por ela para promoção nos mercados comerciais e de consumo. Observe que esse tipo de cooperação não é novidade para a indústria de TI – basta lembrar quanto tempo a Apple confiou no hardware Samsung (e especialmente nas matrizes de tela) para seus smartphones, nunca parando de lutar ferozmente com ela pela primazia no fornecimento global desses gadgets.
Os analistas da Bloomberg mostraram-se geralmente bastante céticos em relação aos resultados preliminares do próximo trimestre: segundo as suas informações, o segundo trimestre. demonstrou um ligeiro declínio no desempenho financeiro dos principais players do segmento de IA, enquanto a economia norte-americana de empresas fora deste setor apenas começou a crescer, pode-se dizer, apresentando uma dinâmica positiva pela primeira vez desde o final de 2022. Assim, para as empresas do índice S&P 500 (com exceção dos “sete magníficos” gigantes de TI), os lucros aumentaram em média 7,4%. Em muitos casos, estes sete não corresponderam às expectativas dos analistas – mesmo que as receitas reais recebidas se revelassem boas, muitas vezes não correspondiam às previsões para o trimestre actual. Isso significa que os investidores inevitavelmente começam a economizar em novos investimentos no setor de IA – afinal, eles não proporcionam mais o rápido retorno financeiro pelo qual os últimos quase dois anos foram famosos. E os gigantes das TI precisam realmente de dinheiro: no último trimestre, as despesas de capital da Apple, Amazon, Meta*, Microsoft e Alphabet totalizaram 59 mil milhões de dólares, 63% mais do que no ano anterior, com uma parte significativa destes fundos destinada à construção e equipamento de novos data centers para tarefas de IA.
A escassez de recursos financeiros disponíveis para desenvolvedores de IA, porém, ainda não afetou quem cria ferramentas de hardware para eles – e, principalmente, a Nvidia. Sim, a capitalização da empresa caiu sensivelmente após os picos de julho, mas para uma planta de produção com os pés no chão, o que importa não é o indicador de capitalização instantânea, mas o volume de investimentos de longo prazo feitos sistematicamente ao longo de anos e décadas – e nesse sentido, as coisas estão indo muito bem para o designer de chips gráficos americano, nada mal. É verdade que eles têm que trabalhar com o suor da testa – no sentido mais literal: embora muitos funcionários da Nvidia tenham se tornado milionários em dólares nos últimos anos, até meses, isso não os livrou da necessidade de trabalhar exaustivamente, sacrificando férias e fins de semana. , nem mesmo tendo a oportunidade de realmente gastar os valores acumulados em entretenimento e recreação. Nas suas próprias palavras, o responsável da empresa prefere não despedir os seus colaboradores se estes tiverem algum potencial, mas “torturá-los até se tornarem grandes” – citando o facto de que “criar algo inusitado não deve ser fácil”. No entanto, a julgar pelos resultados demonstrados pela Nvidia, este tipo de cultura corporativa é plenamente justificado.

O novo modelo atende ao texto – fique atento (fonte: geração de IA baseada no modelo FLUX.1)
⇡#Estabilidade – não no fluxo
Para todos os fãs de IA generativa disponível gratuitamente e executável localmente para converter pistas de texto em imagens, agosto de 2024 foi um mês verdadeiramente quente. Atuando formalmente como uma empresa iniciante, a Black Forest Labs (na verdade, composta por veteranos experientes neste tipo de desenvolvimento, uma parte considerável dos quais trabalhou até recentemente na Stability AI em modelos de Difusão Estável) apresentou seu primeiro desenvolvimento para geração de imagens baseadas em prompts – FLUXO.1. Escondida em seu próprio nome, aparentemente, está a ironia dos ex-funcionários em relação ao seu antigo empregador: flux pode ser traduzido do inglês como “fluxo”, “movimento contínuo”, até mesmo “vibração” – isto é, tudo menos “estabilidade” .
