

O final deste ano foi extremamente gratificante para a indústria de TI e para quem acompanha seu desenvolvimento. A estreia dos chips da série Ryzen 5000, placas gráficas Ampere baseadas em silício da NVIDIA e, mais recentemente, os SoCs móveis da Apple que devem abalar a hierarquia estabelecida no mundo da CPU de consumo – tudo aconteceu literalmente em um ou dois meses. Não vamos nos esquecer dos consoles da próxima geração, que também estão diretamente relacionados às iniciativas da AMD. Estamos testemunhando talvez a temporada mais quente de novos produtos nos últimos anos, tanto em termos de número de eventos quanto em sua importância. Não é à toa que todo ferro avançado instantaneamente se tornou, em um grau ou outro, uma mercadoria escassa.
Até agora, apenas um elemento importante faltou na imagem – as prometidas placas de vídeo Radeon em um grande chip Navi, que, em nossa opinião, merecem um lugar central em uma série de lançamentos de outono. O fato é que desde o confronto entre a Radeon R9 Fury X e a GeForce GTX 980 Ti, a AMD foi realmente eliminada da luta pela coroa de maior desempenho entre as GPUs para jogos. As tentativas de retorno ao ringue, que a fabricante de chips tem feito desde então, foram acompanhadas de promessas generosas, mas a cada vez as esperanças dos adeptos da marca vermelha foram frustradas. No entanto, graças à arquitetura RDNA, a AMD tem todos os pré-requisitos para eliminar o atraso tecnológico do silício NVIDIA e, em alguns aspectos, até assumir uma posição de liderança.
As placas gráficas Radeon série 5000, mesmo que contenham os recursos dos produtos do período de transição, já provaram sua competitividade na categoria de preço médio a médio alto, e agora as ambições da AMD se espalharam novamente para o segmento de preço mais alto. Além disso, estamos falando não apenas sobre a competição dentro da estrutura das métricas de desempenho tradicionais, mas também sobre o retorno da paridade funcional entre o silício NVIDIA e AMD, porque o “Big Navi” também executa o ray tracing acelerado por hardware.
A AMD anunciou três placas de vídeo baseadas no chip Navi 21. Hoje estaremos olhando para dois modelos inferiores – a Radeon RX 6800 e a Radeon RX 6800 XT, que devem estar à venda no momento em que você ler este artigo, a preços sugeridos de 79 e 49, respectivamente. Seus concorrentes diretos dos produtos NVIDIA são óbvios – são GeForce RTX 3070 e RTX 3080, com preços 99 e 99. O modelo principal da família, a Radeon RX 5900 XT, está atrasado até 8 de dezembro e promete desempenho na mesma categoria da GeForce RTX 3090 por um preço adequado de 99 …
A estreia do Radeon RX 6800 e do Radeon RX 6800 XT depende de dispositivos de design de referência que mudaram irreconhecivelmente em comparação com as soluções de referência anteriores e, francamente, sem muito sucesso da AMD, e o aparecimento de versões de parceiros é esperado mais tarde. As placas de vídeo de referência representarão o chip Navi 21 em benchmarks, mas primeiro temos uma discussão detalhada sobre sua arquitetura, que está longe de ser uma simples mudança quantitativa no núcleo RDNA da geração anterior.
Processador geométrico com suporte a Mesh Shaders
A lógica do RDNA 2, embora tenha muitas novidades, não sofreu as mesmas transformações massivas nos princípios da GPU que distanciaram o RDNA 1 da arquitetura Graphics CoreNext que serviu a AMD por quase oito anos desde os dias da Radeon HD 7970 até o lançamento da Radeon 5000 ª série. Analisamos as diferenças entre RDNA e GCN em detalhes em nossa análise do Radeon RX 5700 XT e não vamos nos concentrar nelas hoje, porque o GCN deixou os produtos de consumo AMD (apenas os gráficos integrados dos processadores Ryzen ainda contêm blocos GCN), mas e em soluções do lado do servidor para tarefas, o GP-GPU está prestes a se aposentar e dar lugar à próxima arquitetura CDNA. Em vez disso, vamos dar uma olhada na estrutura do chip do front-end ao back-end do pipeline de renderização, atualizar nosso conhecimento de como o RDNA funciona que permaneceu inalterado e destacar as inovações que distinguem a lógica do Navi 21 do Navi 10 – o cristal que reside no coração do Radeon RX 5600, RX 5700 e RX 5700 XT.
No topo da cadeia estão os processadores de comando para sombreadores e computação de uso geral, o processador de geometria e o agendador de hardware que o Windows aprendeu recentemente a usar. Há também um bloco DMA que serve para acesso direto à memória GPU por meio do barramento PCI Express como parte do trabalho conjunto de vários aceleradores, bem como certas funções inovadoras do Navi 21: Smart Access Memory na plataforma Ryzen 5000 e suporte DirectStorage – vamos dar atenção a eles mais tarde. No entanto, a principal mudança qualitativa no front-end da GPU ainda está relacionada à maneira como o Navi 21 lida com o processamento de geometria.
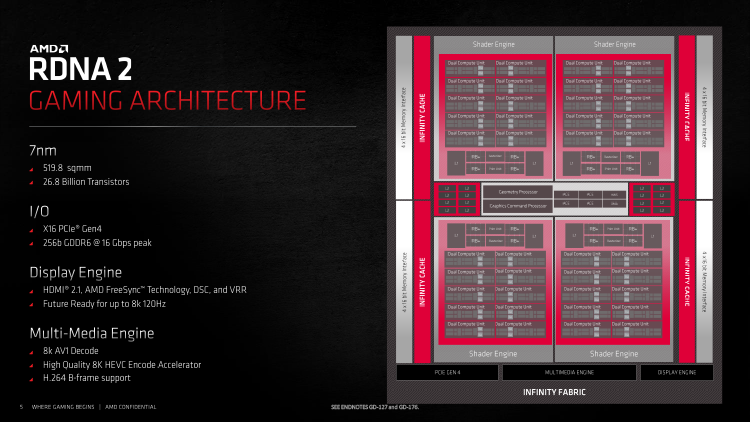
A AMD usa uma topologia distribuída de blocos envolvidos na preparação de primitivas para sombreamento, quando o processador de geometria realiza os estágios gerais de trabalho e a maioria das operações antes e depois do mosaico cai em unidades primitivas localizadas dentro de partições de GPU escaláveis. Embora o processador de geometria na antiga arquitetura GCN esteja intimamente relacionado ao modelo de programação Direct3D, o RDNA aprendeu a truncar triângulos invisíveis nos estágios iniciais de renderização e pode levar até oito primitivos por relógio para enviar quatro para rasterização. A condição para isso é a chamada. Os sombreadores primitivos são programas altamente eficientes que substituem o domínio Direct3D e os sombreadores de geometria no fluxo de trabalho da API gráfica.
Shaders primitivos são usados em dispositivos RDNA no nível do compilador, e a maior parte da computação passa por eles. Além disso, os chips Navi implementam Surface Shaders rápidos, que, de acordo com a decisão do compilador, substituem parte da cadeia de shaders envolvida na tesselação (Vertex Shaders e Hull Shaders) antes que os dados sejam transferidos para o próprio tessellator – um bloco de funcionalidade fixa. As funções descritas, que na terminologia do fabricante de chips são chamadas de NGG (geometria de última geração), substituem as partes problemáticas do pipeline de geometria inerente ao Direct3D, recodificando o antigo tipo de sombreador em um novo instantaneamente e, assim, executam o trabalho antigo de maneira mais eficiente sem a necessidade de suporte explícito dos desenvolvedores aplicações gráficas.
No entanto, é impossível esconder o fato de que a proporção entre o poder do front-end geométrico e os recursos escalonáveis da GPU, que são usados para texturização e operação de kernels de shader, que é normal para o chip Navi 10, não mudou para melhor. A GPU Navi 21 com o dobro do array de ALUs shader ainda é forçada a se contentar com quatro primitivos filtrados invisíveis. Felizmente, além das otimizações introduzidas no RDNA de primeira geração, o Navi 21 pode tirar proveito de um modelo de programação de geometria completamente novo – Mesh Shaders. Shaders desse tipo foram implementados pela primeira vez em GPUs NVIDIA Turing, mas depois se tornaram um padrão da indústria e se tornaram parte dos requisitos de hardware que o DirectX 12 Ultimate (nível de recurso 12_2) estabelece.
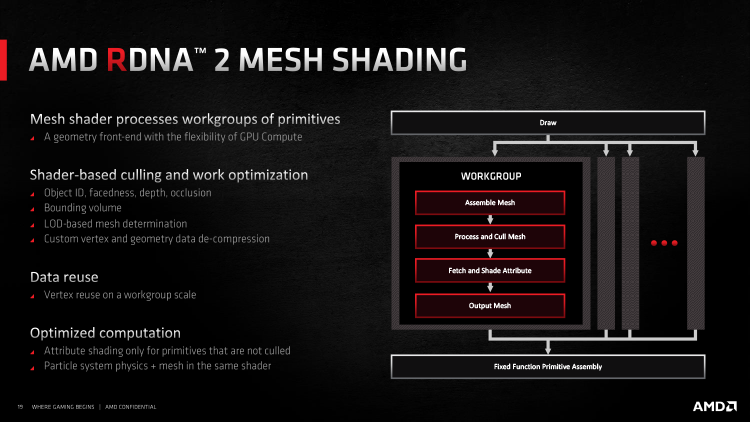
Nas versões anteriores do Direct3D, a malha de um objeto na cena é calculada em sua totalidade: todos os números do buffer de índice que determina a posição dos vértices são considerados em ordem sequencial. Assim, a carga nos estágios iniciais do pipeline de renderização aumenta linearmente com a complexidade geométrica da cena. O modelo Mesh Shaders paraleliza essa tarefa dividindo a malha em malhas, cada uma das quais é tratada por um grupo separado de fluxos de instrução. Os sombreadores de amplificação andam de mãos dadas com os sombreadores de malha, que determinam quantos grupos de instruções serão executados e fornecem os dados necessários. Como o nome desta etapa de renderização sugere, os amplificadores sombreadores permitem que a geometria seja propagada em tempo real, duplicando malhas poligonais rapidamente – algo que a NVIDIA já demonstrou como seu recurso exclusivo de sombreadores de malha. Além disso, os sombreadores de malha sob o controle de amplificações sombreadores executam o recorte antecipado de superfícies ocultas e a seleção automática do nível de detalhe necessário (LOD) direto na GPU.
Futuramente, o novo modelo deve substituir completamente a etapa de mosaico de superfície, que atualmente é realizada por blocos de funcionalidade fixa, ou pelo menos complementá-la nos casos em que uma solução mais flexível seja adequada. A única coisa que está impedindo a migração dos gráficos do jogo para Mesh Shaders é a necessidade de oferecer suporte explícito à tecnologia em cada novo jogo.
⇡#2 ALUs shader e suporte completo para DirectX 12 Ultimate
Apesar de muita qualidade e, em alguns aspectos, mudanças francamente revolucionárias trazidas pela arquitetura RDNA 2, o principal que chama a atenção nas características do chip Navi 21 é o conjunto duplicado de ALUs shader e unidades de mapeamento de textura em comparação com o Navi 10, que está por trás o modelo carro-chefe da geração anterior, o Radeon RX 5700 XT.
Os engenheiros da AMD fizeram exatamente o que os grandes rumores Navi indicavam desde o início: eles voltaram à configuração com quatro Shader Engines, que tem sido a marca registrada das principais GPUs “vermelhas” desde os dias do chip Hawaii (Radeon R9 série 290). O Shader Engine é o maior componente escalável da arquitetura GCN ou RDNA, contendo uma série de unidades de computação – essencialmente análogo a um único núcleo em unidades de processamento central. O número de UCs varia dependendo de uma GPU específica e, neste caso, é de 20 unidades. O dado Navi 21 totalmente funcional contém um total de 80 UCs ativas, o que equivale a 5120 ALUs shader.
Assim, “Big Navi” realmente se tornou a maior GPU discreta da AMD em termos de poder de processamento bruto em termos de operações FP32 por ciclo de clock. A AMD não é a primeira vez a produzir GPUs desse calibre. Por exemplo, os chips Fiji e Vega 10/20 já alcançaram 4096 ALUs shader, o que, a propósito, deixa uma forte impressão em retrospecto. No entanto, RDNA é uma arquitetura incomparavelmente melhor otimizada para renderização 3D, sem mencionar as inovações de segunda geração e altas velocidades de clock prometidas ao novo silício.
Radeon RX 5700;
Radeon RX 6800 XT;
O Shader Engine também inclui uma seção de cache L1 e um bloco primitivo responsável por montar triângulos de vértices e mosaico, e um rasterizador que realiza a transição de operações em dados geométricos para dados de pixel. Finalmente, aqui estão os back-ends de renderização combinados que funcionam como ROPs independentes. E agora, aqueles poucos leitores que podem desenhar um diagrama de blocos de chips AMD anteriores da memória devem notar algo na estrutura do Navi 21. Dentro do Shader Engine, a divisão ao meio em Shader Arrays desapareceu, cada um dos quais contém 10 unidades de computação associadas com eles blocos de primitivas, RB e rasterizadores, ou seja, a proporção entre o número desses elementos e o sombreador ALU mudou drasticamente.
Parece que os rasterizadores se tornaram um gargalo potencial no pipeline do Navi 21. Como a AMD não está falando sobre nenhuma mudança em sua taxa de transferência, é razoável supor que cada rasterizador ainda produza 16 pixels por clock. Assim, uma proporção não ideal de 1: 2 é estabelecida entre a taxa de rasterização e a taxa de preenchimento de pixel. No entanto, se é realmente assim ou não, não podemos dizer com certeza até que a AMD publique o white paper da nova arquitetura.
Quanto ao RB, o Navi 21 suporta a taxa de preenchimento de pixel necessária para um poderoso núcleo de sombreador, permitindo que cada bloco faça a amostragem, teste e combine oito pixels de 32 bits por clock em vez de quatro, dando à GPU o equivalente a 128 ROPs separados.

Além disso, graças às mudanças no RB, o acelerador adquiriu outra função necessária para cumprir o padrão DirectX 12 Ultimate – Variable Rate Shading. Ele abre a capacidade de ajustar de forma flexível e arbitrária os recursos de computação alocados para renderizar fragmentos de imagem individuais que requerem maior precisão, ou vice-versa, uma queda na qualidade é aceitável. O princípio de operação do VRS é semelhante ao anti-aliasing de tela cheia usando MSAA com supersampling, quando há várias amostras de cores por pixel da tela, cada uma delas chama um pixel shader, mas o contrário – o número de amostras é reduzido de forma arbitrária. A implementação do VRS no Navi 21 oferece suporte a ambos os níveis da função fornecida no nível de recurso 12_2 do Direct3D, ou seja, a precisão do sombreamento pode ser definida para uma chamada de desenho separada, uma primitiva separada ou apenas uma seção de uma imagem. Várias grades de amostra esparsas estão disponíveis, incluindo 1 × 2, 1 × 2 e 2 × 2.

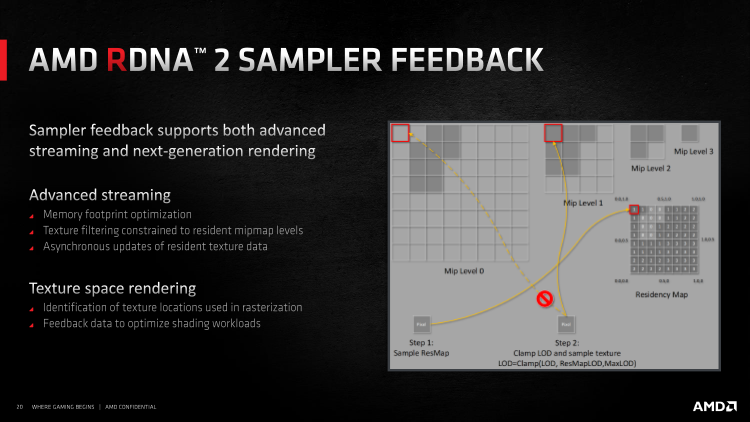
Além disso, RDNA 2 suporta sombreamento de espaço de textura. A renderização direta padrão significa que a GPU rasteriza a geometria em pixels da tela, executa um sombreador de pixel para cada pixel e envia o resultado para um framebuffer. Dentro da estrutura do Texture Space Shading, o resultado dos pixel shaders é salvo na forma de texels de espaço de textura, o que permite reutilizá-los e, assim, salvar ciclos de clock em cálculos de shader adicionais. E, além disso, para melhorar a qualidade de renderização em algumas situações, já que o TSS quebra a vinculação às coordenadas do espaço da tela e os shaders podem ser executados fora do pipeline gráfico como tal.
A condição para a operação eficaz do TSS é determinar com antecedência quais objetos devem ser sombreados no espaço de textura. Para resolver este problema, bem como para reduzir os requisitos gerais do renderizador para a quantidade de memória local da placa de vídeo, o mecanismo Samper Feedback existe no DirectX Ultimate. Cada vez que a GPU solicita um determinado bloco (no caso em que são utilizados recursos de bloco) ou o nível MIP da textura, é feita uma nota em um buffer especial de que esse recurso foi solicitado, e com certo nível de detalhe, e é carregado na VRAM. Caso contrário, a memória conterá apenas cópias de recursos com poucos detalhes.
⇡#RDNA 2 vs. Turing e Ampere

O RDNA executa operações FP16 em seus SIMDs a uma taxa dupla, e o mesmo se aplica a operações inteiras INT16. Além disso, a arquitetura suporta várias variedades de precisão mista, onde a instrução FMA requer a multiplicação de duas matrizes de precisão reduzida (FP16 para números reais e até INT4 para inteiros) e, em seguida, adição com uma matriz FP32 ou INT32. Esses cálculos são realizados a uma taxa acelerada, múltipla da perda de profundidade de bits nos operandos originais (consulte a ilustração). De acordo com o white paper RDNA, o processador gráfico é adicionalmente equipado com ALUs especializadas para cálculos de precisão dupla (FP64), dos quais pode haver de 2 a 16 para cada SIMD de vetor, e a taxa de execução da instrução muda de acordo – de 1/2 a 1/16 em relação ao FP32. Para o Navi 21, o último é verdadeiro, porque é principalmente um processador gráfico para jogos, e alta velocidade de processamento FP64 deve ser buscada nos dispositivos recentemente apresentados da arquitetura CDNA.

