
No verão passado, AMD, Arista, Broadcom, Cisco, Eviden/Atos, HPE, Intel, Meta✴ e Microsoft formaram o Ultra Ethernet Consortium (UEC), projetado para competir com a tecnologia InfiniBand, que a NVIDIA essencialmente controla apenas após a compra da Mellanox, e padronizar Ethernet- soluções para plataformas modernas de IA e HPC. E agora AMD, Broadcom, Cisco, Google, HPE, Intel, Meta✴ e Microsoft formaram a aliança Ultra Accelerator Link (UALink), que deverá competir com o NVLink.
Ao longo de um ano, mais cinquenta empresas aderiram à UEC, exceto, é claro, a NVIDIA, que, no entanto, também não se esquece da Ethernet, embora receba periodicamente críticas da Broadcom. A única alternativa na construção de fábricas para clusters mais ou menos grandes continua sendo o Omni-Path Express, desenvolvido pela Cornelis Networks, que também aderiu à UEC, mas a participação dessa tecnologia em comparação com Ethernet e InfiniBand é pequena. Além disso, nenhuma dessas tecnologias pode oferecer o que o NVIDIA NVLink pode oferecer – a capacidade de conectar diretamente centenas de aceleradores (mais precisamente, sua memória) com uma conexão ultrarrápida e de baixa latência.
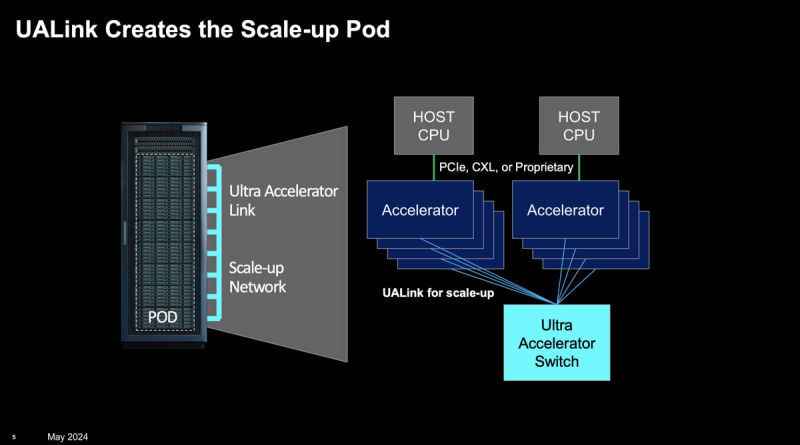
Fonte da imagem: UALink via ServeTheHome
O NVLink 4 atingiu velocidades de 900 GB/s por acelerador e pela primeira vez foi além do nó, permitindo que até 256 aceleradores fossem combinados em um domínio, que a NVIDIA ofereceu como parte do DGX SuperPod H100. O NVLink 5 dobra a taxa de transferência para 1,8 TB/s e, teoricamente, permitirá que até 576 aceleradores sejam combinados em um único domínio. Foi o NVLink que possibilitou a criação dos superaceleradores de alta densidade GH200 NVL32 e GB200 NVL72. E são estes que a NVIDIA considera ser a unidade mínima efetiva de clusters num futuro próximo, oferecendo aos grandes clientes a possibilidade de não trocarem por menos.

A família Gaudi da Intel usa Ethernet (1,2 TB/s por acelerador) para escalabilidade vertical e horizontal. A AMD depende do Infinity Fabric (896 GB/s por acelerador) baseado em PCIe e xGMI, que até recentemente não ia além do nó. Porém, no final de 2023, foi anunciado que em 2025 a AMD e a Broadcom lançariam um switch baseado em PCIe 7.0 (o padrão só está previsto para ser aprovado este ano), que suportará a tecnologia, que agora se chama AFL (Accelerated Fabric Link) – esta será a saída do Infinity Fabric fora do nó.

E são os desenvolvimentos conjuntos que a AMD e a Broadcom compartilharão no âmbito do UALink. A aliança promete apresentar a primeira versão da nova interconexão no terceiro trimestre de 2024, e a versão 1.1 no quarto trimestre. Porém, ainda não está definido diretamente se o transporte principal será PCIe ou Ethernet, e qual protocolo será utilizado para trabalhar com memória. Mas já foi prometido que o UALink 1.0 permitirá combinar até 1024 aceleradores em um domínio com a possibilidade de solicitações diretas de carregamento/armazenamento para sua memória. Para maior dimensionamento de clusters, ainda é proposto o uso de Ultra Ethernet.

Ao mesmo tempo, o UALink, a rigor, não promete a possibilidade de comunicação desimpedida entre aceleradores de diferentes fornecedores, mas permite simplificar a infraestrutura e barateá-la pela abertura e concorrência. Embora fosse bom ver o UALink como base de hardware para o padrão UXL, que pretende competir com o NVIDIA CUDA. Quanto ao CXL, este padrão, que também utiliza PCIe como transporte, provavelmente permanecerá “amarrado” à CPU e às comunicações intra-nó, embora suas capacidades sejam muito mais amplas.