Este modelo está disponível – claramente não o último, a julgar pela unidade promissora em seu nome – em três versões ao mesmo tempo: [pro] – para execução comercial via API em diversos sites parceiros; [dev] – com capacidades um pouco mais modestas, mas disponível para download e execução em um PC (executando Windows, macOS ou sistema operacional com kernel Linux), e também essencialmente leve até o limite [schnell] – para computadores muito fracos e/ou usuários excessivamente impacientes. O FLUX.1 já está sendo chamado de “o que o SD3 deveria ter sido” se não tivesse sido lançado, cortado tão apressadamente e sem sucesso. Sim, o novo produto também não está isento de deficiências – desde as altíssimas demandas de hardware para qualquer execução rápida até ideias extremamente superficiais sobre a aparência das celebridades. Mas tudo isso pode ser corrigido através do LoRA – e os entusiastas já começaram a fazer treinamento adicional amador em seu modelo favorito.
«“Amado” não é um exagero: ao contrário do Stable Diffusion 3, a última criação do Stability AI, cujo benefício também aconteceu neste verão, o FLUX.1 foi saudado pelos fãs do desenho de IA com mais do que entusiasmo. Qualidade brilhante de reprodução do texto citado a partir de uma dica de ferramenta em uma imagem gerada (de palavras individuais a pequenos parágrafos!); imperfeito, mas uma cabeça e meia superior às capacidades dos modelos SD de todas as gerações, a representação de mãos humanas; adesão bastante precisa a um prompt composto corretamente, que permite criar composições e cenas bastante complexas de várias figuras; por fim, a ausência de problemas com meninas deitadas na grama – tudo isso garantiu o acolhimento mais cordial ao novo produto. Também começamos a testá-lo e em breve ofereceremos aos leitores do avalanche noticias IT Drawing Workshop novo material – com FLUX.1 no papel principal.
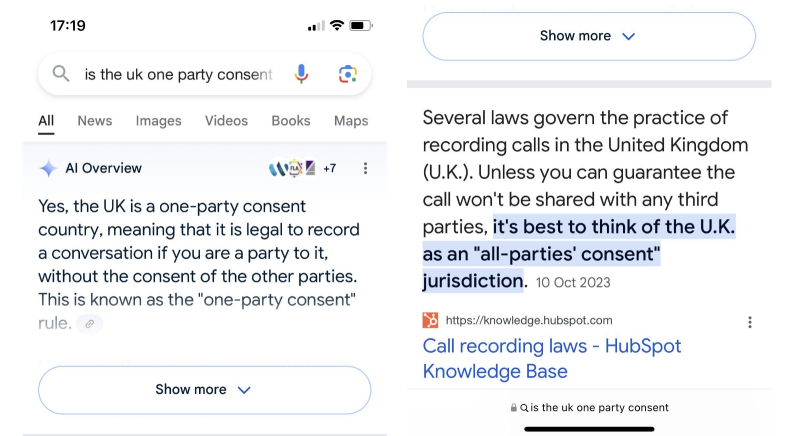
Para uma pergunta geralmente simples – a lei do Reino Unido exige o consentimento prévio de todos os participantes de uma conversa telefônica para gravá-la – a AI Overviews, mesmo em agosto, continua a dar uma resposta incorreta, refutada pelo primeiro link fornecido pelo próprio mecanismo de busca (fonte: Reddit)
⇡#Ameaça corporativa
A IA, que ameaça reduzir a necessidade do mercado de pessoas em determinadas profissões ou mesmo deslocar completamente os humanos de algumas áreas de actividade, é uma história de terror de uma idade bastante respeitável; num futuro próximo, é improvável que ameace ser totalmente cumprido, mas já é familiar e habitual há muito tempo. No entanto, em Agosto, começaram a aparecer relatórios sobre a ameaça que os modelos generativos representam não para profissões individuais, mas para as empresas como um todo – mais precisamente, para o volume dos seus rendimentos associados à sua presença na Internet. E esses volumes podem ser bastante grandes: se um determinado site aparece frequentemente nos resultados dos motores de busca para consultas especializadas (e especialmente no caso em que isso acontece devido ao seu conteúdo “nativo”, e não a links de marketing pagos com uma marca apropriada), o reconhecimento dos associados Com esse site, a marca está crescendo significativamente. Assim, as empresas que muitas vezes aparecem na primeira página dos resultados de pesquisa de um gigante das buscas como o Google – e a grande maioria dos usuários que recorrem a ele em busca de algum tipo de informação não olham além da primeira página – sentem um material direto e óbvio retorno de um posicionamento tão lucrativo.