Na verdade, aqui a AMD fornece dados sobre a taxa de transferência de um WGP (Processador de grupo de trabalho), ou seja, um par de CUs, e nenhum deles
Além de SIMDs vetoriais, cada unidade de computação tem um pipeline escalar duplo que é usado para ramificação condicional, ramificação e aritmética de número inteiro semelhante. Em tais casos, todos os valores das operações de uma instrução waverfront são os mesmos e assim chamados. escalarização em uma operação, para não desperdiçar energia, carregando SIMD’s com os mesmos cálculos. Os blocos escalares RDNA podem receber sua instrução paralela à instrução vetorial do SIMD correspondente – recentemente, finalmente conseguimos obter a confirmação dos engenheiros da AMD de que o paralelismo desse tipo no RDNA realmente existe.
Por fim, mais um tipo de unidades de execução (SFU), que está presente na Unidade de Computação, realiza a chamada. operações de propósito especial: funções trigonométricas que são frequentemente usadas em tarefas de renderização 3D. O SFU é um SIMD separado associado a cada um dos principais SIMDs vetoriais. Ele serve como um caminho alternativo para a instrução wavefront e a executa a 1/4 de andamento em comparação com as instruções vetoriais convencionais. Para que a UC carregue o SFU, o SIMD vetorial pula um ciclo de clock e está pronto para receber e executar instruções no modo padrão.
A tabela abaixo resume a taxa de transferência teórica de CU dentro da arquitetura RDNA e RDNA 2 versus a lógica de Turing e Ampere atual da NVIDIA e as soluções baseadas em GCN que são boas candidatas para substituição pelos novos aceleradores da série Radeon 6000. Tomamos um intervalo de 8 ciclos de clock da GPU por unidade de tempo para minimizar o número de números fracionários e não buscamos cobrir todas as combinações possíveis de tipos de instrução: neste caso, estamos interessados apenas em operações em inteiros de precisão real e padrão (FP32 e INT32), bem como cálculos funções trigonométricas (SF) e aritmética de ponto flutuante de precisão reduzida (FP16).
O RDNA 2 não recebeu uma coluna separada na tabela, uma vez que a AMD não relata nenhuma mudança profunda no trabalho da Unidade de Computação. Eles apenas dizem que o CU adicionou 30% de desempenho por watt de consumo de energia devido ao aumento das frequências de clock. Mas isso já se refere à eficiência energética do chip Navi 21, que discutiremos (e então mediremos) mais tarde.
4 × vetor SIMD16;
4 × vetor SIMD4 SFU;
1 × ALU escalar;
4 × TMU (unidade de filtragem de textura)
2 × vetor SIMD32;
2 × vetor SIMD8 (SFU); 2-16 × ALU (FP64);
2 × ALUs escalares;
1 × Ray Accelerator (RDNA 2 apenas);
4 × TMU (unidade de filtragem de textura)
4 x 16 seções ALU (FP32);
4 × 16 seções ALU (INT32);
2 × ALU (FP64); 4 × 4 seções SFU;
4 × ALUs escalares; 4 × seções 2 núcleos tensores (ou 4 × seções 32 FP16 ALU);
1 × RT-núcleo;
4 × TMU (unidade de filtragem de textura)
8 x 16 seções ALU (FP32);
4 × 16 seções ALU (INT32);
2 × ALU (FP64);
4 × seções 4 SFU;
4 × ALUs escalares;
4 × núcleos do tensor (128 × FP16 equivalente ALU);
1 × RT-núcleo;
4 × TMU (unidade de filtragem de textura)
8 × FP32 (64 unidades de trabalho) + 8 × escalar
OU
8 × FP16 (2 × 64 unidades de trabalho) + 8 × escalar
OU
4 x 1/2 SF FP32 (64 unidades de trabalho) + 8 x escalar
16 × FP32 (32 unidades de trabalho) + 16 × escalar
OU
16 × FP16 (2 × 32 unidades de trabalho) + 16 × escalar
OU
12 × FP32 (32 unidades de trabalho) + 4 × SF FP32 (32 unidades de trabalho) + 16 × escalar
16 × FP32 (32 unidades de trabalho) + 16 × INT32 (32 unidades de trabalho)
OU
32 × FP16 (32 unidades de trabalho)
OU
4 × (3 + 1/2) FP32 (32 unidades de trabalho) + 4 × (3 + 1/2) INT32 (32 unidades de trabalho) + 4 × SF FP32 (32 unidades de trabalho)
32 × FP32 (32 unidades de trabalho)
OU
16 × FP32 (32 unidades de trabalho) + 16 × INT32 (32 unidades de trabalho)
OU
32 × FP16 (32 unidades de trabalho)
OU
8 × (3 + 1/2) FP32 (32 unidades de trabalho) + 4 × SF FP32 (32 unidades de trabalho)
OU
4 × (3 + 1/2) FP32 (32 unidades de trabalho) + 4 × (3 + 1/2) INT32 (32 unidades de trabalho) + 4 × SF FP32 (32 unidades de trabalho)
512 × FP32 / INT32 + 8 escalar
OU
1024 × FP16 / INT16 + 8 escalar
OU
128 × SF FP32 + 8 escalar
512 × FP32 / INT32 + 16 escalar
OU
1024 × FP16 / INT16 + 16 escalar
OU
384 × FP32 / INT32 + 128 × SF FP32 + 16 × escalar
512 × FP32 + 512 × INT32
OU
1024 × FP16
OU
448 × FP32 + 448 × INT32 + 128 × SF FP32
1024 × FP32
OU
512 × FP32 + 512 × INT32
OU
1024 × FP16
OU
892 × FP32 + 128 × SF FP32
OU
448 × FP32 + 448 × INT32 + 128 × SF FP32
Como você pode ver, a arquitetura RDNA é equivalente a Turing em desempenho teórico em operações FP32 / INT32, FP16 / INT16 ou SFU, quando a carga consiste exclusivamente em um tipo de instruções. No entanto, é surpreendente que RDNA / RDNA 2 não tenha a capacidade de realizar cálculos FP32 e INT32 em paralelo, o que Turing adquiriu, ou simplesmente dobrar a largura de banda do FP32, como é feito em Ampère. No entanto, o RDNA tem algumas vantagens exclusivas. Assim, a escalarização de instruções não aumenta o desempenho dos chips NVIDIA e serve apenas para economizar o consumo de energia, enquanto no RDNA as instruções escalares e vetoriais são enviadas para execução simultaneamente. Além disso, os clientes do escalonador nas GPUs “verdes” também são núcleos tensores, um bloco de ramificação e também um grupo de blocos de carga / armazenamento. Para usar qualquer um deles, o planejador não pode enviar uma instrução para execução em núcleos de sombreador CUDA durante este ciclo. O RDNA sai dessa situação devido ao grande número de portas do agendador (pode fornecer até cinco instruções de vários tipos por ciclo de clock) – solicitações de memória e ramificações também são realizadasparalelo à emissão de instruções para ALUs vetoriais e escalares.
Não surpreendentemente, no contexto de aplicações reais, ao invés de estimativas teóricas de desempenho, é muito difícil liberar totalmente o potencial dos chips Ampere. Os resultados que se aproximam dos valores do passaporte só podem ser discutidos com uma carga exclusivamente de material. Na verdade, nenhum benchmark de jogos replicou tal diferença colossal de desempenho entre os produtos Ampere e aceleradores da geração anterior, como, por exemplo, os testes no Blender raytracer. Tem-se a impressão de que as arquiteturas gráficas desenvolvidas pela NVIDIA e AMD mudaram de lugar: uma vez do lado do “vermelho” havia uma vantagem no número de ALUs shader, que se manifestou mais claramente nas tarefas do GP-GPU. Agora o mesmo pode ser dito sobre o Ampere, que claramente tende a uma carga calculada, apesar da orientação predominantemente para jogos dos chips GA102 e GA104.
Mas o que a AMD ainda não tem a cobrir – esses são os mencionados núcleos tensores, projetados para execução extremamente rápida de operações FMA em dados de profundidade de bits reduzida, que são usados principalmente na operação (e já há algum tempo, no treinamento) de redes neurais. Chips baseados em RDNA são forçados a fazer este trabalho de forma relativamente lenta usando SIMDs vetoriais. E deixe o RDNA desenvolver uma taxa dupla de execução de instruções de meia precisão, um CU por clock executa no máximo 128 operações FP16, enquanto um multiprocessador de streaming NVIDIA – até 512, desde que essas operações sejam em formato tensor. Além disso, contanto que os núcleos do tensor estejam envolvidos, as ALUs do sombreador também não precisam ficar inativas.
⇡#Traçado de raio de hardware
Sobre o traçado de raio acelerado por hardware – uma das funções principais da arquitetura RDNA de segunda geração – por mais estranho que possa parecer, não há muito que possamos dizer. Assim como as arquiteturas rival de Turing e Ampere da NVIDIA, o RDNA 2 depende do popular algoritmo Bounding Volume Hierarchy para otimizar as interseções de polígono de raio em uma cena. O algoritmo BVH pré-classifica as primitivas por caixas aninhadas. Assim, para encontrar rapidamente o ponto de intersecção do raio com a superfície primitiva, o programa precisa percorrer recursivamente a estrutura da árvore BVH e só então calcular as coordenadas baricêntricas da intersecção do raio com o plano, em vez de realizar uma iteração extremamente ineficiente de todos os triângulos na cena.
No entanto, o ray tracing, mesmo com a ajuda do BVH, ainda é uma tarefa extremamente intensiva em recursos quando executado em ALUs de sombreamento universal, motivo pelo qual na arquitetura Turing da NVIDIA surgiram (e depois foram reforçados em chips Ampere) blocos de funcionalidade fixa, projetados especificamente para passar a estrutura BVH e cálculos de interseção de raio com primitivas dentro da caixa menor. Blocos de finalidade semelhantes, chamados de aceleradores de raio (RA), tornaram-se uma adição à arquitetura RDNA no chip Navi 21. Uma parte do RA está envolvida no BVH, a outra está em busca de coordenadas no polígono e a velocidade de cálculo é de 4 e 1 interseções de raios por relógio, respectivamente. Infelizmente, para comparação com RDNA 2, não temos essas informações sobre blocos RT em chips NVIDIA, mas pelo menos sabemos que Ampère (ao contrário de Turing e RDNA 2) permite duas partes de um bloco RT ao mesmo tempo rastrear raios diferentes. Além disso, o Ampere contém otimizações específicas para acelerar o desfoque de movimento traçado que o RDNA 2 também não possui.

De acordo com os testes internos da AMD, o acelerador baseado em Navi 21 atinge 10x o desempenho por meio de rastreamento de raio de hardware em comparação com a renderização apenas de software no mesmo hardware. No entanto, esses números ainda não dizem nada sobre o desempenho de aplicativos reais. O fabricante de chips evita a comparação direta de novas placas de vídeo com as ofertas da NVIDIA em benchmarks de jogos com raio rastreado, e isso não é por acaso. E os números absolutos da taxa de quadros não são acompanhados por comentários suficientemente detalhados sobre a metodologia de teste para que possamos compará-los com os já conhecidos números de Turing e Ampere. Porém, logo descobriremos como as coisas realmente são. O principal é que o rastreamento de raio acelerado por hardware, que antes era impossível em hardware “vermelho”, agora se tornou uma realidade, e o atraso em relação ao pioneiro é perdoável para as primeiras soluções da AMD.
Um problema mais sério para o Radeon com rastreamento de raio de hardware é a falta de ferramentas eficazes de dimensionamento de quadros como o DLSS versão 2.0 em placas de vídeo NVIDIA. Mesmo os modelos mais recentes da série GeForce RTX 30 em alta resolução nem sempre suportam uma taxa de quadros confortável sem upscaling e, aparentemente, os desenvolvedores de jogos já estão se acostumando a adicionar o aumento de desempenho que o DLSS fornece aos requisitos do motor gráfico. Isso coloca o hardware de rastreamento de raios claramente mais fraco da AMD em desvantagem. A empresa está atualmente trabalhando em outra extensão das bibliotecas FidelityFX chamada Super Resolução, que é uma ferramenta de reconstrução de melhor qualidade do que o algoritmo FidelityFX CAS existente, mas o que quer que se diga, o mercado de jogos permanece fragmentado, e nem todos os estúdios de jogos vão investir esforços nisso a integração de duas tecnologias concorrentes.
Como os núcleos RT dos chips Turing e Ampere, o RDNA 2 permite o rastreamento de raio acelerado por hardware sob o controle de DXR GUIs padrão e extensões Vulkan semelhantes. Em tarefas de renderização profissional, o Ray Accelerators ativará o plugin RadeonProRender 3.0 (ainda em beta) para vários programas de modelagem 3D, e no futuro o suporte será estendido para o renderizador Cycles no Blender. Aqui, novamente, a NVIDIA conseguiu percorrer um longo caminho desde o lançamento dos chips Turing, e a aceleração do rastreamento de raios em placas de vídeo GeForce e Quadro agora é usada em quase todos os lugares. A AMD terá que alcançá-la, mas por outro lado, a NVIDIA já desempenhou o papel de um quebra-gelo e, como resultado, a infraestrutura de software para jogos e aplicativos de trabalho agora está muito mais adequada a este tipo de soluções de hardware.
A propósito, não ficaremos surpresos se a Apple se tornar uma das primeiras empresas a fornecer uma plataforma de software para rastreamento de raios para chips RDNA 2. Os chips “caseiros” da empresa parecem promissores, mas a Apple provavelmente terá um longo caminho a percorrer sem as GPUs de outras pessoas em seus desktops e estações de trabalho de alto desempenho.
Hierarquia de memória Navi 21 e Infinity Cache
Agora é a hora de finalmente discutir incondicionalmente a principal inovação da arquitetura RDNA 2 – a pilha de memória local, que inclui um enorme cache L3. Todos os outros armazenamentos mais próximos de ALUs shader passaram por quase nenhuma alteração em comparação com o que já foi feito na primeira geração de chips Navi. As unidades de computação RDNA estão vinculadas em pares (Processadores de grupo de trabalho), tendo um LDS (Compartilhamento de dados local) comum de 128 KB (se crescesse, a AMD provavelmente lhe diria), que é o tipo de memória mais rápido após os registros de vetor SIMD, e Consulte também cache de instrução de 32K e cache escalar de 16K. O cache de nível 0 é exclusivo para cada UC. O volume da seção L1 em cada Shader Engine permaneceu o mesmo – quatro deles somam 1 MB de cache L1.
Há até uma certa regressão de características: a largura de banda na direção de L0 para L1 ficou com a metade do tamanho, e o cache L2, comum para unidades do Shader Engine e processadores de comando, apesar do potencial de computação dobrado do Navi 21, reteve 4 MB. No entanto, tudo isso é mais do que uma compensação pelas medidas que a AMD tomou em relação aos níveis de memória mais recentes disponíveis para a GPU.

GPUs do calibre de Navi 21 precisam de acesso rápido a grandes quantidades de dados. Para atender a essa necessidade, a AMD poderia ter seguido o caminho batido da memória HBM2, que trouxe à Radeon VII um recorde de largura de banda de memória de 1 TB / s para placas de vídeo de consumo, ou um barramento de 512 bits, que quando combinado com chips convencionais GDDR6 garante nada menos PSP. Mas ambas as soluções são problemáticas, cada uma por suas próprias razões, entre as quais o preço é comum. Finalmente, há também chips GDDR6X, que estão longe de ser baratos no preço do produto final, mas embora esse padrão não seja formalmente exclusivo para produtos NVIDIA, a Micron trabalhou nele em cooperação com o último, e o terceiro nesta história provavelmente seria supérfluo.
Felizmente, a AMD encontrou sua própria e, ao que parece, a abordagem mais promissora para o problema. A empresa abandonou as tentativas de acelerar a memória dinâmica externa e usa chips GDDR6 banais com largura de banda de 16 Gb / s em um barramento de 256 bits em novos aceleradores, que no total dá 512 GB / s. Portanto, os dispositivos da série 6000 não estão longe da Radeon RX 5700 XT com seus 448 GB / s. No entanto, além da DRAM discreta, a própria GPU agora abriga um enorme cache L3 de 128 MB chamado Infinity Cache.
O Infinity Cache difere significativamente dos caches L1 e L2, que são parte integrante de qualquer GPU moderna, pois o armazenamento interno CU e Shader Engines são mais voltados para alta largura de banda do que volume e, portanto, astúcia. Portanto, em RDNA, o canal entre L1 e unidades de computação dentro do Shader Engine transmite um total de 4.096 bytes por ciclo e entre todas as seções L1 e L2 – 2.048 bytes. Em termos de toda a GPU, esses valores são dezenas de TB / s, mas devido ao volume modesto de caches, a porcentagem de acessos neles é relativamente pequena. E o mais importante, dimensionar essa estrutura seria extremamente caro em termos de área de cristal. Em vez disso, o Navi 21 tem um cache de último nível como espaçador entre L2 e a memória dinâmica externa, que é modelado no L3 em CPUs de arquitetura Zen e é extremamente denso (quatro vezes o tamanho dos chips L2 Navi).

Blocos horizontais sólidos na parte superior e inferior são Infinity Cache
Na realidade, soluções como o Infinity Cache estão longe de ser novas. Uma grande variedade de memória estática (ou dinâmica de alta velocidade) para as necessidades da GPU – diretamente em um chip ou como um microcircuito separado – foi mais de uma vez equipada com SoCs de consoles de jogos e, até recentemente, também era usada em CPUs móveis da Intel. Mas entre as GPUs de PC discretas, Navi 21 ainda é uma pioneira.
É uma pena que a AMD não nos disse exatamente qual fração da área da matriz é ocupada pelo Infinity Cache, e não temos fotos reais sem uma barreira de difusão para medi-la pelo menos aproximadamente (para moer o chip de uma placa de vídeo de teste com um abrasivo, desculpe, a mão não se levanta). Mas o próprio cristal revelou-se grande para tantas unidades de computação. O Navi 21 contém um total de 26,8 bilhões de transistores e, portanto, não está muito atrás do chip de consumo carro-chefe da NVIDIA, o GA102 (28,3 bilhões). Ao mesmo tempo, o Navi 21 não só ultrapassa 2,6 vezes o Navi 10 em número de transistores, como também tem uma densidade de componentes maior, que deve ser atribuída justamente às compactas bibliotecas SRAM, das quais o Infinity Cache é complexo, pois os dois processadores são produzidos no mesmo e o mesmo pipeline de TSMC de 7 nanômetros.
O cache L3 é conectado ao cache L2 pelo barramento Infinity Fabric, que consiste em 16 canais de 64 bytes e tem overclock de 1,94 GHz. A largura de banda da interface é significativamente menor do que nas camadas mais profundas da pilha de memória, mas ainda atinge impressionantes 1,85 TB / s, o que é quase quatro vezes mais do que os chips GDDR6 em um barramento de 256 bits (512 GB / s no caso de novos aceleradores AMD). O Infinity Cache fica em seu próprio domínio de velocidade de clock, que cai – para 1,4 GHz – em um momento em que o acesso L3 frequente não está ocorrendo. Além disso, mesmo o acesso à RAM sem cache é acelerado graças ao alto rendimento do Infinity Fabric, cujos clientes são controladores GDDR6.
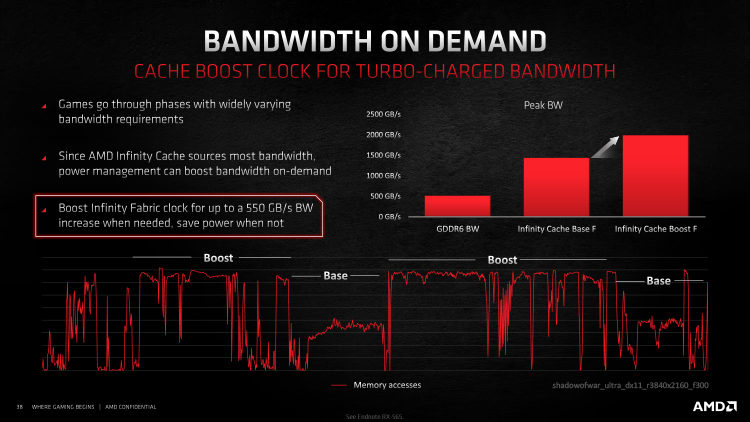
As estimativas numéricas do desempenho do Infinity Cache indicam que sua latência é 48% menor do que a da memória GDDR6 a 14 Gbps, que é usada no Radeon RX 5700 XT, e a latência média de L3 e VRAM nos aceleradores da série 6000 diminuiu em 34% em relação à geração anterior. O Infinity Cache é grande o suficiente para acomodar uma parte significativa dos dados necessários para que as unidades de traçado de raio percorram as estruturas BVH. Além disso, de acordo com o chimpaker, a taxa de acerto geral em L3 chega a 58% quando se trata de jogos no modo 4K, ou seja, até 58% das solicitações de GPU são atendidas em uma velocidade extremamente alta, perdendo apenas para a largura de banda das GPUs de servidor mais recentes com memória HBM2.
Claro, 58% é a estimativa mais otimista, e os algoritmos do motorista são a garantia de uma alta taxa de astúcia neste caso. A AMD não requer software para informar diretamente ao software quais dados colocar no L3, embora exija, portanto, todos os aplicativos existentes tiram proveito automaticamente da nova arquitetura de memória.
Esperamos que o Navi 21 seja menos eficaz em jogos e software profissional, e provavelmente aumentará no futuro, conforme os drivers e aplicativos forem otimizados. Seja como for, o Infinity Cache já permitiu que a AMD ousadamente dobrasse o número de ALUs shader e aumentasse drasticamente a velocidade do clock da GPU sem se preocupar com a largura de banda da memória e, ao mesmo tempo, melhorasse a eficiência energética da memória em comparação com soluções alternativas que implicam em chips 384 ou 512 GDDR6. bit bus.

Finalmente, a AMD anunciou o suporte para a API DirectStorage no Windows, que permite o carregamento direto de ativos de jogos de SSDs na memória GPU local. Infelizmente, o fabricante do chip não fala sobre os recursos da implementação do DirectStorage em seus próprios produtos em detalhes como seu concorrente sobre a tecnologia RTX IO semelhante. Em particular, não há menção à descompressão de dados de hardware usando ALUs shader, que é uma parte importante da solução da NVIDIA. Além disso, o DirectStorage parece ser principalmente um produto de software que não depende de ferramentas de hardware fundamentalmente novas. Portanto, o RTX IO funcionará não apenas nas novas placas de vídeo GeForce série 30, mas também na GeForce RTX 20. A AMD, por sua vez, não especificou se a compatibilidade do DirectStorage se estende aos chips RDNA de primeira geração, embora nós não vemos quaisquer razões técnicas que possam impedir isso.

