
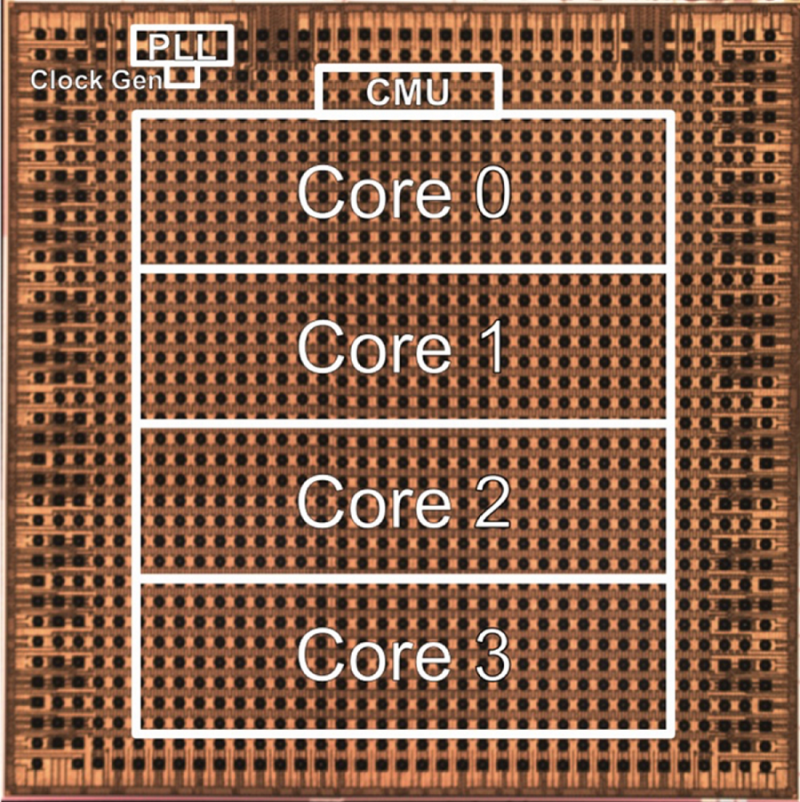
Os populares núcleos de computação, processadores e SoCs voltados para o mercado de aprendizado de máquina tendem a usar modos de computação de bits inferiores, como FP16 ou mesmo INT8.
Mas para a implementação de sistemas de treinamento e inferência na periferia, até mesmo a precisão de oito bits pode ser excessiva, mas a eficiência continua sendo um fator chave. A IBM revelou alguns detalhes sobre seu novo chip AI projetado especificamente para sistemas periféricos.
Nos últimos anos, tem havido um desenvolvimento da chamada computação de borda, em que o processamento primário de um fluxo de dados “brutos” é realizado diretamente nos locais onde são recebidos, ou mais próximo desses locais. Ao contrário do processamento clássico em um data center, na periferia, recursos como tamanho e fonte de alimentação são limitados, e é por isso que os desenvolvedores estão tentando fazer esses chips e sistemas o mais econômicos e compactos possível.
Entre eles está a IBM, que divulgou informações sobre um novo protótipo de um coprocessador AI projetado especificamente para sistemas de aprendizado de máquina e sistemas de inferência periférica. Segundo fontes, a principal vantagem do novo produto é a capacidade de realizar cálculos com ainda menos alta precisão do que é comum no aprendizado de máquina, mas suficiente para uma série de tarefas.
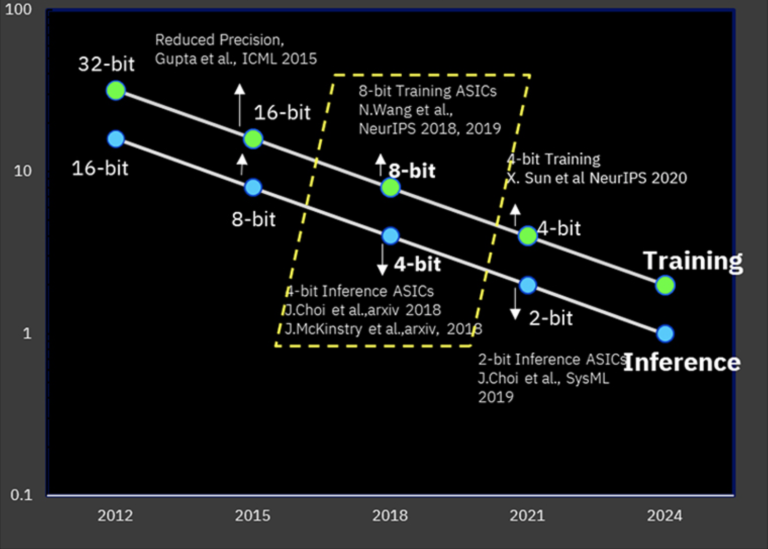
O novo desenvolvimento da IBM é interessante porque fornece precisão de treinamento comparável ao usar formatos de cálculo menos precisos
Inicialmente, o aprendizado de máquina usava núcleos de computação clássicos com uma precisão computacional de pelo menos FP32, mas em alguns casos essa precisão é excessiva e o consumo de energia está longe do ideal. Nesse sentido, nos últimos cinco anos, foi a IBM que avançou significativamente. Já em 2019, a empresa mostrou a possibilidade de usar precisão de ponto flutuante de 8 bits para treinamento, e mesmo 4 bits acabaram sendo suficientes para inferência.
Na conferência NeurIPS 2020, a empresa relatou mais sucessos nesta área: um novo coprocessador AI periférico projetado usando padrões tecnológicos de 7 nm fornece resultados bastante confiáveis ao ensinar no modo de 4 bits e para tarefas de inferência usa um de dois bits. modo. Nesse caso, a precisão é bastante alta, embora em alguns casos diminua vários por cento, mas o desempenho é quase quatro vezes maior do que ao usar o modo de 8 bits. Cálculos de precisão mista também são naturalmente possíveis.
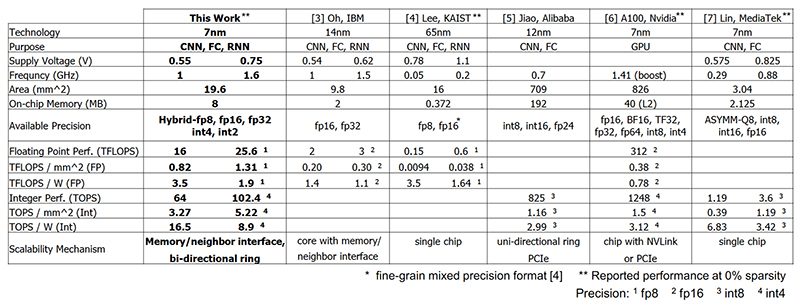
Devido à combinação de precisão reduzida e um processo técnico delicado, alta eficiência energética é fornecida, e a IBM, com bons motivos, acredita que tais processadores irão substituir os clássicos onde suas capacidades são suficientes, por exemplo, em visão de máquina e sistemas de reconhecimento de voz. Além disso, a IBM desenvolveu um novo algoritmo de compactação, ScaleCom, para compactar dados de aprendizado de máquina com muita eficiência. A conversa é sobre a possibilidade de compressão por 100 e, em alguns casos, até 400 vezes. Detalhes podem ser encontrados no site da empresa.