Mais precisamente, eles sentiram isso até que o Google começou a acompanhar massivamente os resultados da pesquisa com recomendações de visões gerais de IA, que são exibidas no topo da página de resultados. Um bot “inteligente” procura rapidamente pelo autor da solicitação os sites que estão localizados nas primeiras linhas dos resultados da pesquisa e, em questão de segundos, formula um resumo inteligível, claro e organizado das informações ali apresentadas sobre o tema de interesse ao usuário. Sim, claro, links para sites onde dados específicos foram obtidos são fornecidos após a resposta do bot de IA, mas quantos se darão ao trabalho de clicar neles para esclarecer e, talvez, obter uma compreensão mais profunda das informações que lhes são trazidas pelo modelo generativo?
Os proprietários de sites preocupados notaram imediatamente – apesar do fato de a Visão Geral da IA não estar ativada para todas as solicitações de pesquisa e até agora em um número limitado de países – que o uso de uma nova ferramenta do gigante de TI reduziu significativamente o número de transições da página de pesquisa , para o qual os proprietários das empresas correspondentes estavam acostumados a não poupar despesas com otimização de SEO. Pior ainda, as alucinações do “AI Observer” que atormentavam (mas também divertiam) os usuários desde o final da primavera, em geral, não desapareceram, embora tenham começado a se manifestar com muito menos frequência. Aparentemente, o bot “inteligente” do mecanismo de busca do Google ainda presta um péssimo serviço tanto aos usuários não críticos quanto aos proprietários respeitáveis de sites com informações que são realmente procuradas pelas pessoas. Além disso, se o proprietário de um site, indignado com o AI Overview em seu estado atual, quiser bloquear o acesso desta ferramenta aos seus dados, ele automaticamente reduzirá drasticamente o tráfego para seu recurso – já que o Googlebot, principal rastreador do mecanismo de busca, coleta informações para visões gerais de IA e para o mecanismo de pesquisa clássico.
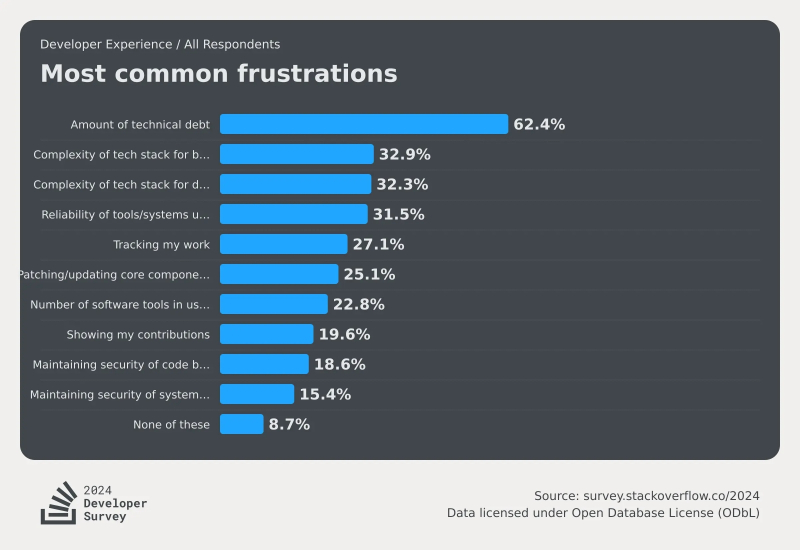
Como você pode ver, a IA nem está entre os dez principais problemas que realmente incomodam os programadores hoje (fonte: Stack Overflow)
⇡#Os modelos generativos sonham com codificadores elétricos?