É impossível ignorar a próxima função do RDNA 2, chamada Smart Access Memory, cujo princípio ainda não está completamente claro. A julgar pela forma como o SAM é caracterizado por seus criadores, ele dá ao processador central acesso direto a toda a memória local da placa de vídeo. Em computadores de jogos típicos, uma pequena parte da VRAM sempre faz parte do espaço de endereço da memória do sistema, mas o SAM, presumimos, simplesmente permite que toda a VRAM seja mapeada para a RAM, evitando assim a cópia desnecessária de dados. Para extrair o máximo de dividendos disso, a otimização do software é bem-vinda, mas agora a tecnologia promete, de acordo com as estimativas médias da AMD, um FPS adicional de 6% em jogos populares com um máximo de até 11%. O SAM está disponível para os aceleradores das séries Radeon 5000 e 6000, mas há um problema: apenas os processadores Ryzen 5000 e placas-mãe baseadas no chipset B550 ou X570 podem funcionar com ele (você precisará atualizar o BIOS e ativar o SAM em suas configurações).

Recentemente, soube-se que a NVIDIA está trabalhando em seu próprio análogo de Smart Access Memory, que funcionará em conjunto com chips da Intel e, se a AMD não se importar, Ryzen. Se isso acontecer, é possível que a AMD remova as restrições ao SAM nas laterais das placas de vídeo e o acesso total ao VRAM, com sorte, mais cedo ou mais tarde será aberto a qualquer combinação de CPU e GPU.
⇡#Decodificação AV1 e saída HDMI 2.1
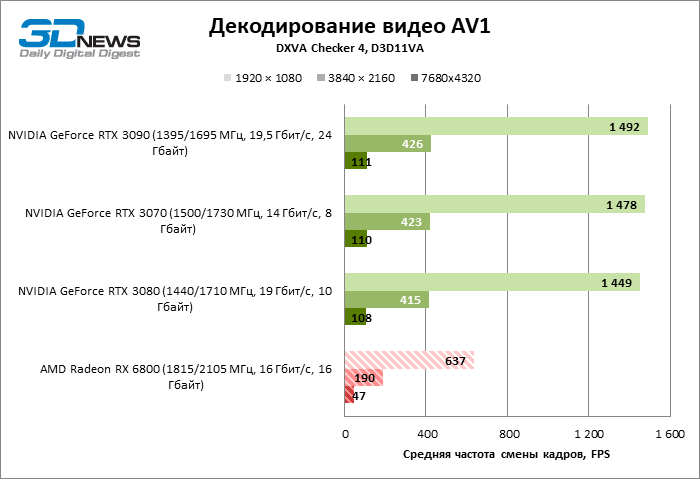
A julgar pelas estimativas oficiais de desempenho, a unidade de multimídia Navi 21 não sofreu nenhuma alteração em comparação com um componente semelhante da primeira geração de chips Navi em termos de decodificação e codificação de padrões de vídeo H.264, HEVC e VP9, embora deva ser dito que a AMD está minimizando seu potencial: em seus próprios benchmarks obtivemos melhores resultados com a Radeon RX 5700 XT. No entanto, o Navi 21 adquiriu a capacidade de codificar HEVC com resolução de 8K, o que as GPUs “vermelhas” não tinham antes, e suporte para B-frames (um dos tipos de frames intermediários) em H.264. Mais importante, o Navi 21 aprendeu a decodificar o padrão AV1 avançado e extremamente intensivo em recursos com uma taxa de quadros de 30 FPS em resolução de 8K (mesmo que não seja 60 FPS ou mais, como no silício Ampere da NVIDIA).

Finalmente, a interface de vídeo HDMI 2.1 avançada já alcançou adoção comercial em TVs e monitores, e agora as placas de vídeo também a estão adotando. O controlador de exibição Navi 21 usa a largura de banda total do HDMI 2.1 para produzir 8K a 60 Hz ou mais importante, 4K a 120 Hz sem a necessidade de compactação de dados.
Especificações, preços. Design de placa de vídeo de referência
⇡#Especificações, preços
De acordo com estimativas quantitativas aproximadas, a AMD conseguiu criar um processador gráfico que pode ser equiparado ao principal cristal Ampere da NVIDIA – GA102. O chip Navi 21 totalmente funcional contém 5120 ALUs de shader compatíveis com FP32, 320 unidades de mapeamento de textura e 128 ROPs. Claro, GA102, que é descrito pela fórmula 10 752: 336: 112, supera o rival recém-cunhado no potencial computacional de sombreadores, mas vale a pena lembrar mais uma vez que Ampere é incrivelmente eficiente em tarefas computacionais, mas a dupla matriz de núcleos FP32 CUDA, que é uma característica fundamental deste a arquitetura não dobra a taxa de quadros do jogo.
Com base no mesmo chip Navi 21, a AMD criou três placas de vídeo de consumo que diferem entre si no número de unidades GPU ativas, consumo de energia e, claro, preço. Você pode encontrar suas especificações na tabela abaixo.
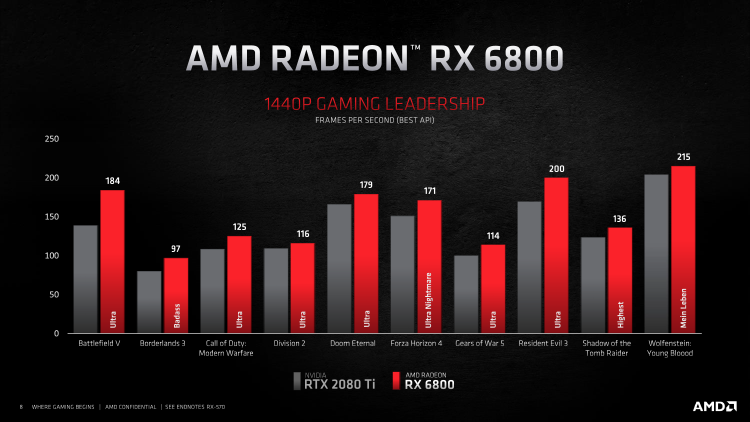
O modelo básico Radeon RX 6800 foi colocado à venda com um preço recomendado de 79, e a AMD vê a GeForce RTX 2080 Ti como um competidor adequado. Com base em resultados de testes internos, o Radeon RX 6800 supera regularmente o RTX 2080 Ti em benchmarks de jogos populares em 1440p e 2160p sem traçado de raio, mas o alvo real neste caso é a GeForce RTX 3070 de $ 499, que durante o anúncio da série Radeon 6000 ainda não apareceu no mercado, mas suas capacidades eram provavelmente bem conhecidas do concorrente.
No entanto, há um fator que lança uma sombra sobre as afirmações da NVIDIA. O Radeon RX 6800 deu uma vantagem na forma de tecnologia Smart Access Memory em uma plataforma com processador Ryzen 5000 e, como lembramos, promete aumentar a taxa de quadros em um valor médio de 6% FPS. Além disso, notamos que o chip Navi 21 foi cortado muito seriamente para se encaixar nas características do Radeon RX 6800 – de 80 para 60 CU – e isso provavelmente afetou sua eficiência energética. Mas o que fazer, a AMD ainda não tem uma GPU adequada entre Navi 10 e Navi 21.
Mais importante, o fabricante do chip está confiante o suficiente na superioridade do Radeon RX 6800 sobre o GeForce RTX 3070 para cobrar um preço de varejo mais alto. Enquanto escrevíamos essas linhas, não sabíamos quão bem o RX 6800 teria em nossos testes, mas uma vantagem do dispositivo AMD está fora de dúvida. Todos os três novos produtos têm 16 GB de VRAM, incluindo a RX 6800, que é o dobro dos modestos 8 GB da GeForce RTX 3070.
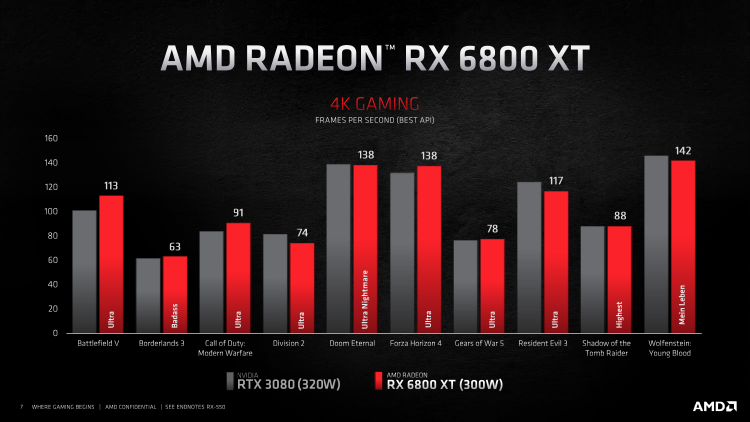
Por sua vez, o Radeon RX 6800 XT difere do modelo mais jovem por frequências de clock significativamente aumentadas, consumo de energia e, mais importante, o número de CUs ativos (72 de 80) no chip Navi 21. Não foi à toa que a AMD escolheu o Radeon RX 6800 XT para demonstrar o progresso intergeracional do silício Navi : A nova placa de vídeo deve ter o dobro da velocidade em comparação com a Radeon RX 5700 XT.
De acordo com estimativas preliminares, o Radeon RX 6800 XT oferece uma taxa de quadros de jogos, em média, equivalente à GeForce RTX 3080, com uma vantagem a favor de um ou outro dispositivo em títulos individuais (desta vez sem Smart Access Memory). No entanto, neste caso, os Reds estão novamente jogando uma carta mais acessível. É 0% mais barato que seu rival de US $ 699, apesar de sua vantagem em VRAM, e é fácil adivinhar o porquê. Embora o rastreamento de raios em tempo real seja um dos principais recursos que diferenciam a arquitetura RDNA 2 do hardware anterior da AMD, o fabricante de chips evita qualquer comparação com seus concorrentes na disciplina de rastreamento de raios de jogos.
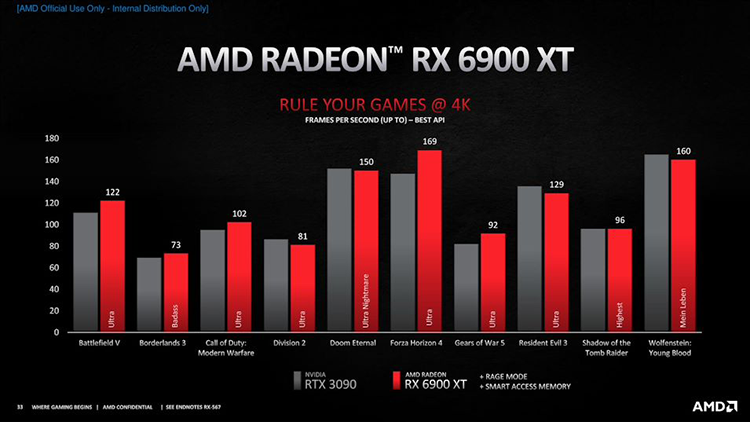
Finalmente, a série de novos aceleradores é coroada pelo Radeon RX 6900 XT, que veremos não antes de 8 de dezembro, e então dificilmente vale a pena contar com a ampla disponibilidade desta placa de vídeo. O Radeon RX 6900 XT apresentará um cristal Navi 21 totalmente ativado com 80 unidades de computação em toda a sua glória. É a placa de vídeo mais poderosa que a AMD já construiu e, sem dúvida, uma das placas de vídeo de mais alto desempenho em sua classe. Parece que o RX 6900 XT foi a última adição à linha 6000 e é principalmente um símbolo das conquistas da nova arquitetura, da qual a empresa não espera muito sucesso comercial. Como os modelos mais jovens, o carro-chefe encontrou um rival adequado entre os dispositivos NVIDIA – a GeForce RTX 3090, mas não apostaríamos que os Reds venceriam esta batalha. A AMD publicou um slide com classificações de desempenho, no qual os dois aceleradores trocaram golpes, mas não apenas a Smart Access Memory na plataforma Ryzen 5000 joga a favor do Radeon RX 6900 XT, mas também simplesmente fazendo overclock da GPU.
O fato é que a interface do driver Radeon RX 6800 e 6900 XT possui a opção Rage Mode, que nada mais é do que overclock de fábrica com maior reserva de energia. A AMD já usou essa técnica no passado quando sentiu a superioridade de seu rival, mas, por exemplo, o RX 6800 não possui overclock de um botão. Além disso, produtos desse tipo são de interesse principalmente não para jogadores, mas para usuários de estações de trabalho. Mas no campo das GP-GPUs, a NVIDIA está mais forte do que nunca, o que se aplica não apenas ao desempenho, mas também à infraestrutura de software. Finalmente, o Radeon RX 6900 XT não possui a mesma quantidade de memória local que o RTX 3090 (16 GB contra 24 GB). Por outro lado, o preço do carro-chefe Radeon está em linha com as expectativas de suas capacidades: digamos o que disser, mil dólares é menos que um mil e meio.
A AMD ainda usa o pipeline TSMC de 7 nm para produzir GPUs, mas desta vez a empresa aproveitou muito melhor sua tecnologia de processo avançada. Graças a uma série de otimizações diferentes, os chips Navi de segunda geração estão longe de seus predecessores e, de acordo com a AMD, consomem 50% menos energia em termos de número de unidades de computação e velocidade de clock. O aumento resultante no desempenho específico em relação ao Navi 10 é estimado em 54%, entre os quais 16% são atribuídos a bibliotecas lógicas de alta velocidade e 17% – mecanismos para desativar blocos de GPU inativos e eliminar a transferência de dados desnecessária. Finalmente, outros 21% de eficiência energética vieram do cache L3, um front-end e back-end atualizados do pipeline de renderização.
Como resultado, agora a AMD pode aumentar a velocidade do clock em 30% em relação ao consumo de energia e ao número de UCs, e isso é claramente visível nas especificações dos novos produtos. O parâmetro GameClock (relógio de referência em jogos típicos) dos dois modelos mais antigos é 2015 MHz, e o Boost Clock (relógio oportunista em condições de reserva de marcha não esgotada) atinge 2250 MHz. A versão básica do Radeon RX 6800 é limitada às frequências de 1815 e 2105 MHz. O fabricante nem mesmo indica a frequência base do GPU, já que na prática os chips modernos funcionam tão lentamente apenas em condições de temperatura severa ou afogamento de energia.
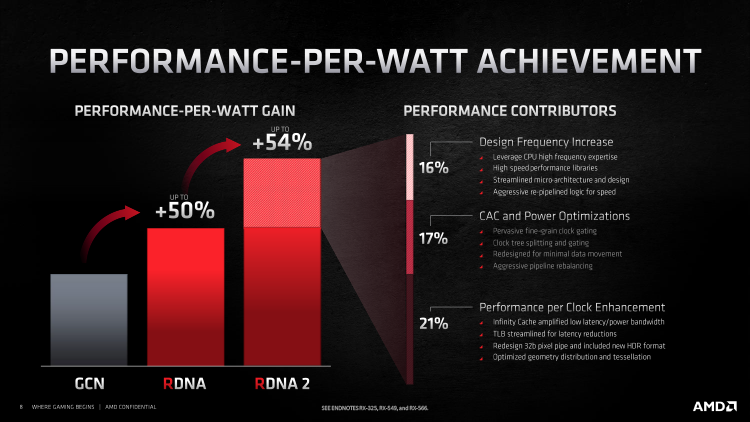
Seja como for, o aumento simultâneo das frequências do clock e do orçamento do transistor da GPU não passou sem deixar rastros para os indicadores absolutos de consumo de energia. A Radeon RX 6800 opera em um pacote térmico de 250 W, e este é, de fato, um resultado surpreendente, porque incomparavelmente mais fraca do ponto de vista computacional, a Radeon RX5700 XT é projetada para 225 W. Mas o Radeon RX 6800 XT e o 6900 XT já são capazes de desenvolver uma potência séria de 300 watts. Claro, as placas de vídeo “verdes” de última geração se mostraram ainda mais vorazes, mas agora não há dúvida de que o consumo de energia na região de 300-350 finalmente se tornou uma norma para aceleradores gráficos da mais alta categoria.
⇡#Radeon RX 6800 e Radeon RX 6800 XT: construção
Como já dissemos, as placas de vídeo de referência de marcas parceiras da fabricante de chips serão colocadas à venda primeiro. Modelos customizados de alguns fabricantes já estão no horizonte, mas demoram um pouco para chegar às prateleiras. A AMD sempre faz isso com produtos baseados em silício completamente novo, e a ausência de modificações de parceiros logo no início das vendas complicou mais de uma vez os primeiros meses de vida dos novos produtos “vermelhos”. O fato é que exemplos verdadeiramente bem-sucedidos de design de referência da AMD podem ser contados em uma mão, e quase todos eles são placas de vídeo refrigeradas a água: Radeon R9 295 X2, Radeon RX Vega 64 LC e, se não por falhas frequentes de bomba, você pode seria adicionar à lista o Radeon Fury X. A AMD não aprendeu como fazer refrigeradores de ar de alta qualidade até recentemente.
Felizmente, com a série 6000, a empresa está determinada a consertar a reputação dos modelos de referência Radeon. A AMD não foi tão longe a ponto de apresentar uma marca separada para eles, como a Founders Edition, mas a julgar pela estética dos produtos e as características do sistema de refrigeração, eles merecem.


AMD Radeon RX 6800
Para o Radeon RX 6800, por um lado, e o RX 6800 XT / 6900 XT, por outro, projetamos dois coolers semelhantes, que diferem principalmente no tamanho e, consequentemente, na profundidade das aletas do radiador. O modelo mais jovem ocupa estritamente dois slots de expansão no gabinete do PC, o mais antigo – dois e meio. O resto das dimensões são as mesmas. Em particular, o comprimento dos dispositivos é de 267 mm, então eles cabem em quase qualquer gabinete moderno, projetado para placas-mãe ATX completas. Ao mesmo tempo, as placas gráficas pesam muito devido ao grande dissipador de calor, que cobre quase toda a área do PCB, e ao invólucro de metal: nossas balanças marcavam 1397 g para a Radeon RX 6800 e 1517 para a versão XT.


AMD Radeon RX 6800
Ao contrário das amostras de referência Radeon RX 5700 e RX 5700 XT, que, apesar de sua aparência apresentável, se distinguiam por altas temperaturas e altos níveis de ruído, as novas placas de vídeo são atendidas pelo design CO aberto obviamente mais eficiente com três ventoinhas de 80 mm. As pás de cada ventilador são circundadas por um anel que focaliza o fluxo de ar na direção axial. Quando a GPU está ociosa, os ventiladores param e o dispositivo é resfriado passivamente. A AMD prometeu que sob carga de trabalho, o novo cooler é 6 dBA mais silencioso do que a turbina Radeon RX 5700 XT. Quer isso seja verdade ou não, verificaremos em testes, mas primeiro garantiremos que o ruído de fato se tornou muito menor.
A carcaça do sistema de refrigeração é projetada de forma que o ar aquecido saia do ventilador através de amplas janelas nas laterais compridas do radiador. A placa de montagem é surda aqui, mas não importa: as aletas do ventilador ainda funcionam perpendicularmente a ela. O principal é garantir a ventilação adequada do gabinete do computador: as novas placas de vídeo desenvolvem uma potência de 250-300 W, e todo o calor permanece dentro do micro. Confuso apenas pela grande saliência, que bloqueia parcialmente a saída de ar no centro (em maior medida, isso se aplica ao modelo básico Radeon RX 6800) e existe apenas para encontrar um lugar para o logotipo Radeon brilhante. A AMD claramente adotou alguns dos recursos de design das placas de vídeo verdes da geração anterior Founders Edition, incluindo esta não é a solução mais prática.

