
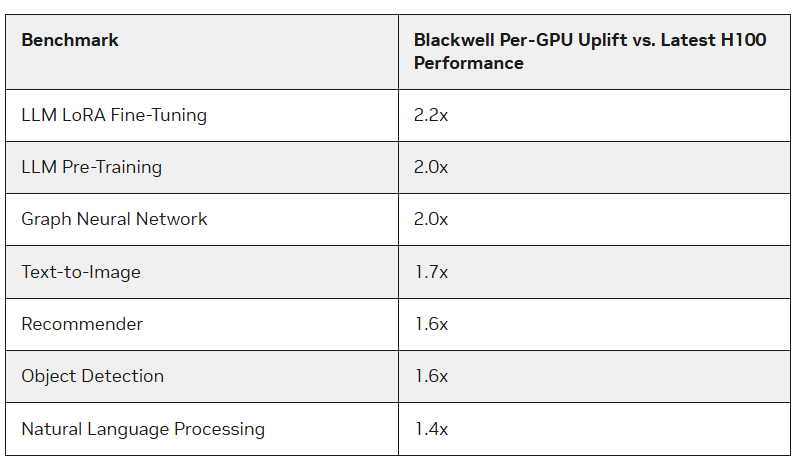
Os aceleradores Blackwell da NVIDIA superaram os chips H100 nos benchmarks MLPerf Training 4.1 em mais de 2,2 vezes, informou o The Register. A maior largura de banda de memória da Blackwell também desempenhou um papel, disse a NVIDIA. Os testes foram realizados usando o supercomputador Nyx da NVIDIA baseado no DGX B200.
Os novos aceleradores têm desempenho de pico aproximadamente 2,27 vezes maior nos cálculos FP8, FP16, BF16 e TF32 do que os sistemas H100 de última geração. O B200 apresentou desempenho 2,2 vezes melhor ao ajustar o modelo Llama 2 70B e duas vezes o desempenho ao pré-treinar o modelo GPT-3 175B. Para sistemas de recomendação e geração de imagens, o aumento foi de 64% e 62%, respectivamente.
A empresa também observou os benefícios da memória HBM3e do B200, que permitiu que o benchmark GPT-3 fosse executado com sucesso em apenas 64 aceleradores Blackwell sem comprometer o desempenho de cada GPU, enquanto 256 aceleradores H100 seriam necessários para alcançar o mesmo resultado. Porém, a empresa também não se esquece do Hopper – na nova rodada, a empresa conseguiu escalar o teste GPT-3 175B para 11.616 aceleradores H100.

Fonte da imagem: NVIDIA
A empresa observou que a plataforma NVIDIA Blackwell oferece um aumento significativo de desempenho em relação à plataforma Hopper, especialmente ao executar o LLM. Ao mesmo tempo, os chips da geração Hopper ainda permanecem relevantes graças às otimizações contínuas de software, às vezes aumentando várias vezes o desempenho em algumas tarefas. A intriga é que desta vez a NVIDIA decidiu não mostrar os resultados do GB200, embora tanto ela quanto seus parceiros possuam tais sistemas.
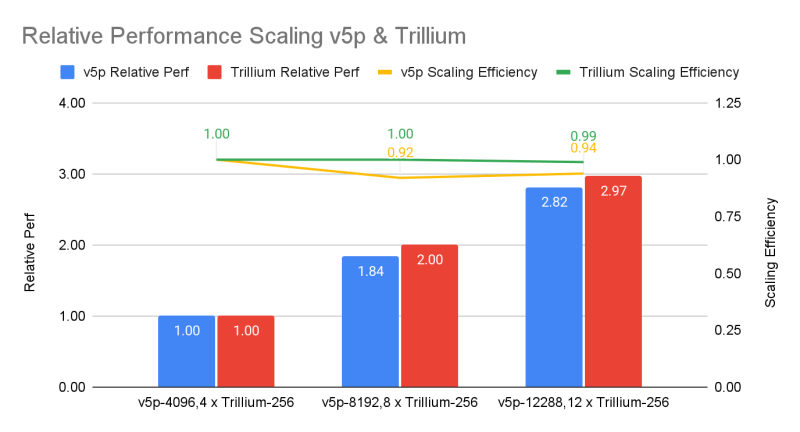
Por sua vez, o Google apresentou a primeira rodada de resultados de testes da TPU de 6ª geração chamada Trillium, cuja disponibilidade foi anunciada no mês passado, e a segunda rodada de resultados dos aceleradores TPU v5p de 5ª geração. Anteriormente, o Google testou apenas o TPU v5e. Comparado com a última opção, o Trillium oferece um ganho de desempenho de 3,8x na tarefa de treinamento GPT-3, observa o IEEE Spectrum.

Se compararmos os resultados com os indicadores da NVIDIA, nem tudo parece tão otimista. O sistema 6.144 TPU v5p atingiu o benchmark de treinamento GPT-3 em 11,77 minutos, atrás do sistema 11.616 H100, que completou a tarefa em aproximadamente 3,44 minutos. Com o mesmo número de aceleradores, as soluções do Google são quase duas vezes mais lentas que as soluções da NVIDIA, e a diferença entre v5p e v6e é inferior a 10%.
Fonte da imagem: Google
No teste de difusão estável, o sistema 1024 TPU v5p ficou em segundo lugar, terminando em 2,44 minutos, enquanto o sistema baseado em NVIDIA H100 do mesmo tamanho completou a tarefa em 1,37 minutos. Em outros testes em clusters de menor escala, a diferença permanece aproximadamente uma vez e meia. No entanto, o Google concentra-se na escalabilidade e na melhor relação preço-desempenho em comparação com as soluções dos concorrentes e com os seus próprios aceleradores de gerações anteriores.
Também na nova rodada do MLPerf apareceu o único resultado da medição do consumo de energia durante o benchmark. Um sistema de oito servidores Dell XE9680, cada um incluindo oito aceleradores NVIDIA H100 e dois processadores Intel Xeon Platinum 8480+ (Sapphire Rapids), consumiu 16,38 mJ de energia na tarefa de ajuste do Llama2 70B, gastando 5,05 minutos no trabalho. — a potência média foi de 54,07 kW.