Embora ninguém pareça estar a planear substituir completamente os programadores vivos pela inteligência artificial, a difusão generalizada da IA está a mudar visivelmente as condições neste segmento do mercado de trabalho. A Microsoft, por exemplo, pretende parar de contratar programadores que não dependem de bots inteligentes em suas atividades diárias. Nada pessoal, só que a eficácia dos modelos generativos em termos de identificação de erros e escrita de código é tão grande – ou melhor, quão grande é o entusiasmo pela “codificação de IA” por parte de startups e corporações de TI como a mesma Microsoft, Amazon, Google – esses tradicionalistas musgosos Os grandes empregadores não querem permitir que as pessoas entrem em suas salas de programação. O argumento financeiro também é importante: se os assistentes de codificação de IA estiverem envolvidos no trabalho dos programadores, é muito mais fácil responder com alta precisão à principal questão que preocupa qualquer CFO dia e noite: “Qual é a hora de lucrar e como significativo é esse lucro?”
No entanto, os próprios programadores de IA não têm medo – pelo menos isso é evidenciado pelo último estudo anual realizado pela Stack Overflow (geralmente começa em maio, os resultados são conhecidos no final de julho), que acumulou as opiniões de mais de 65 mil frequentadores deste site de codificação mundialmente famoso. Pela primeira vez, o tema da inteligência artificial apareceu no questionário de 2024 – precisamente no contexto de saber se os programadores a percebem como uma ameaça à sua posição no trabalho, às suas perspectivas e ao seu modo de vida geral. E descobriu-se que a parcela de codificadores que têm de alguma forma medo do impacto negativo da IA não excede 12% – isso é menos do que a porcentagem daqueles que têm medo de demonstrar aberta e honestamente sua contribuição para o projeto todas as vezes após a conclusão. trabalho no grupo: eram quase 20%.
Pelo contrário, 70% dos inquiridos não são avessos à utilização de ferramentas de IA nas várias fases do seu desenvolvimento; Além disso, 81% daqueles que já os utilizam consideram sua propriedade mais útil um aumento notável na produtividade, e 62% – a capacidade de aprender rapidamente novas técnicas e habilidades (ou seja, aquelas que estavam inicialmente ausentes do conjunto de dados de treinamento do “inteligente ” sistema ). A única coisa que esfria um pouco o ardor dos apologistas da inteligência artificial é a avaliação bastante baixa da exatidão dos conselhos que dão – apenas 30% dos entrevistados admitiram que a precisão do código que produziram aumentou após o uso de ferramentas de IA. No entanto, mesmo que os fragmentos de código oferecidos pelos bots “inteligentes” nem sempre sejam perfeitos, não é difícil obtê-los rapidamente, para quase qualquer problema, em diversas linguagens de programação – o que obviamente justifica a necessidade de posterior captura cuidadosa. de pulgas. Que, aliás, também pode ser, pelo menos parcialmente, confiada à inteligência artificial.
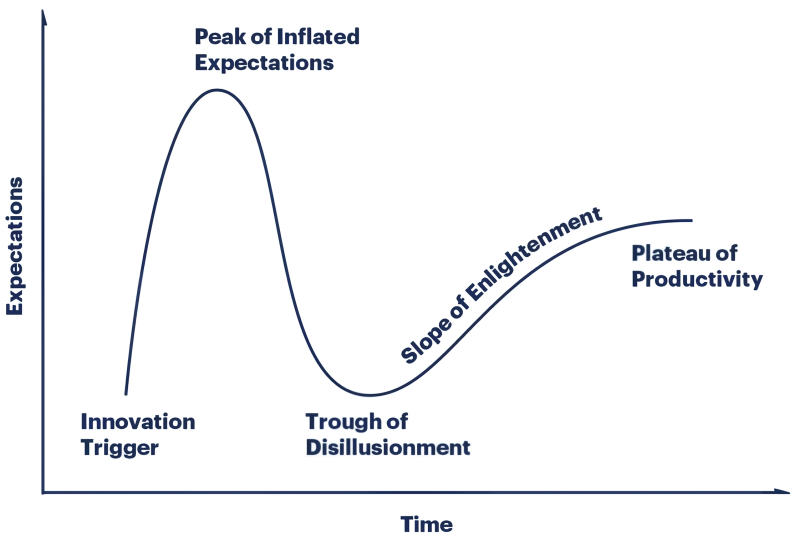
O clássico ciclo de reconhecimento da inovação, ciclo de hype do Gartner, como a dependência das expectativas geradas por uma nova tecnologia expressa em unidades convencionais no tempo (fonte: Gartner)
⇡#Fique na linha, suas expectativas são muito importantes para nós