Há outro recurso emprestado da Edição dos Fundadores da 20ª série e, em nossa opinião, não é muito atual. Uma das saídas DisplayPort foi alterada para USB Type-C para transmissão de sinal e fonte de alimentação de fones de ouvido de realidade virtual dentro da estrutura do padrão VirtualLink. É improvável que muitos compradores lamentem a perda de um conector DisplayPort de formato completo, mas, por outro lado, há ainda menos usuários de HMD (especialmente com uma conexão USB Tipo C unificada). Além disso, a tecnologia VirtualLink nunca decolou, apesar do suporte dos fabricantes de hardware NVIDIA e VR. Não é à toa que a própria NVIDIA o abandonou nos aceleradores GeForce 30. Felizmente, o conector em miniatura ainda pode ser usado como um conector USB de alta velocidade normal, inclusive para conectar monitores no modo de encaminhamento DisplayPort. O VirtualLink não altera a pinagem do conector e apenas aumenta a largura de banda das linhas USB que funcionam em paralelo com o sinal DisplayPort de 2.0 para USB 3.1 Gen 2 – desde que o cabo correto seja usado.

Na base do dissipador de calor dos cartões de referência da série 6000 está uma grande câmara de vapor que se junta ao chip da GPU e distribui o calor para as aletas. A AMD novamente usou uma interface térmica de grafite em vez de pasta térmica, mas dificilmente vale a pena se preocupar: ela não funciona pior do que a maioria das pastas térmicas na Radeon VII e nas versões de referência da Radeon RX 5700 (XT). Além disso, a gaxeta de grafite é mais espessa do que a camada da interface térmica do líquido, e isso pode ser considerado uma vantagem para resfriadores com uma câmara de evaporação, cuja base é mais difícil de alinhar do que os dissipadores de calor convencionais em tubos de calor pressionados no sanduíche de cobre do dissipador de calor.

Por sua vez, os microcircuitos GDDR6 e as chaves reguladoras de tensão são cobertos por uma moldura maciça acoplada ao radiador principal. O verso do PCB é protegido por uma placa de alumínio, que também participa da remoção de calor das áreas quentes do PCB.

Infelizmente, os cartões chegaram até nós para teste com um grande atraso, e não tivemos tempo de desmontar o cooler com cuidado e tirar nossas próprias fotos da placa de circuito impresso. Além disso, tememos que desta vez a substituição da gaxeta de silicone por graxa térmica não seja indolor e os parafusos não forneçam mais a pressão necessária do dissipador de calor ao cristal da GPU.
⇡#Placa de circuito impresso
Uma coisa para a qual a AMD nunca poupa dinheiro é manipular PCBs de referência para GPUs de alto desempenho, e a série 6000 não é exceção. O PCB permite um total de 16 fases de reguladores de tensão para alimentar os chips GPU e RAM, embora provavelmente veremos apenas um conjunto completo de estágios de alimentação e filtros no modelo top Radeon RX 6900 XT. O RX 6800 XT tem uma fase de alimentação da GPU removida, deixando 13 fases para a GPU e duas para alimentar os chips GDDR6.
Você não pode reclamar da seleção de componentes de filtragem nos circuitos antes e depois dos estágios de potência. Apenas capacitores SMD são usados em todos os lugares, e na parte de trás da GPU há uma floresta inteira de pequenos eletrólitos de alumínio (SP-CAPs).

No entanto, houve vários motivos de insatisfação. Em primeiro lugar, ainda não há shunts de detecção de corrente no PCB, de modo que o BIOS da placa de vídeo permite que você registre e controle diretamente o consumo total de energia do dispositivo. A automação monitora apenas a potência do cristal da GPU pela queda de tensão nas bobinas de saída VRM. Em segundo lugar, a AMD não parece ter a intenção de devolver uma opção tão útil para os entusiastas quanto um chip BIOS duplicado. Finalmente, a própria BIOS (hoje em dia!) Não suporta o modo UEFI.
Técnica de teste. Velocidades de clock, consumo de energia, temperatura, ruído e overclock. Testes de jogos (1920 × 1080)
⇡#Suporte de teste, metodologia de teste
Na maioria dos jogos de teste, as taxas de quadros média e mínima são derivadas de uma série de tempos de renderização de quadros individuais, que são registrados pelo benchmark integrado (ou pelo utilitário OCAT, se não estiver disponível).
A taxa média de quadros nos gráficos é o recíproco do tempo médio de quadros. Para estimar a taxa de quadros mínima, o número de quadros formados a cada segundo do teste é calculado. Desta matriz de números, seleciona-se o valor correspondente ao 1º percentil da distribuição. Red Dead Redemption 2 é uma exceção: seu benchmark integrado registra automaticamente o primeiro percentil do tempo de renderização do quadro, a partir do qual a taxa de quadros correspondente é derivada.
A energia da placa gráfica é registrada separadamente da CPU e de outros componentes do PC usando o dispositivo NVIDIA PCAT. Como uma carga de teste para testes de potência e ruído, o Crysis 3 é usado com uma resolução de 3840 × 2160 sem anti-aliasing de tela cheia e configurações máximas de qualidade gráfica, bem como um teste de estresse FurMark com as configurações mais agressivas (resolução 3840 × 2160, MSAA 8x). Todos os parâmetros são medidos após o aquecimento da placa de vídeo, quando a temperatura da GPU e a velocidade do clock se estabilizam.
⇡#Participantes do teste
As seguintes placas de vídeo participaram do teste de desempenho:
- AMD Radeon RX 6800 XT (2015/2250 MHz, 16 Gb / s, 16 GB);
- AMD Radeon RX 6800 (1815/2105 MHz, 16 Gb / s, 16 GB);
- AMD Radeon VII (1400/1750 MHz, 2 Gb / s, 16 GB);
- AMD Radeon RX 5700 XT (1605/1905 MHz, 14 Gb / s, 8 GB);
- NVIDIA GeForce RTX 3090 FE (1395/1695 MHz, 19,5 Gb / s, 24 GB);
- NVIDIA GeForce RTX 3080 FE (1440/1710 MHz, 19 Gb / s, 10 GB);
- NVIDIA GeForce RTX 3070 FE (1500/1730 MHz, 14 Gb / s, 8 GB);
- NVIDIA GeForce RTX 2080 Ti FE (1350/1645 MHz, 14 Gb / s, 11 GB);
- NVIDIA GeForce RTX 2080 SUPER FE (1650/1815 MHz, 15,5 Gb / s, 8 GB);
- NVIDIA GeForce GTX 1080 Ti FE (1480/1582 MHz, 11 Gb / s, 11 GB).
Aproximadamente. Entre colchetes após os nomes das placas de vídeo, as frequências base e boost são indicadas de acordo com as especificações de cada dispositivo, e no caso das placas de vídeo da série Radeon 6000 – Game Clock e Boost Clock. Placas de vídeo com overclock de fábrica são alinhadas aos parâmetros de referência (ou próximos a estes), desde que isso possa ser feito sem edição manual da curva de freqüência do clock. Caso contrário (aceleradores NVIDIA GeForce série 16, bem como GeForce RTX 2070/2080/2080 Ti Founders Edition), as configurações do fabricante são usadas.
Velocidades de clock, consumo de energia, temperatura, ruído e overclocking
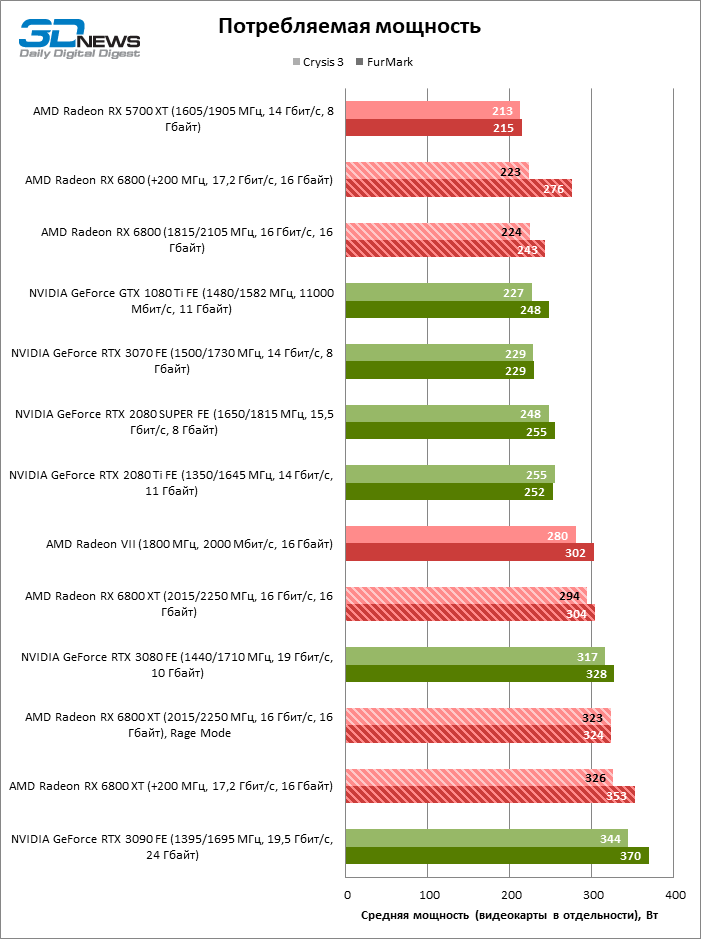
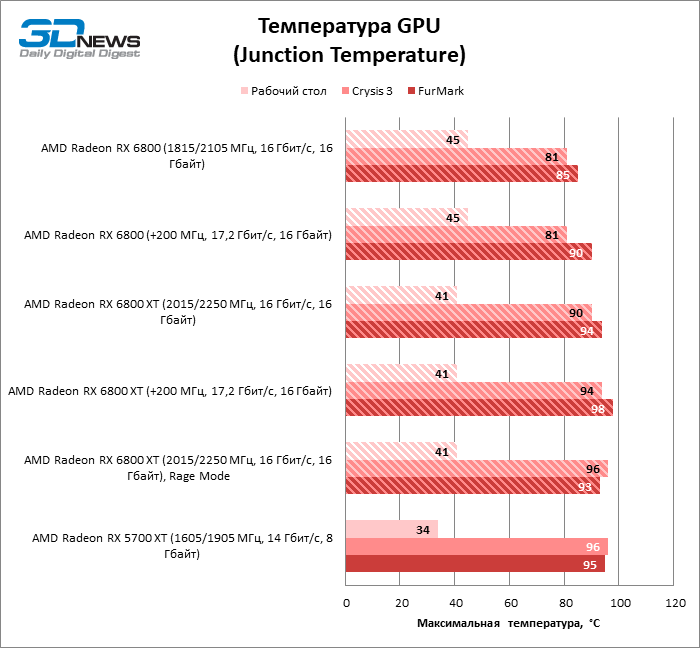
A AMD não está exagerando quando diz o quão altas velocidades de clock o silício Navi 21 superou. Mesmo em jogos que podem aquecer a GPU e também o sempre-vivo Crysis 3, ambos os modelos Radeon RX 6800 – base e XT – cruzaram facilmente a marca dos 2 GHz: sustentado os indicadores são 2.076 MHz para os mais novos e 2.104 para os mais velhos.
Ao mesmo tempo, embora as placas de vídeo “vermelhas” ainda não tenham shunts para medir a corrente nas linhas de força de 12 V, um wattímetro externo mostra que elas se encaixam perfeitamente no âmbito da reserva de marcha do passaporte. O consumo de energia da Radeon RX 6800 XT não excede 300 W, e o modelo básico realmente é suficiente com 224 de 250 W, o que é simplesmente chocante quando você vê a faixa de 213 W pertencente à Radeon RX 5700 XT ao lado dela no gráfico.
Aproximadamente. Todos os parâmetros são medidos após o aquecimento da GPU e a estabilização das frequências do clock.