À medida que os modelos generativos de IA perdem o encanto da novidade e se tornam uma ferramenta de trabalho a partir de uma curiosidade surpreendente, tanto os desenvolvedores como os utilizadores estão cada vez mais conscientes das suas limitações fundamentais – que, em essência, se resumem à possibilidade de escolher uma determinada entidade (ou conjunto de entidades, inclusive mutuamente acordadas) a partir de uma gama extremamente extensa de dados. É claro que não estamos falando de qualquer “inteligência” no sentido filosófico deste termo quando aplicado a modelos generativos, e muitos pesquisadores claramente não estão satisfeitos com este estado de coisas. No entanto, existe, em princípio, uma chance de um dia construir uma inteligência artificial forte (AGI, que nos círculos de língua inglesa é geralmente chamada de “geral”, Artificial General Intelligence – AGI), se a quantidade de energia e dados necessários para treinar mesmo os atuais grandes modelos de linguagem já são incríveis?
Segundo analistas do Gartner, a humanidade ainda tem chance de criar AGI, mas não antes de dez anos. A tarefa é significativamente complicada pela extrema incerteza do próprio conceito AGI e pela enorme intensidade de recursos da inteligência artificial generativa – afinal, ela, manifestando-se cada vez mais claramente como um ramo secundário do desenvolvimento, e não como um caminho principal para Uma IA forte, cada watt de electricidade e cada dólar gasto no seu desenvolvimento, retira, ao que parece, do futuro SII. Para fazer pelo menos uma avaliação aproximada das perspectivas de uma indústria atualmente desconhecida, especialistas aplicaram métodos de análise matemática a mais de 2 mil tecnologias significativas para a humanidade – e, com base nos padrões identificados, tiraram uma série de conclusões sobre as perspectivas de diversas áreas da inteligência artificial nos próximos 2 a 10 anos.
Para começar, algumas notícias decepcionantes para os fãs da IA generativa: esta tecnologia, segundo Garnter, está perto do sinistro “vale da desilusão” – no famoso diagrama que há muito se tornou o cartão de visita desta empresa de pesquisa. E não é que os modelos generativos sejam maus, é apenas que nesta fase as expectativas (principalmente dos investidores, que estão constantemente a pensar onde investir o seu dinheiro de forma mais lucrativa) começam a ficar claramente aquém do que é realmente alcançável – não apenas demonstrado no momento, mas em princípio alcançável – os resultados do trabalho dos modelos de IA. Ao longo do último ano e meio, essas expectativas foram ativamente elevadas – e a inevitável recuperação pode se transformar em um choque bastante sério para todo o segmento de inteligência artificial generativa, provocado por uma saída repentina de grandes investimentos.
Quanto ao FII, segundo analistas, ele ainda está subindo ao pico das expectativas inflacionadas – e atingirá o nível de entusiasmo que acompanhou os modelos generativos no último ano e meio a dois anos, não antes de dez anos. Sobre que princípios será construído, que tipo de hardware será necessário para executá-lo, que software sofisticado será necessário para trabalhar com ele e sobre ele – todas estas são questões aplicadas às quais a análise estatística realizada por Garnter não pode, em princípio, dê respostas. Ao mesmo tempo, é claro que depois que os modelos generativos forem jogados na “terra da separação das ilusões” e antes que apareçam os primeiros tímidos indícios da implementação prática da AGI, o campo da inteligência artificial em geral e do aprendizado de máquina em particular irá certamente enfrentarão momentos difíceis.