Naturalmente, tais resultados encorajam o overclock da GPU ainda mais. Além disso, a AMD ainda é tão amigável com o overclock de seus produtos quanto antes. Softwares de terceiros – vários utilitários baseados no Riva Tuner ou no editor de tabelas PowerPlay – ainda não são capazes de lidar com o “big Navi”, então teremos que adiar experimentos como undervolting ou overclock com excesso de potência definido pelo firmware do acelerador para mais tarde. Mas a interface do driver do software Radeon já contém as ferramentas básicas para gerenciar a velocidade do clock da GPU e da memória de vídeo e, o mais importante, permite aumentar a reserva de energia de qualquer uma das placas de vídeo em 15%.
Vamos começar com o modelo básico Radeon RX 6800. Ao contrário do RX 6800 XT e do carro-chefe Radeon RX 6900 XT, ele não possui a função de overclock de um botão – Modo Rage – e a tensão máxima da GPU é fixada em 1,025 V. Além disso, a guia de overclocking no painel de controle A placa gráfica não permite mais alterar manualmente a forma da curva de frequência do clock, como nas placas gráficas da série 5000. Mesmo assim, conseguimos aumentar o limite de freqüência do clock de 2224 para 2424 MHz sem nenhum dano à estabilidade. Mas, infelizmente, sem a possibilidade de alterar a reserva de energia em mais de 15%, metade do overclock permaneceu no papel, e em jogos exigentes a GPU adicionou apenas 100 MHz.
A largura de banda da RAM aqui aumenta até o limite definido no firmware de 17,2 Gb / s dos 16 Gb / s padrão, mas não esperamos que a largura de banda de memória adicional seja um benefício tangível para a arquitetura com um enorme cache L3. O fato de que o overclock do Radeon RX 6800 não foi coroado de grande sucesso também é indicado pelas medições do consumo de energia, que aumentou no teste de estresse FurMark, mas permaneceu quase inalterado em jogos com muitos recursos.
Mas a Radeon RX 6800 XT fez overclock com estrondo. O BIOS do modelo antigo também permite aumentar a potência em 15%, mas devido ao fato de que a GPU aqui começa de uma posição mais alta e a tensão de alimentação chega a 1,15 V, a placa de vídeo tem grande potencial de overclock, apesar das escassas capacidades de software com as quais ainda estamos forçado a colocar. A frequência de núcleo padrão de 2.394 MHz foi aumentada em 200 MHz, e a mesma coisa aconteceu com o clock sob carga de jogos, que como resultado oscila em torno da marca de 2.306 MHz e faz rajadas curtas além de 2,5 GHz. O overclock da RAM Radeon RX 6800 XT enfrentou as mesmas limitações da Radeon RX 6800. No entanto, o modelo mais antigo ainda não usa totalmente toda a reserva de energia alocada a ele: sim, em jogos aumentou para 326 W, mas os resultados os testes de estresse estimam o consumo máximo de energia com um aumento de 15% de 353 watts.
O overclocking do modo Rage com um botão é um estado intermediário entre o desempenho padrão da Radeon RX 6800 XT e o overclocking manual: ele aumenta a velocidade do clock da GPU em 89 MHz ao injetar 20-29 watts adicionais de potência.
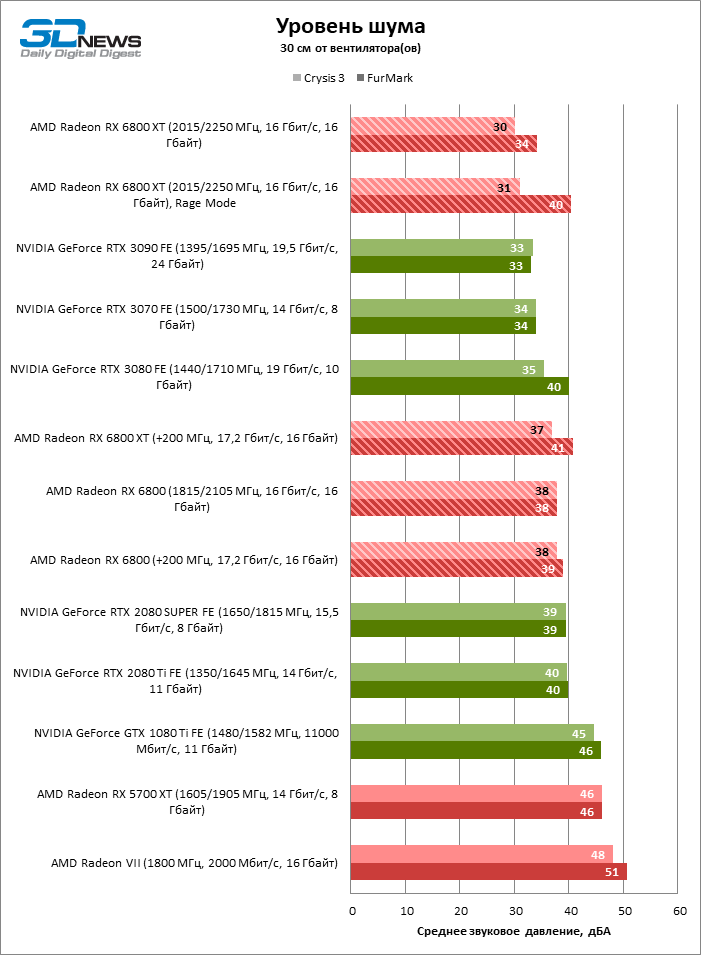
Estamos felizes em notar que as vantagens da versão de referência Radeon RX 6800 XT não se limitam ao overclock. A AMD finalmente conseguiu fazer um sistema de refrigeração de ar de qualidade. Não apenas o 6800 XT suporta baixas temperaturas de GPU, ele acabou sendo o mais silencioso entre os aceleradores de alto desempenho em nosso banco de dados (novamente, sem contar os dispositivos com hidropisia), não apenas no modo normal, mas também no modo Rage. Mesmo após o overclock manual, a placa de vídeo é mais silenciosa do que os modelos mais antigos da série Founders Edition 20, sem falar nos produtos de referência de ambas as empresas com cooler de turbina.
O modelo básico Radeon RX 6800, é claro, não é tão bom – o corte do dissipador de calor se faz sentir. Apesar disso, com ou sem overclock, o RX 6800 não faz tanto ruído como, por exemplo, a GeForce RTX 2080 SUPER ou a GeForce RTX 2080 Ti Founders Edition.
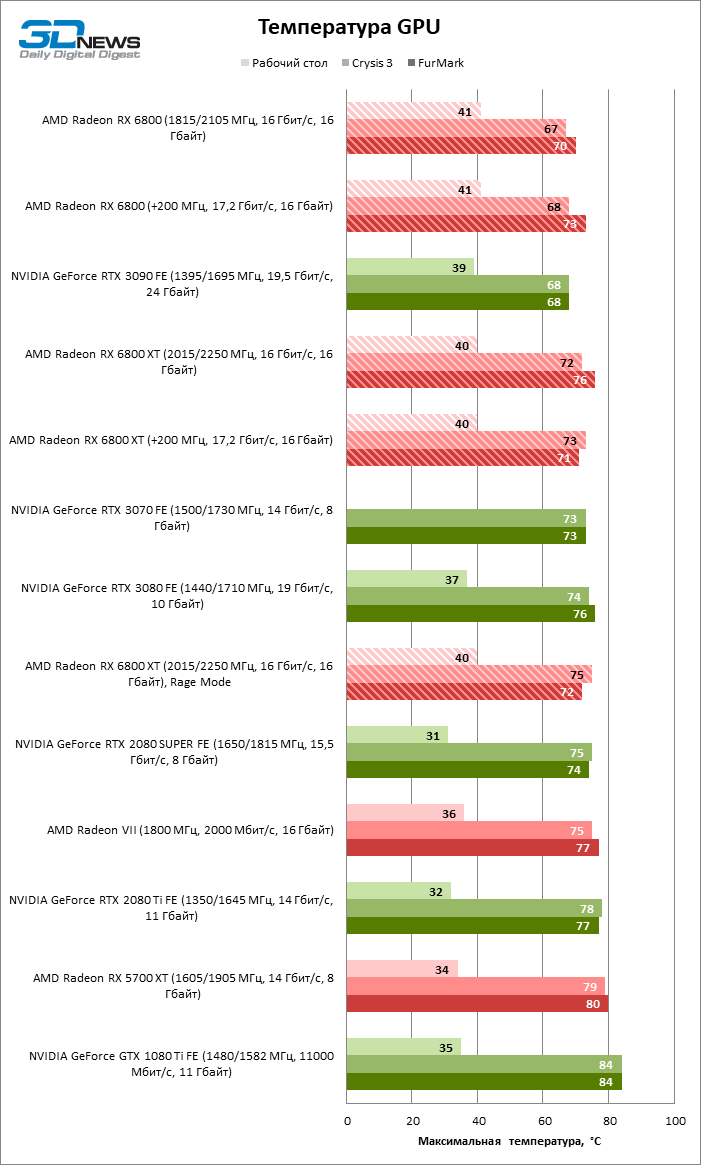
A única pena é que a BIOS dos novos produtos não permite monitorar a temperatura dos chips GDDR6 e chaves reguladoras de tensão. Esperemos que este seja um recurso das placas de vídeo de referência, e ainda seremos capazes de verificar a qualidade de resfriamento desses componentes em dispositivos futuros parceiros.
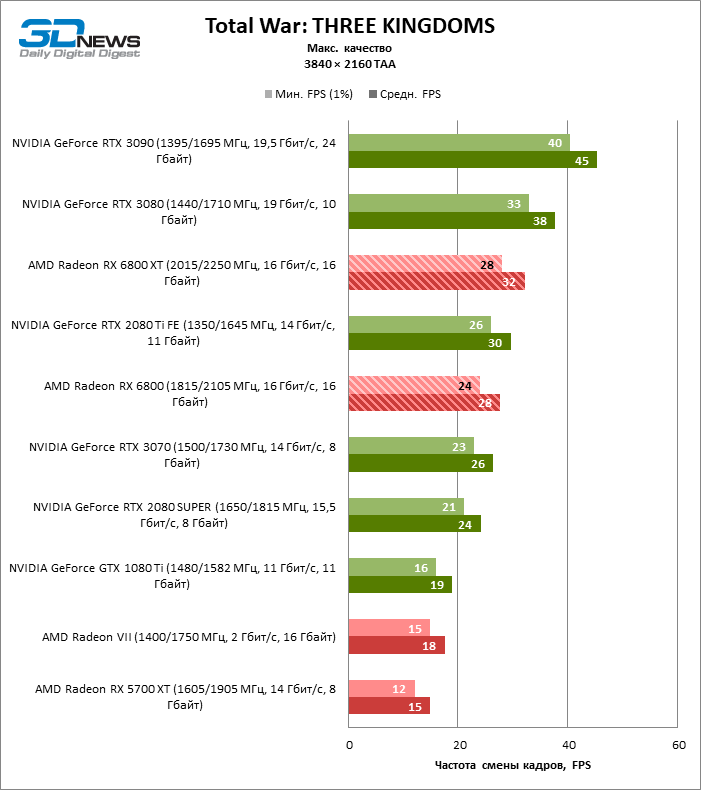
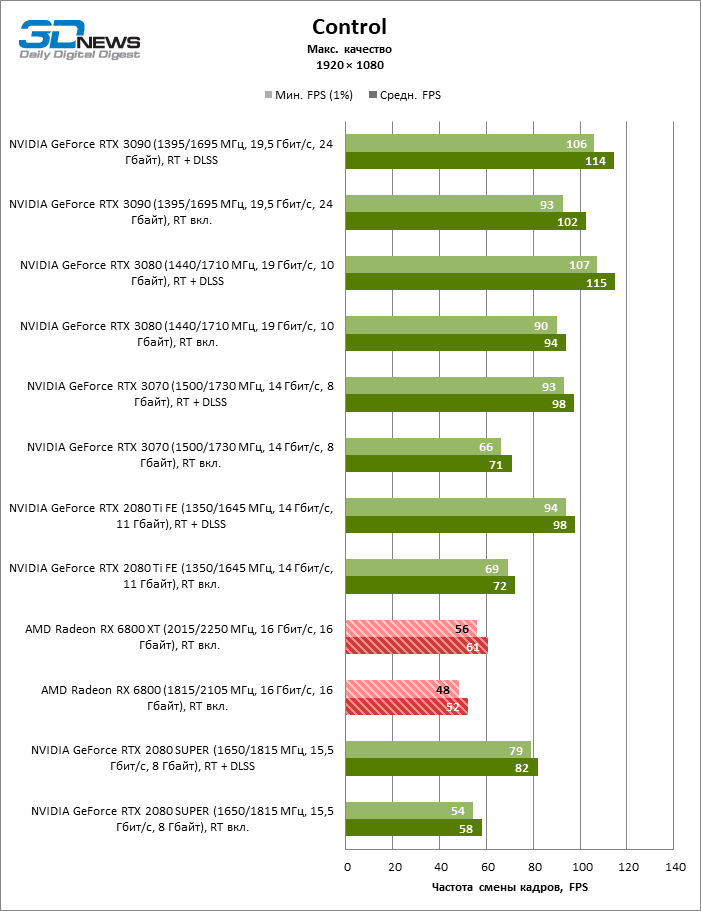
⇡#Testes de jogos (1920 × 1080)
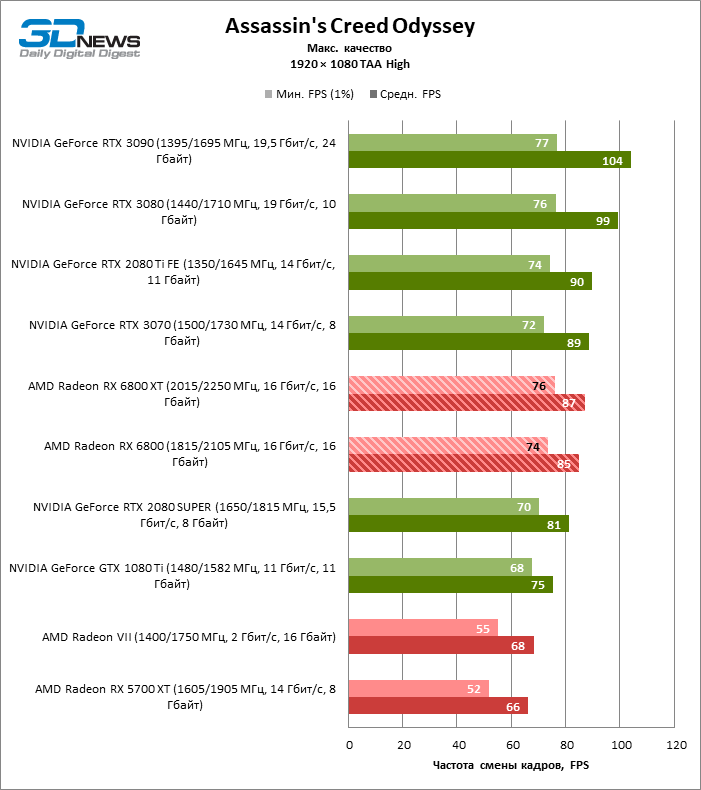
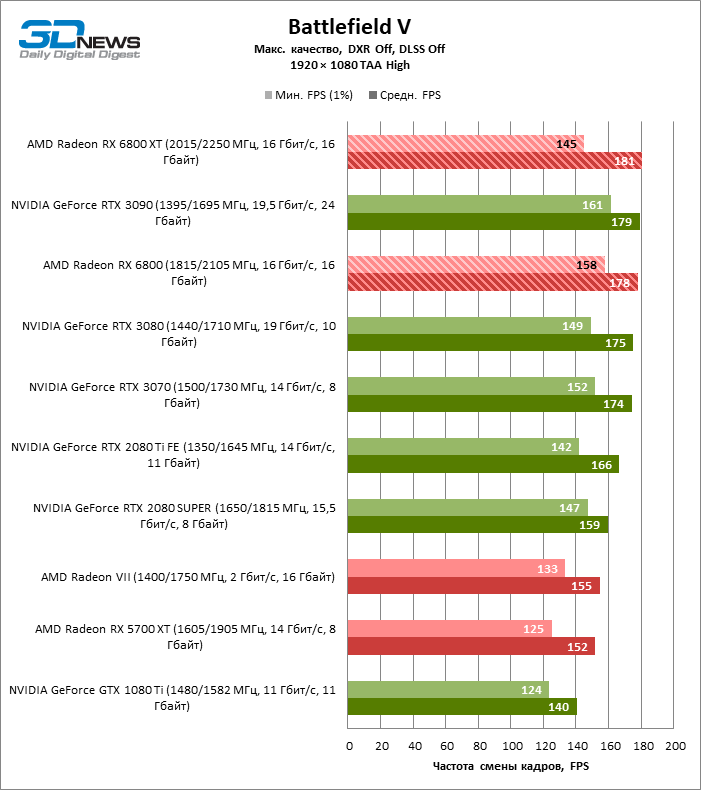
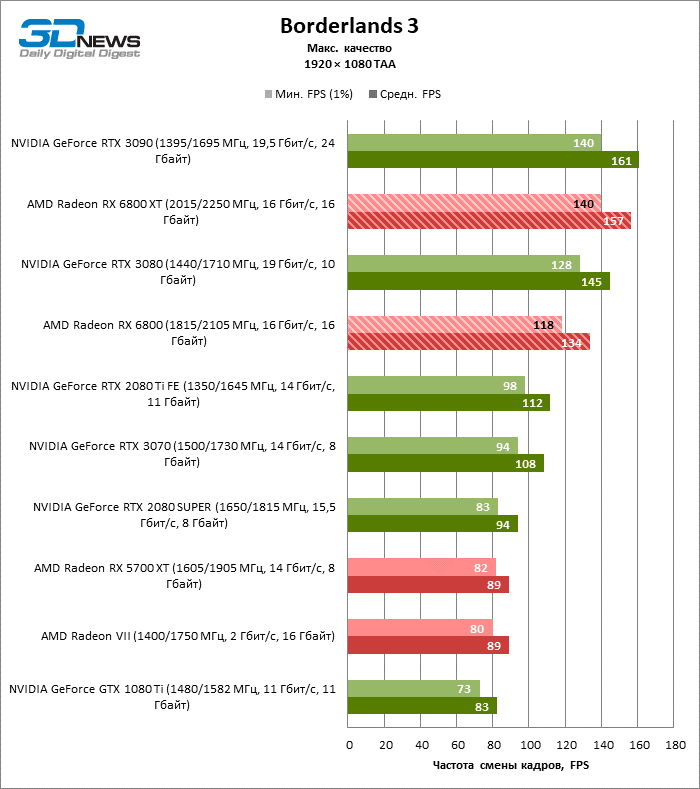
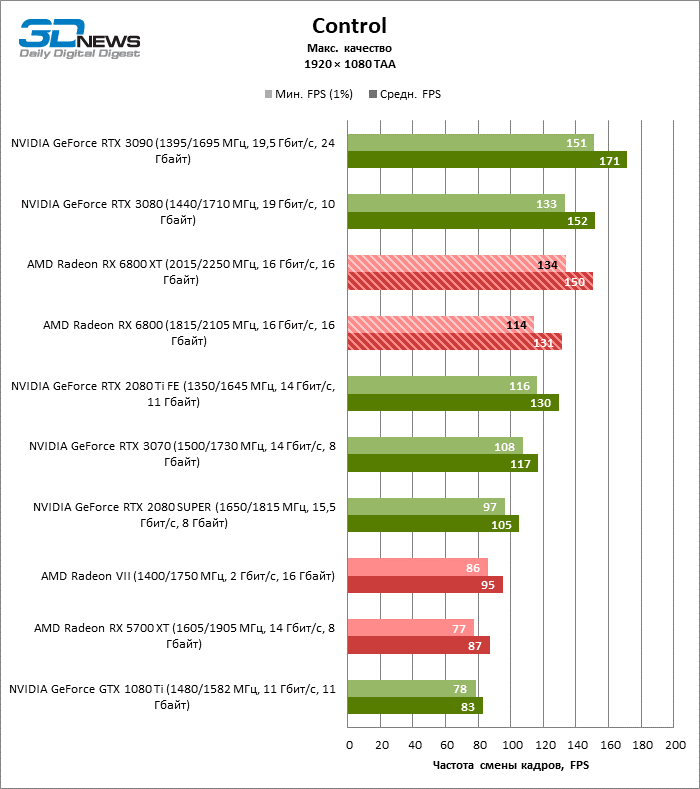
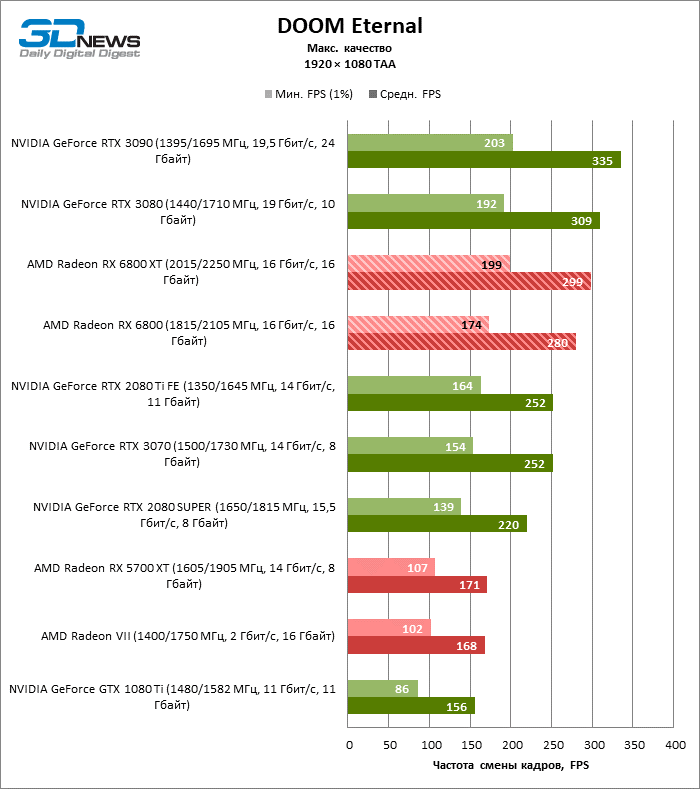
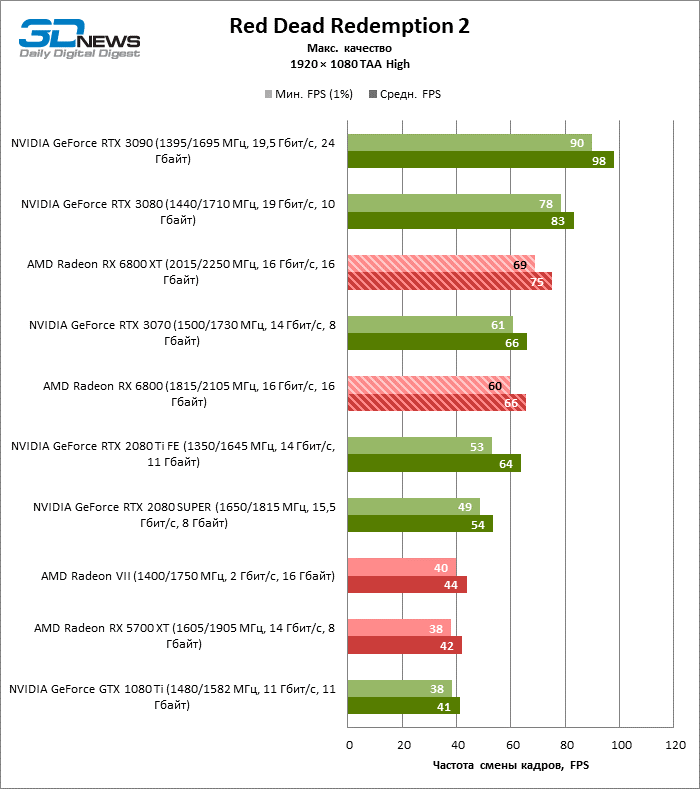
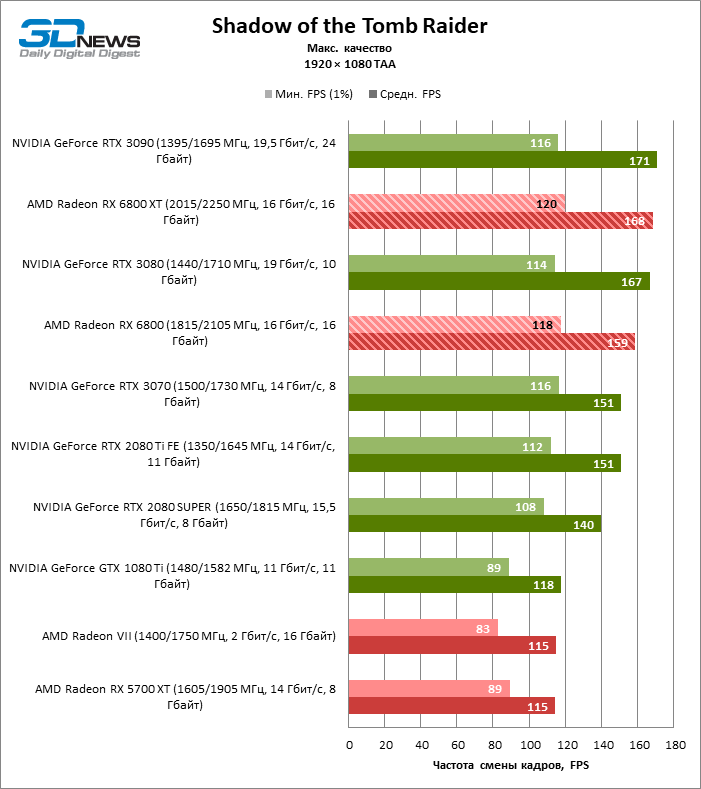
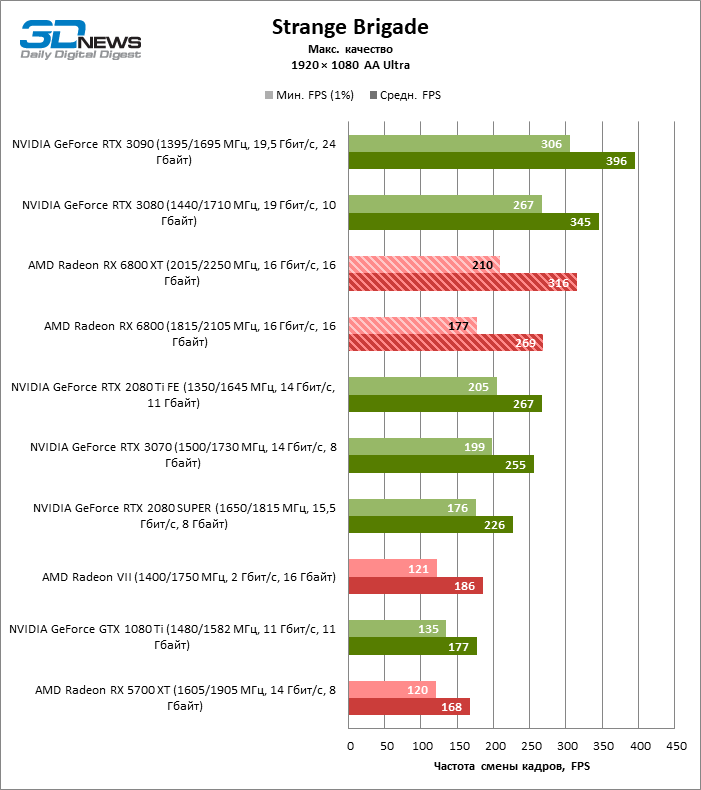
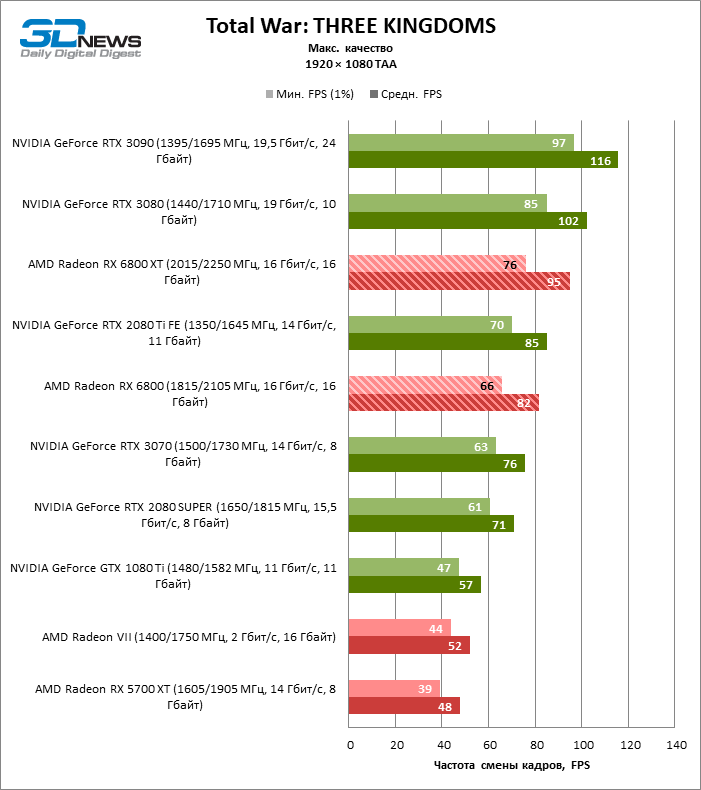
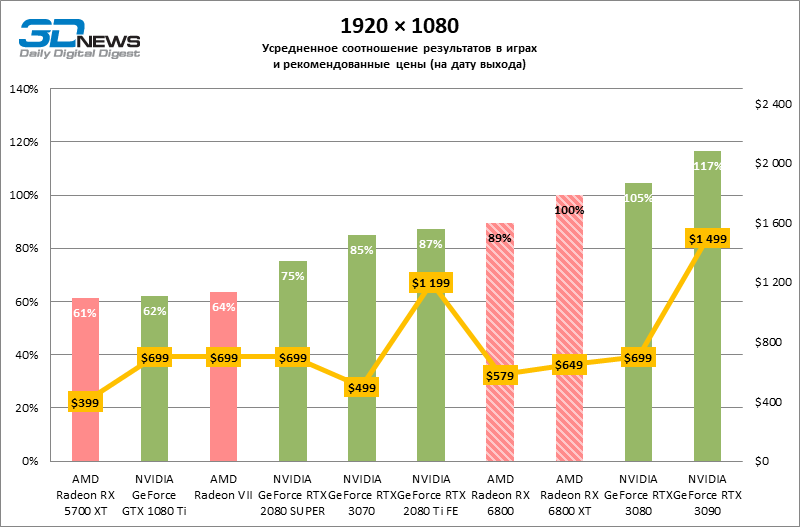
A julgar pelos dados do primeiro bloco de testes de jogos em 1080p, você pode ter certeza que um milagre não aconteceu: em dois entre dez jogos de teste (Battlefield V e Borderlands 3), o Radeon RX 6800 XT superou o GeForceRTX 3080 em termos de taxa de quadros média, mas a proporção média dos resultados ainda é -Assim, inclina 5% FPS para NVIDIA, e GeForce RTX 3090 já está 17% à frente.
Além disso, atualizar a Radeon RX 5700 XT ou GeForce GTX 1080 Ti para a Radeon 6800 XT fornece um aumento sólido de 63 ou 61% FPS, mas o desempenho duplo prometido em comparação com a Radeon RX 5700 XT (e, consequentemente, a Radeon VII) ainda não cheira mal. No entanto, não vamos tirar conclusões precipitadas, porque os testes com uma resolução de 1920 × 1080 não revelaram as verdadeiras diferenças entre GPUs de categorias de peso tão distantes por muito tempo. Por fim, ou os drivers do “big Navi” ainda estão úmidos ou havia um ponto fraco na arquitetura com o Infinity Cache, mas há uma anomalia entre os jogos de teste: o desempenho de Assassin’s Creed Odyssey praticamente não é afetado pela mudança da resolução entre 1080p e 1440p, então a taxa de quadros dos aceleradores é de 6000 A primeira série parece claramente discreta.
O resto da versão básica do Radeon RX 6800 cumpriu todas as tarefas atribuídas a ele. Sim, o XT oferece, em média, mais 12% de FPS, mas mesmo sem isso o RX 6800 supera o GeForce RTX 2080 SUPER em 19% e está separado dos rivais mais próximos – o RTX 2080 Ti e o RTX 3070 – em 3 e 5% da taxa de quadros média, respectivamente …
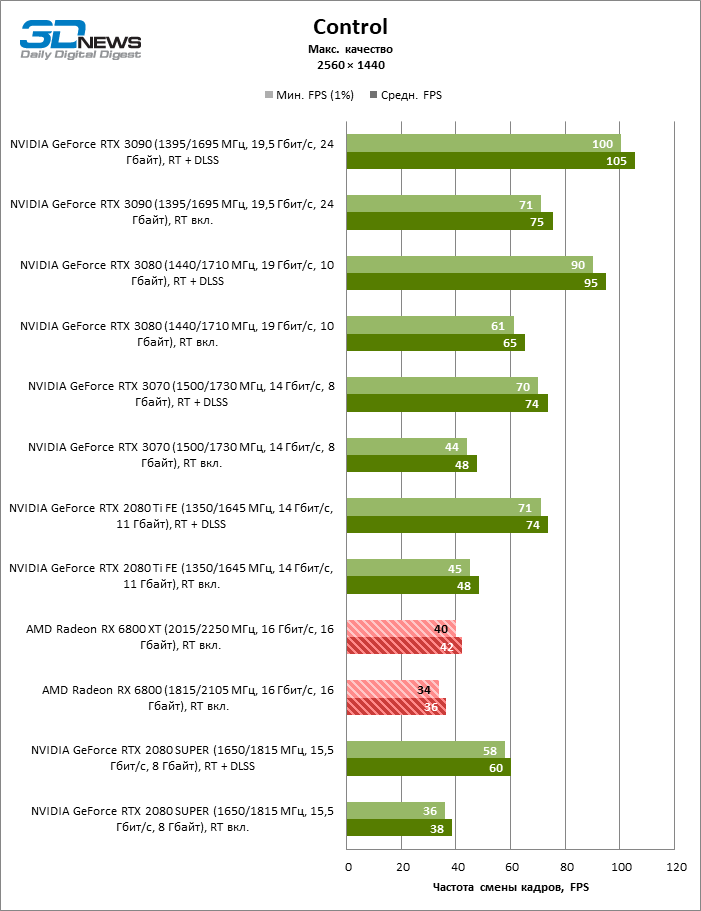
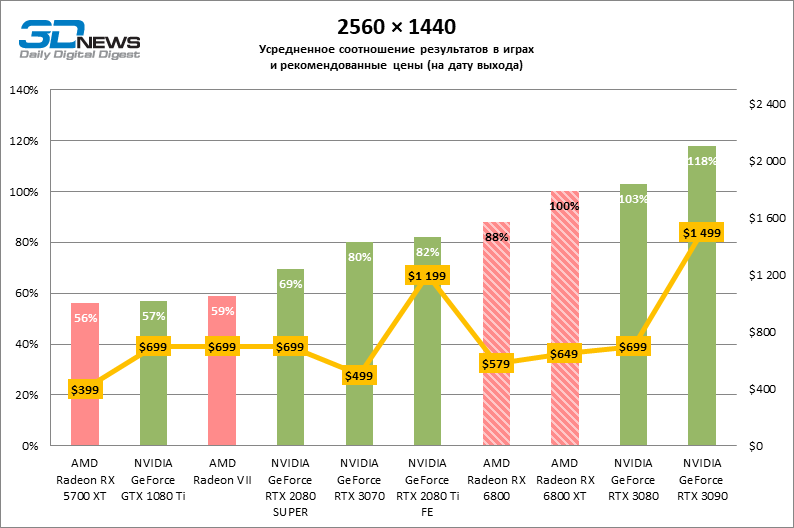
⇡#Testes de jogo (2560 × 1440)
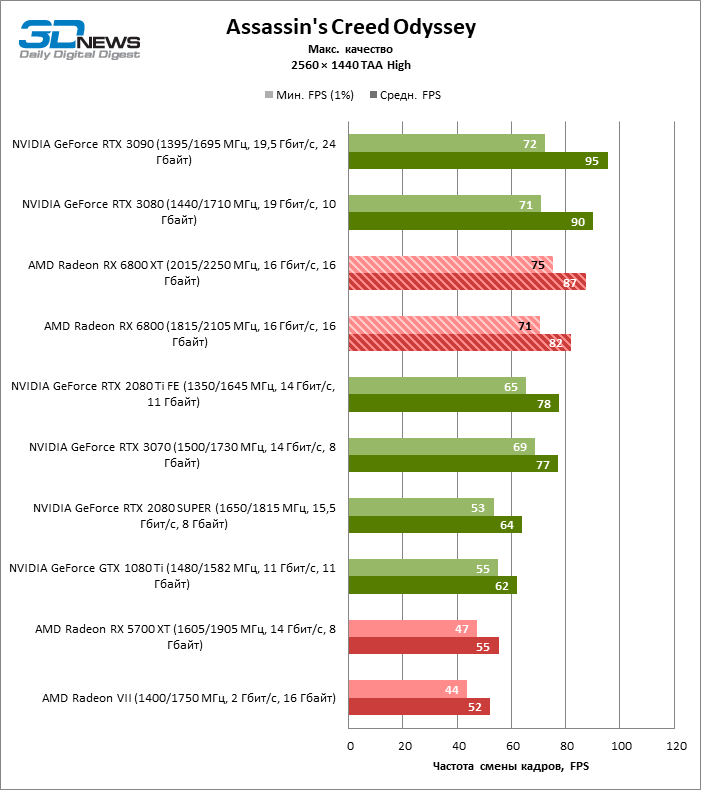
Desnecessário dizer que os testes de placas de vídeo da categoria de mais alto desempenho, à qual o Radeon RX 6800 XT pertence, dizem pouco sobre suas reais capacidades. Assim que a resolução foi alterada para 2560 × 1440, a distância entre a 6800 XT e as placas de vídeo da geração anterior aumentou dramaticamente. Se tomarmos para comparação o grupo denso, que inclui a Radeon RX 5700 XT, a Radeon VII e a GeForce GTX 1080 Ti, encontramos na lateral da Radeon RX 6800 XT uma vantagem de 70 a 78% na taxa de quadros. No entanto, as posições das placas de vídeo NVIDIA série 30 mais antigas ainda são inabaláveis: o RTX 3080 supera o 6800 XT em 3% FPS, o RTX 3090 em 18.
O aumento na resolução da tela também beneficiou o modelo básico Radeon RX 6800: ele foi à frente das placas de vídeo verdes mais próximas – GeForce RTX 2080 Ti e RTX 3070 – em 7 e 10% da taxa de quadros média, respectivamente, e superou o RTX 2080 SUPER não menos que 27% FPS.
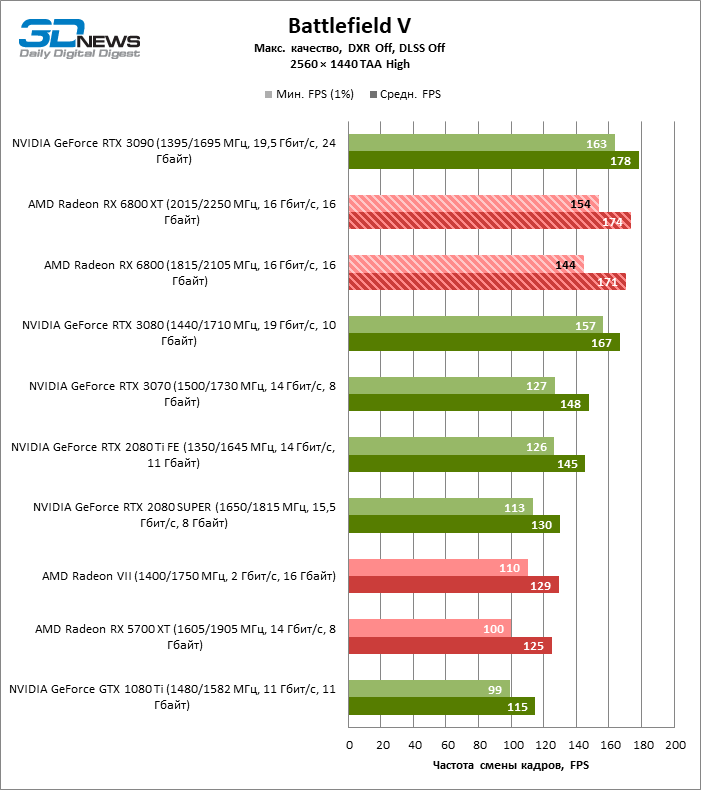
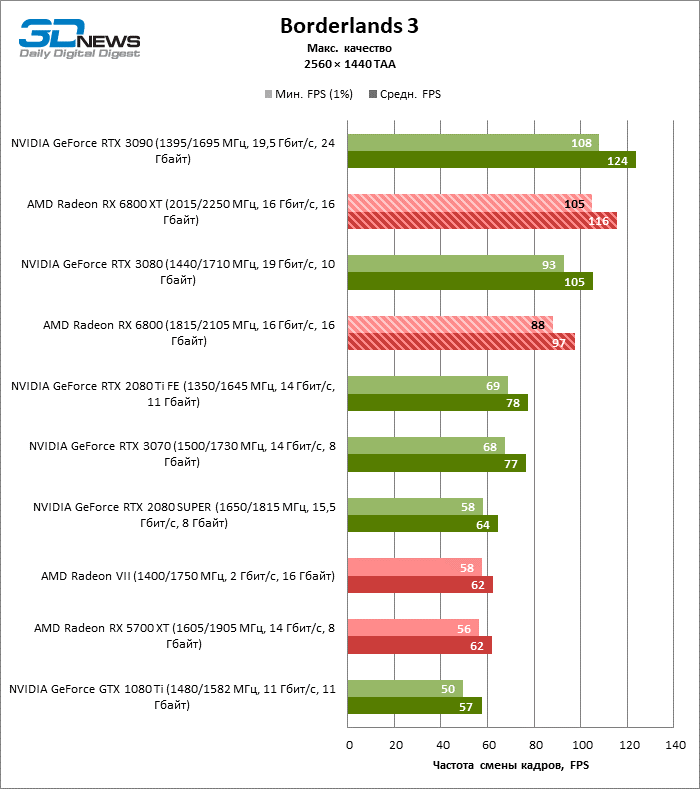
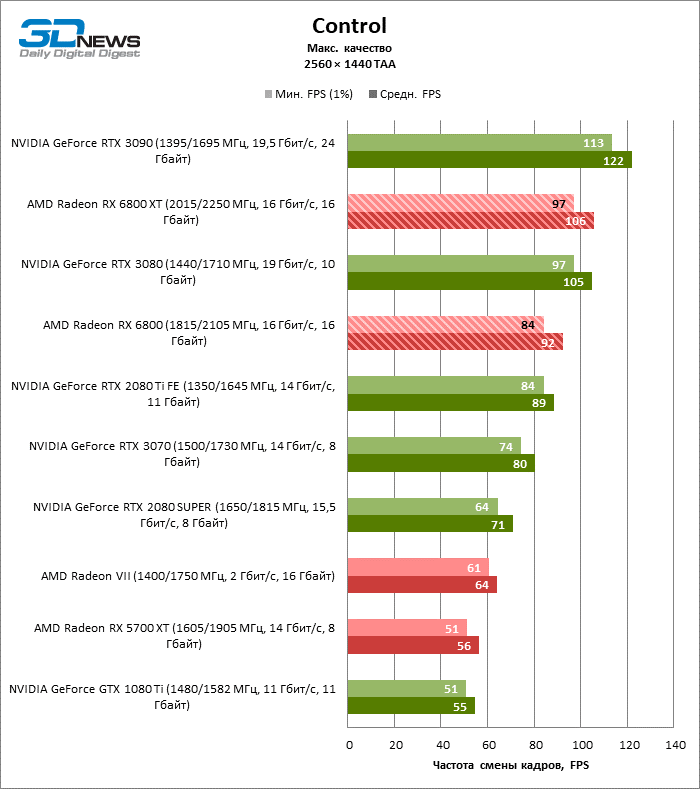
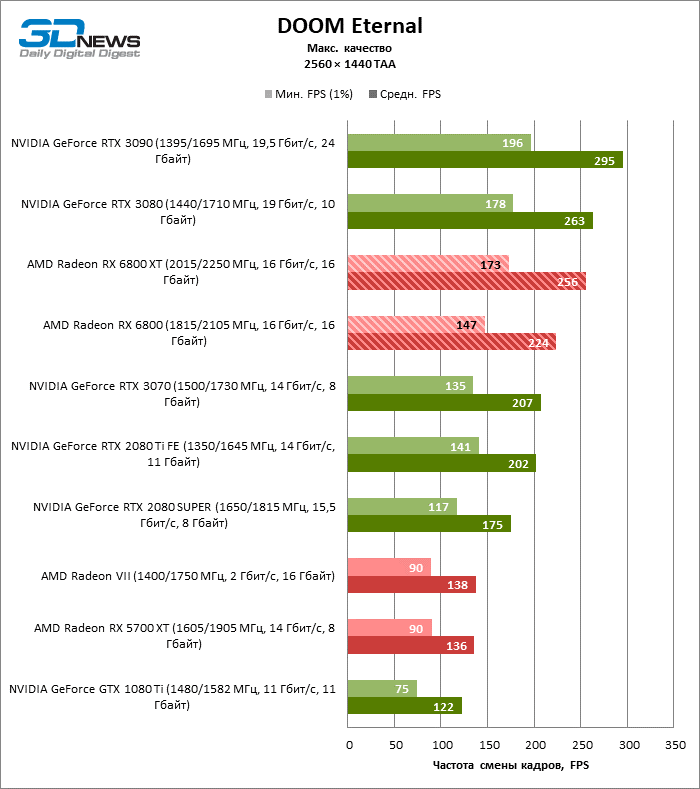
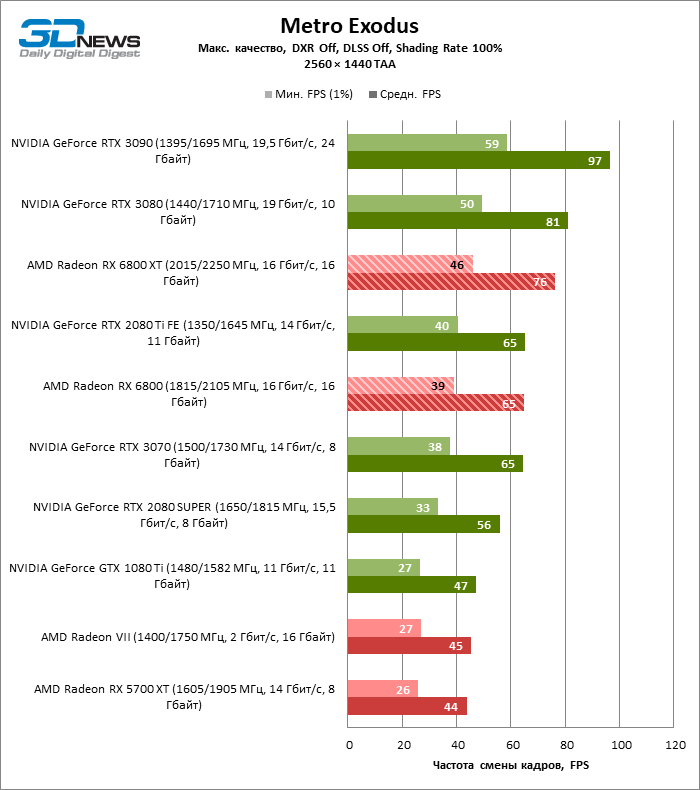
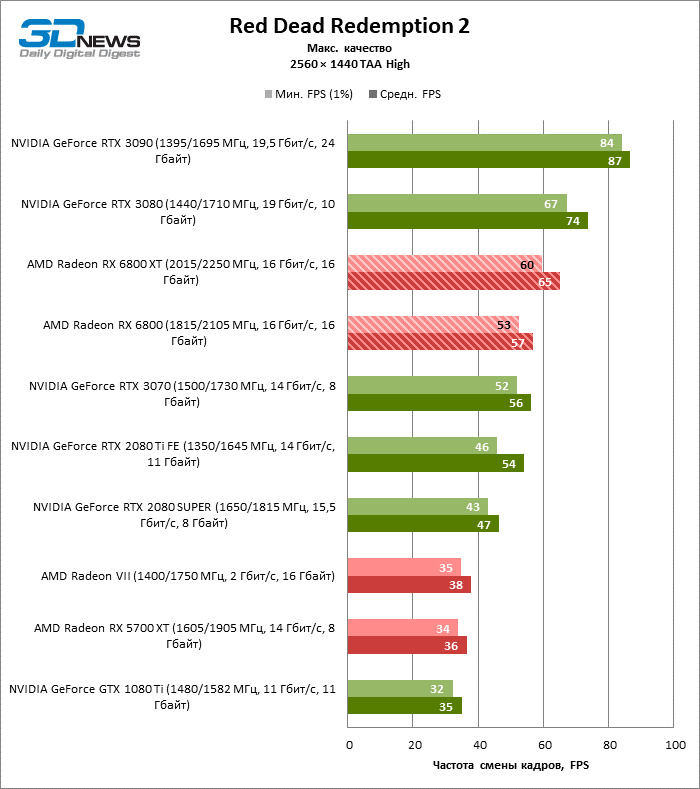
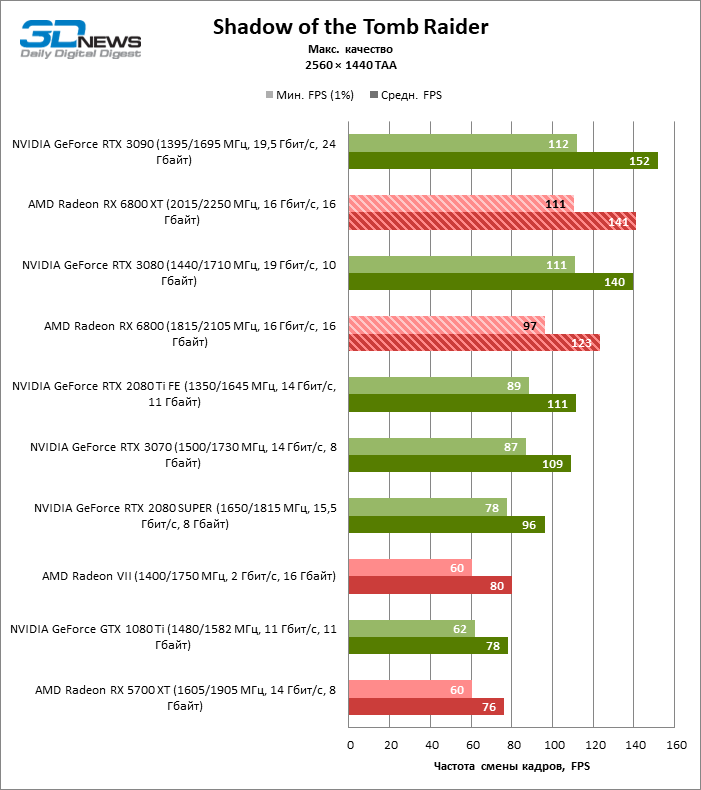
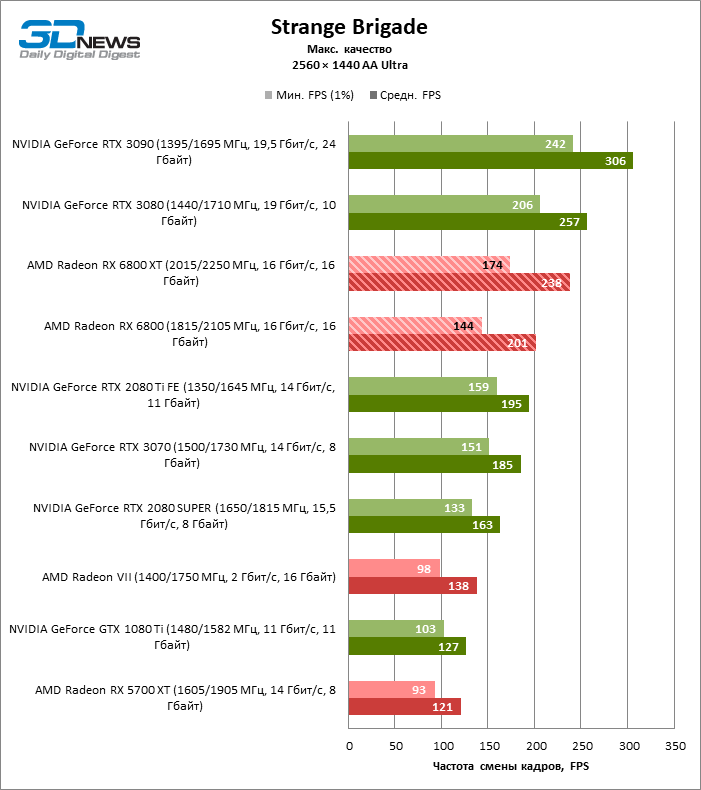
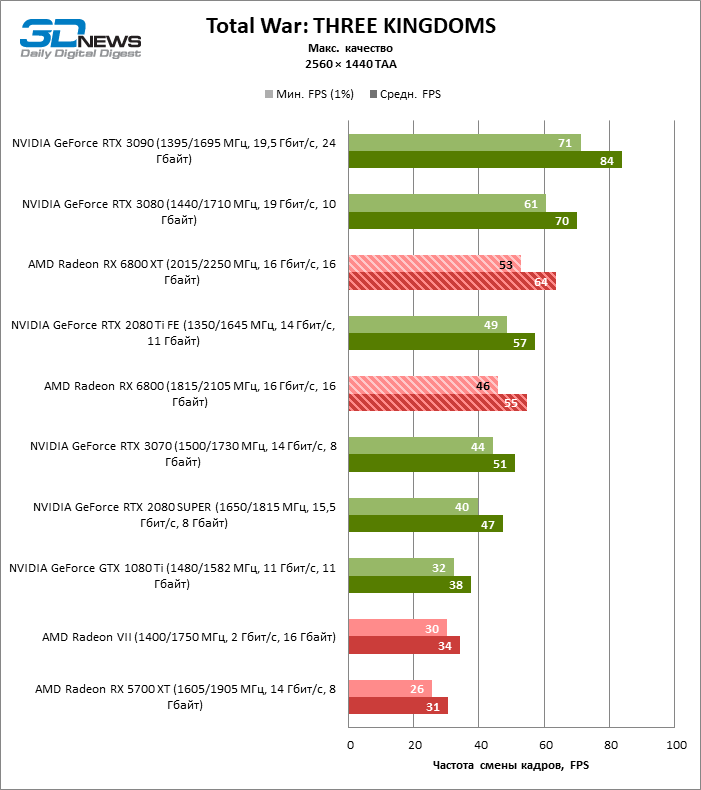
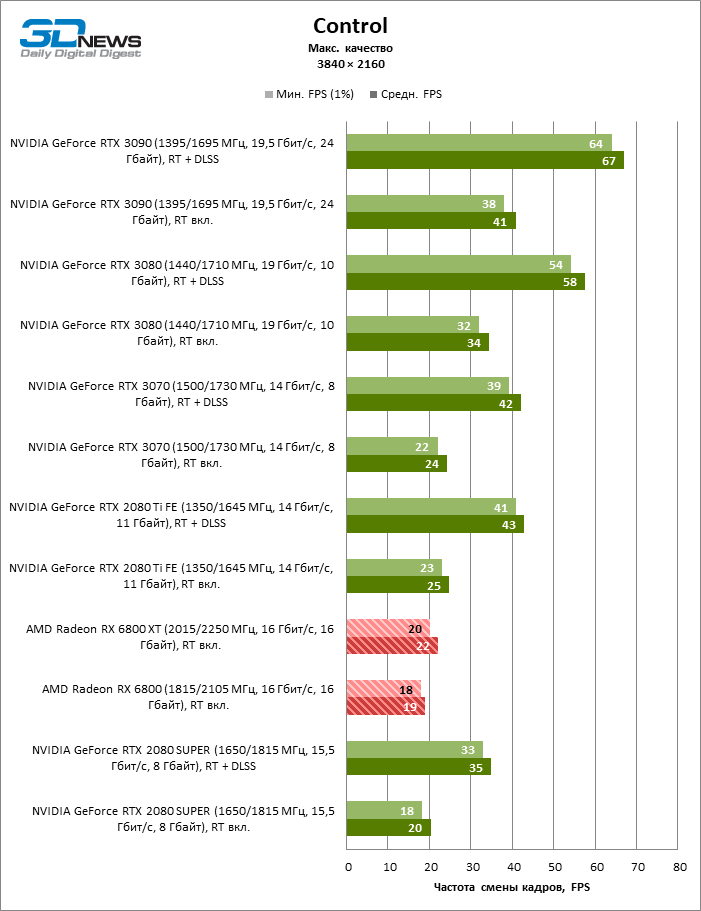
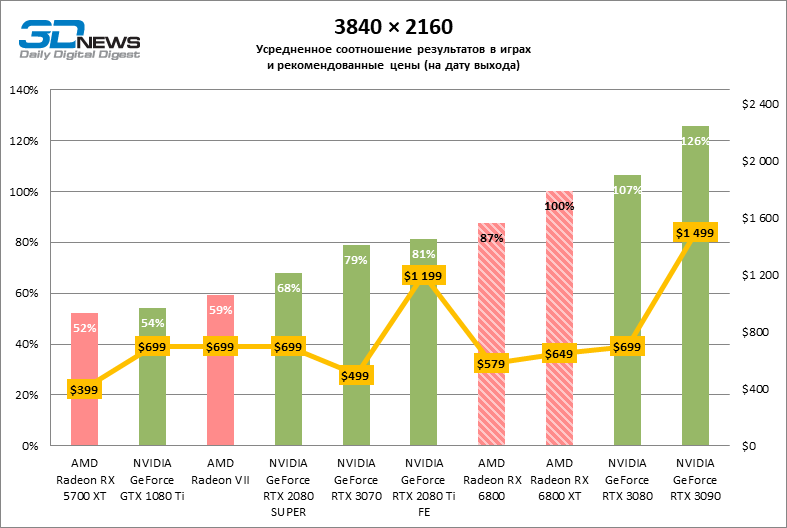
⇡#Testes de jogos (3840 × 2160)
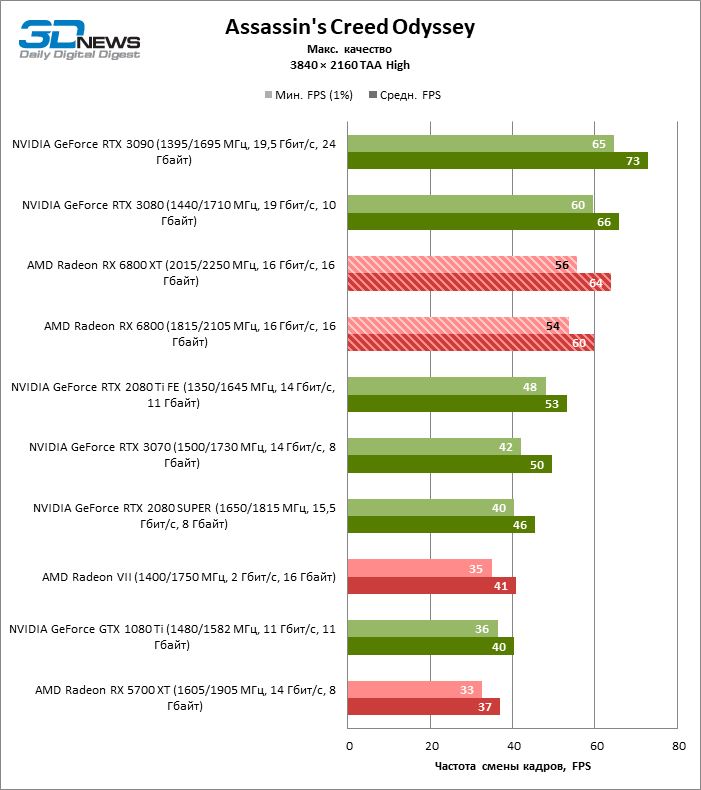
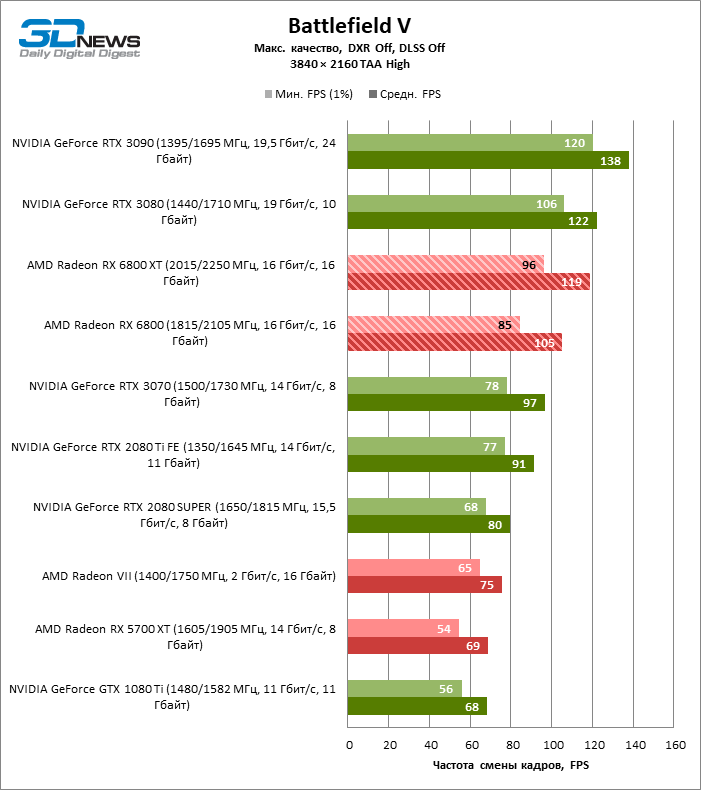
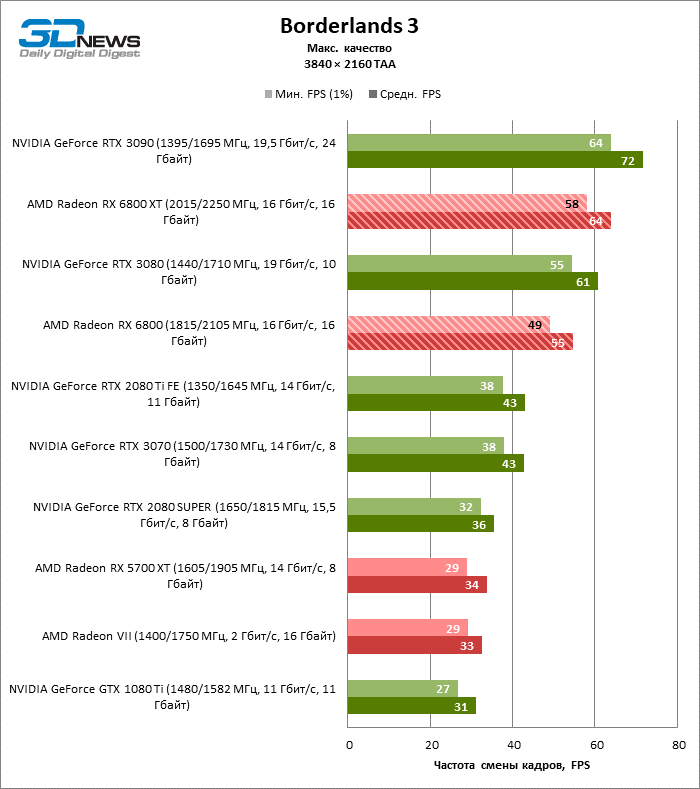
Quanto a se a Radeon RX 6800 XT é adequada para jogar títulos modernos em 4K com configurações gráficas máximas, podemos dizer sobre a mesma coisa que foi dita anteriormente sobre a GeForce RTX 3080. Apenas em seis entre uma dúzia de jogos de teste, a novidade manteve a frequência de deslocamento média quadros acima de 60 FPS, e ainda não iniciamos benchmarks com rastreamento de raio de hardware.
Por outro lado, aqui está o prometido aumento da taxa de quadros em dobro em comparação com a Radeon RX 5700 XT: 6800 XT dá, em média, 91% mais quadros por segundo. Placas de vídeo antigas com um amplo barramento de memória de 384 bits ou chips HBM2 têm melhor desempenho: a nova Radeon supera a GeForce GTX 1080 Ti e a Radeon VII em 85 e 69% FPS, respectivamente.
No entanto, se pegarmos um concorrente mais digno para a Radeon RX 6800 XT, os benchmarks 4K não ajudaram a inclinar a balança do lado da AMD: entre todos os títulos, apenas Borderlands 3 ainda prefere o acelerador “vermelho” e, nos testes de jogo agregados, deram a vitória do GeForce RTX 3080 com uma vantagem de 7% FPS. A GeForce RTX 3090 – a única placa de vídeo que pode lidar com jogos em 4K sem qualquer compromisso – conduz em 24% FPS.
Mas para o Radeon RX 6800 sem o console XT, as coisas ainda estão indo por água abaixo. Ele se afastou dos perseguidores mais próximos – GeForce RTX 2080 Ti e GeForce RTX 3070 – por 8 e 11% FPS, respectivamente.