Bem, a esperada geração de IA tolerante e segura para o pedido “típicos camponeses russos fazendo coisas típicas de camponeses russos”; basta olhar o equilíbrio das cores e os ponteiros… ah, não, desculpe: esta é uma cena real da série americana “The Great” (ok, ok – uma série de comédia) da plataforma Hulu, que fala sobre o jovem anos de Catarina II! (Fonte: Hulu)
⇡#Inteligência em um caso
Apesar de todas as vantagens da inteligência artificial, o seu lançamento generalizado, como dizem, nas pessoas está repleto – pelo menos no seu estado actual – de constrangimentos de vários graus de gravidade, desde alucinações extremamente convincentes até causar sofrimento moral insuportável a representantes de vários grupos vulneráveis da população. Isso, é claro, não pode ser permitido e, portanto, os principais desenvolvedores de IA – começando até agora com OpenAI e Anthropic – total e completamente voluntariamente, na ausência de qualquer pressão externa, concordaram em fornecer ao governo americano acesso ao seu mais novo NLM ( sem dúvida, a abreviatura LLM – modelo de linguagem grande – muito mais harmoniosa, mas aqui, como nos parece, é mais apropriado falar especificamente sobre o BML) tanto antes de serem colocados em circulação pública como depois. Bem, você nunca sabe o que acontece.
Isso está sendo feito, é claro, apenas para “fortalecer a segurança”, para o qual ambos os desenvolvedores (até agora dois – mas, presumivelmente, outros os seguirão rapidamente) assinaram um memorando de entendimento com o Instituto Americano para Segurança de IA em o final de agosto. No comunicado emitido após este evento, a agência observa com satisfação que a medida razoável tomada pelos desenvolvedores responsáveis garantirá uma avaliação abrangente – juntamente com a OpenAI e a Anthropic, e ao mesmo tempo com o envolvimento do Instituto Britânico para Segurança de IA – dos potenciais riscos de segurança e permitirá a eliminação atempada de todas as possíveis ameaças a essa segurança. De acordo com Elizabeth Kelly, chefe do Instituto Americano para Segurança de IA, a segurança é a chave para a prosperidade de inovações tecnológicas revolucionárias (em algum lugar em resposta, as sombras dos inventores de lançadores de lanças, dinamite, desfolhantes e outras tecnologias inovadoras e revolucionárias de seu tempo concordou com a cabeça): “Esses acordos [assinados pela OpenAI e pela Anthropic] são apenas o começo; Serão certamente um marco importante no caminho que escolhemos para gerir de forma responsável o futuro da inteligência artificial.”
A Califórnia, por ser o estado mais avançado em termos de inovações tecnológicas (e outras), e neste caso esteve um pouco à frente da locomotiva da legislação federal, tendo adotado um polêmico, segundo especialistas cautelosos, projeto de lei sobre a segurança da inteligência artificial, que envolve a introdução de um “interruptor de morte” no modelo de IA – kill switch. Apoiado por ambas as câmaras do Legislativo estadual, o projeto aguarda agora a assinatura do governador (notório democrata Gavin Newsom) para entrar em vigor. A essência da iniciativa é obrigar os desenvolvedores de modelos de IA a integrarem neles a notória mudança, que permitiria parar o sistema “se começar a criar novas ameaças à segurança pública; especialmente numa situação em que o referido modelo opera sob controle, intervenção ou supervisão humana limitada.” E embora um grupo de líderes empresariais da Califórnia já tenha escrito uma carta aberta a Newsom, instando-o a vetar o projeto de lei “fundamentalmente falho”, que “criaria custos de conformidade onerosos” e “suprimiria o ritmo de investimento e inovação devido à incerteza regulatória, ” Não é verdade que as vozes dos manifestantes serão ouvidas. Afinal de contas, neste momento o entusiasmo em torno da IA começou a diminuir um pouco – e quando mais as inovações progressivas poderão ser tomadas pelas rédeas e travadas em nome da segurança, senão quando perderem o seu ímpeto ascendente?
________________
* Incluído na lista de associações públicas e organizações religiosas em relação às quais o tribunal decidiu liquidar ou proibir atividades que tenham entrado em vigor pelos motivos previstos na Lei Federal de 25 de julho de 2002 nº 114-FZ “ Sobre o Combate às Atividades Extremistas”