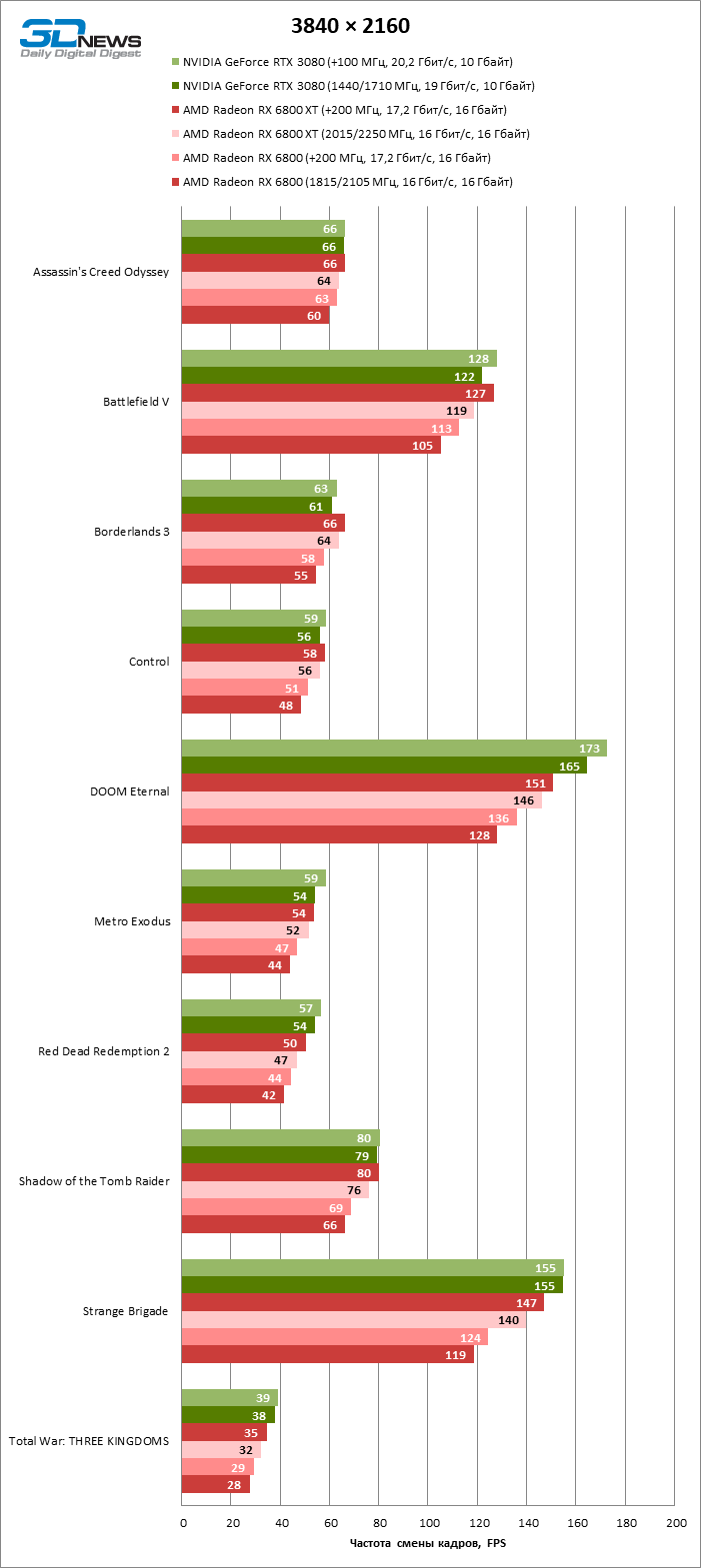
⇡#Testes de jogos com overclock
Quaisquer que sejam as frequências de clock que as placas de vídeo modernas alcancem em overclocking, esta ocupação há muito perdeu seu significado prático quando se trata de propostas do mais alto escalão em termos de preço e desempenho. O overclock da GPU e da RAM deu, em média, 5% FPS aos dois novos produtos da AMD. Isso ajudou a Radeon RX 6800 XT a fechar a lacuna com a GeForce RTX 3080 para 2%, mas não vamos perder de vista o fato de que o próprio RTX 3080, embora não tão bem, ainda está em overclock. Quando ambos os competidores estão trabalhando em velocidades de clock mais altas, um gap de 5% FPS reaparece entre eles.
Testes de jogos Ray-tracing
As placas gráficas Radeon série 6000 são totalmente compatíveis com jogos que contam com a Interface de Programação Universal DXR ou extensões Vulkan para renderizar efeitos rastreados. Mas, como se viu, existem títulos que estão vinculados ao hardware NVIDIA e se recusam a funcionar em aceleradores AMD – esta é uma versão beta rastreada do Minecraft e Quake II RTX. Não sabemos o quão profundamente os dois jogos estão enraizados no ecossistema NVIDIA: talvez uma simples verificação da placa de vídeo na lista os impeça de rodar no Radeon 6000, ou, ao contrário, eles contêm chamadas CUDA ou NVAPI, e então a entrada para o “vermelho” é fechada para sempre. Afinal, o que mais você pode esperar de jogos com a sigla RTX no título?
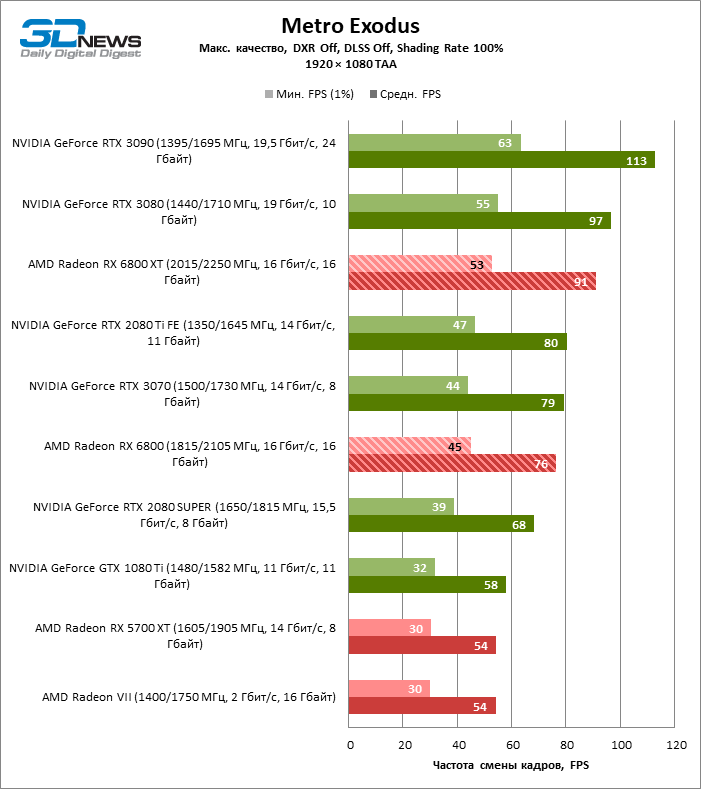
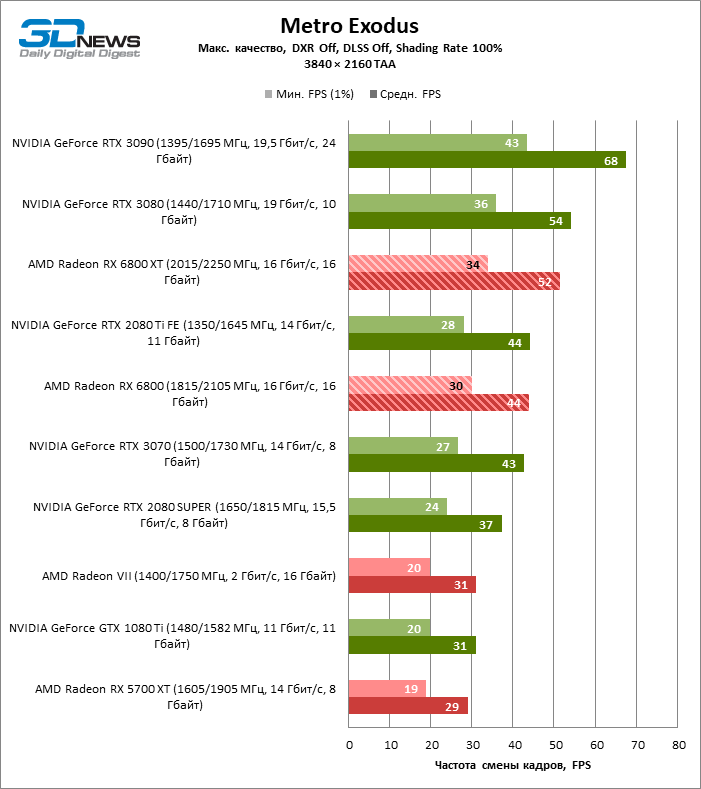
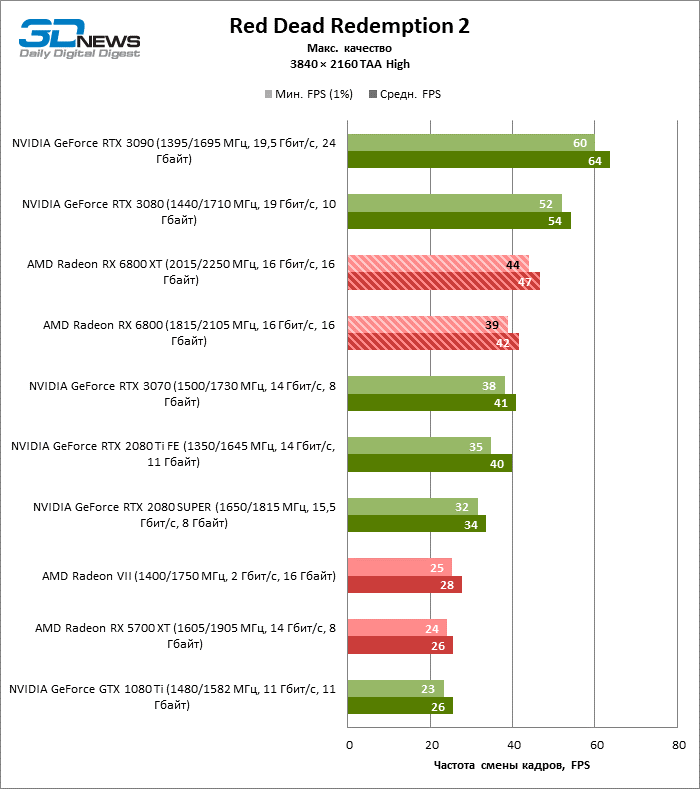
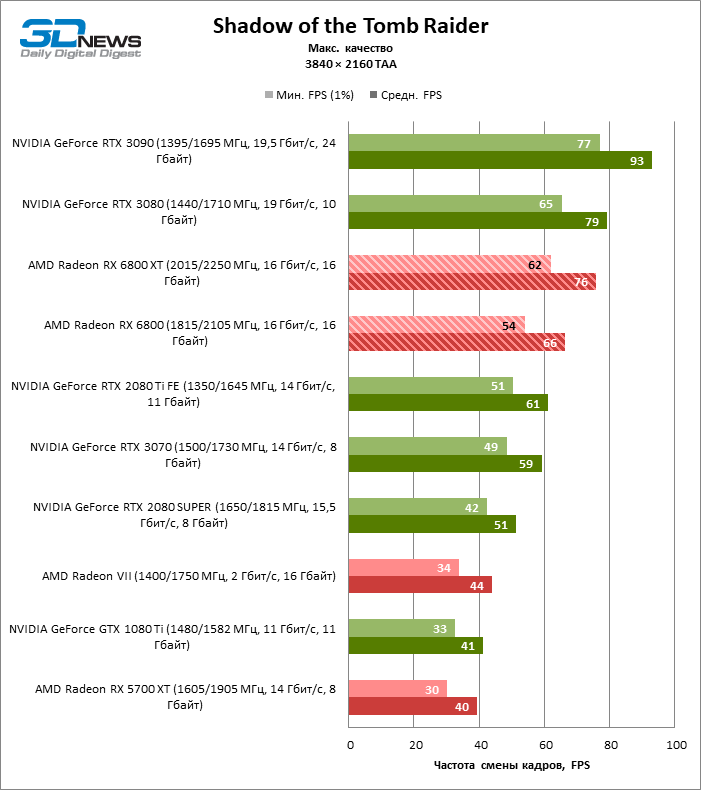
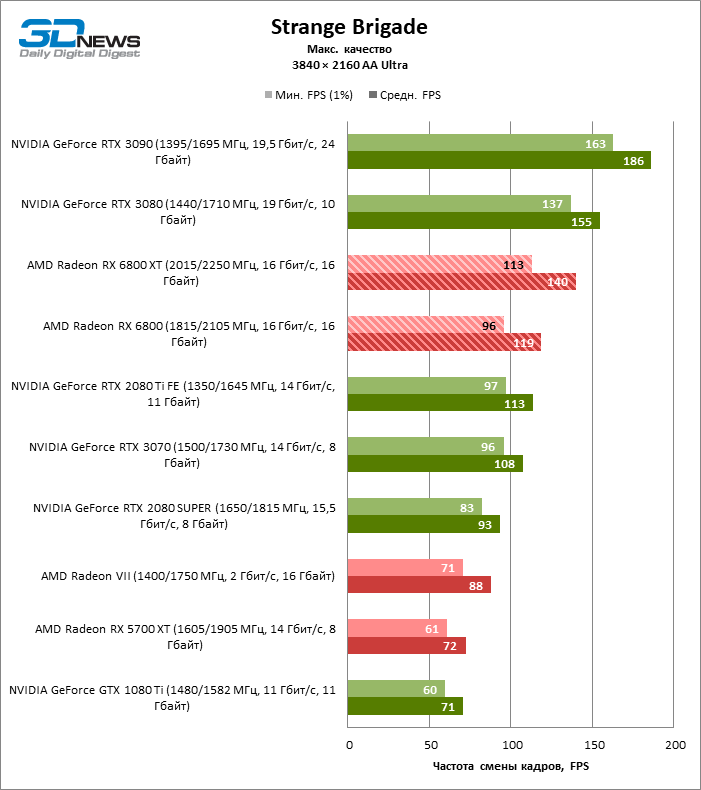
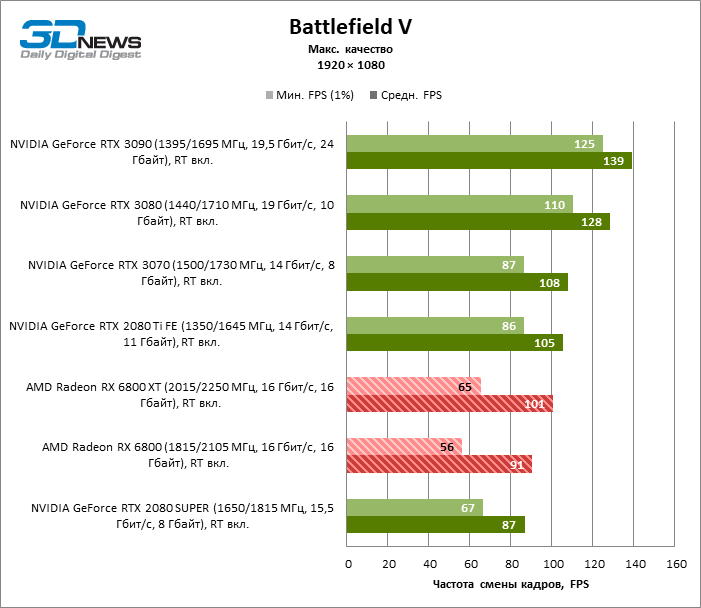
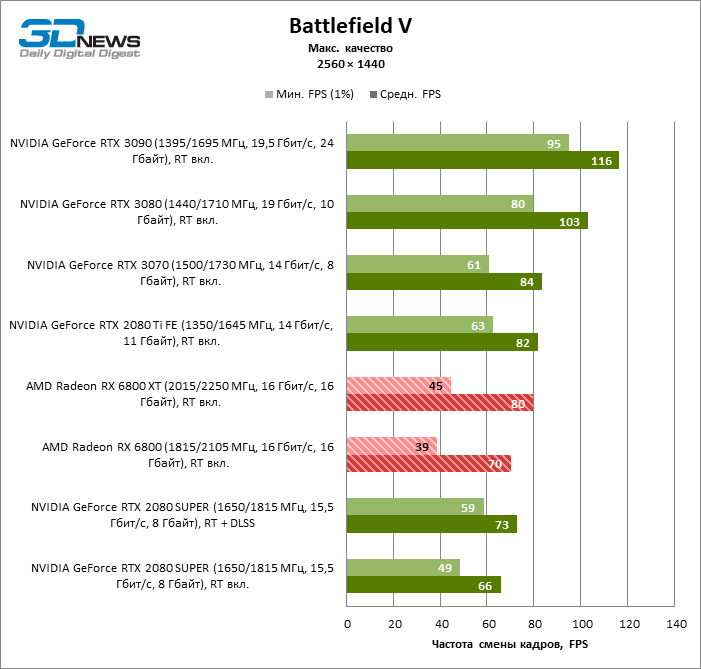
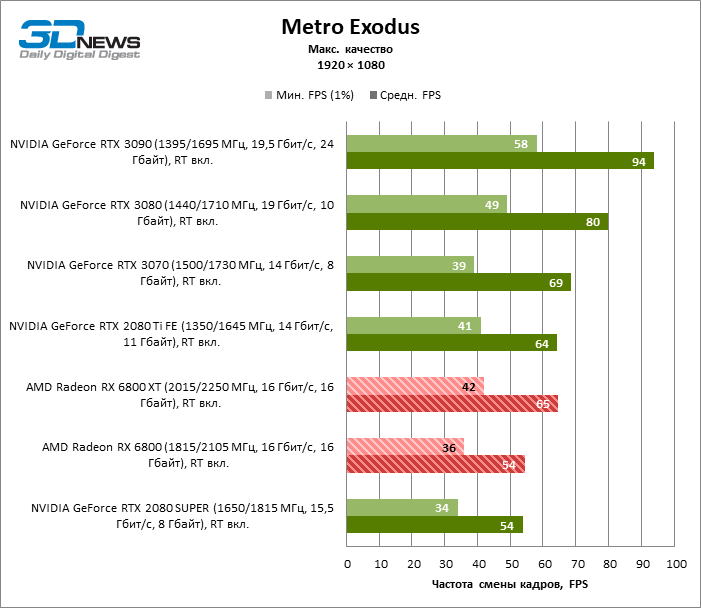
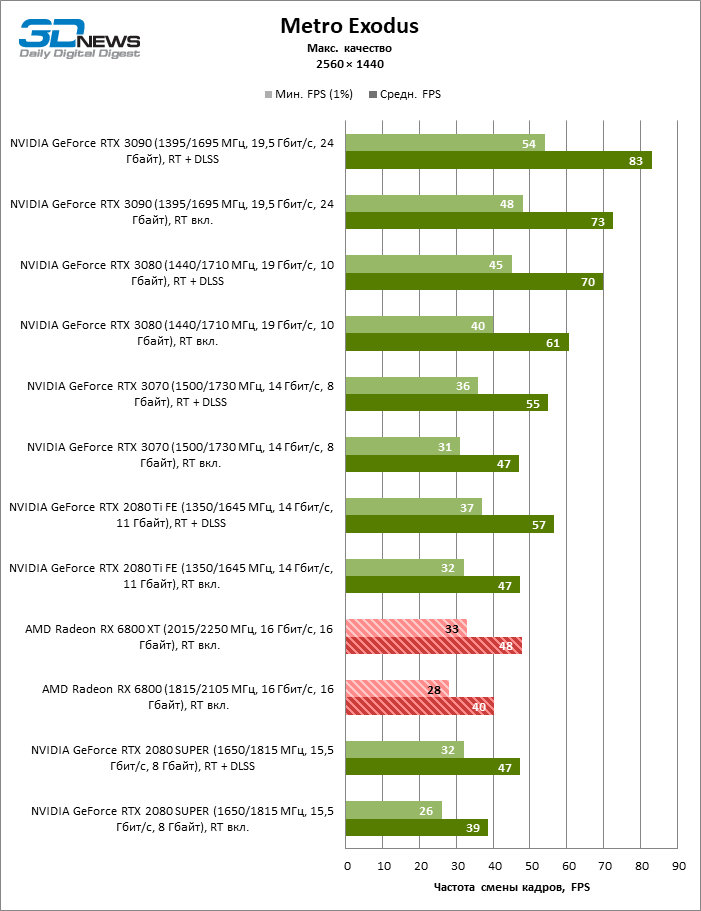
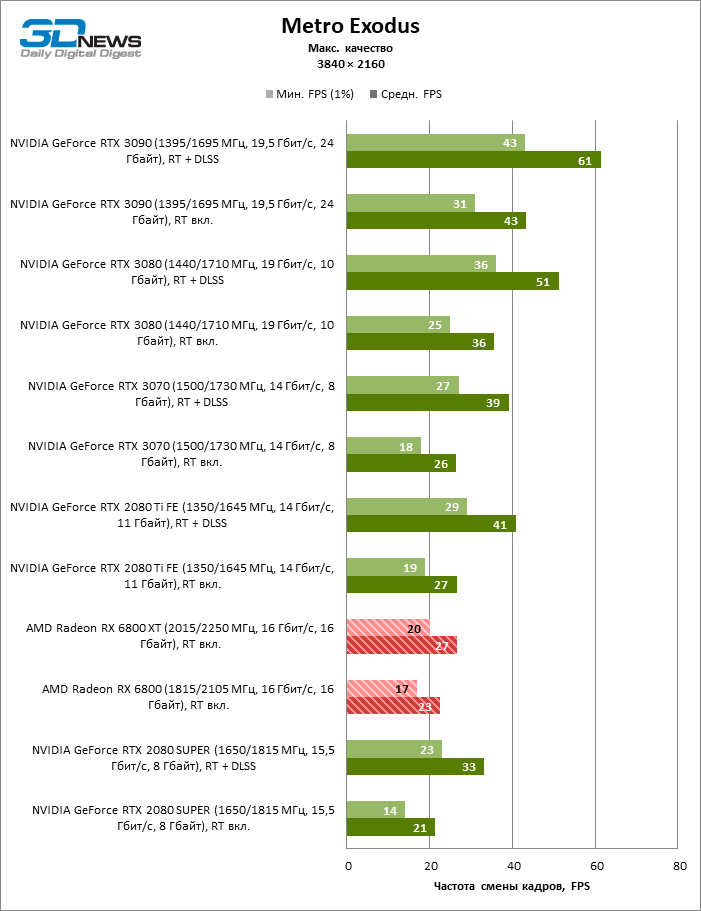
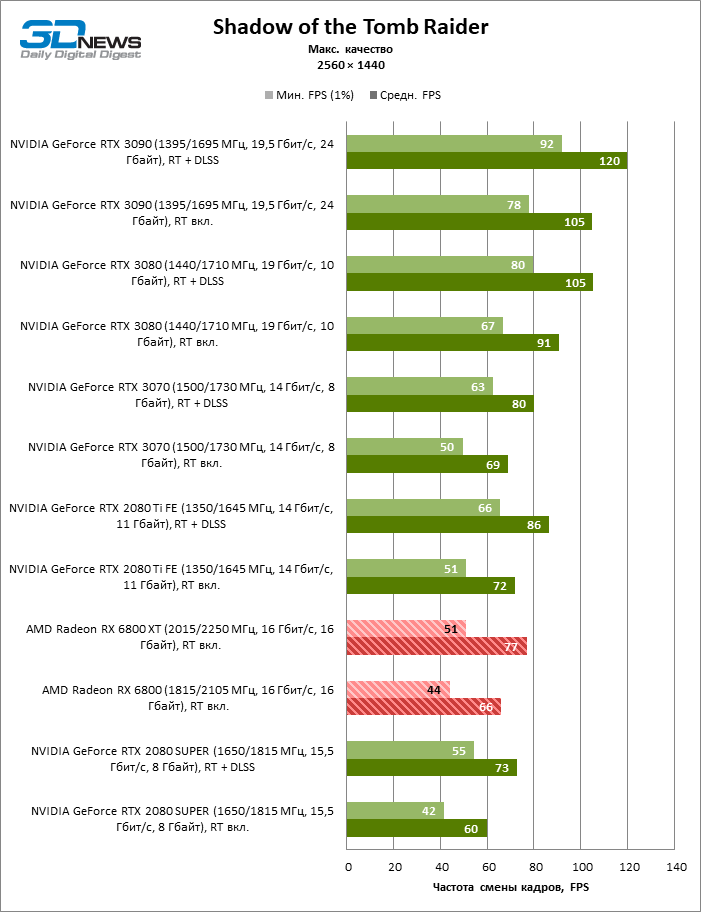
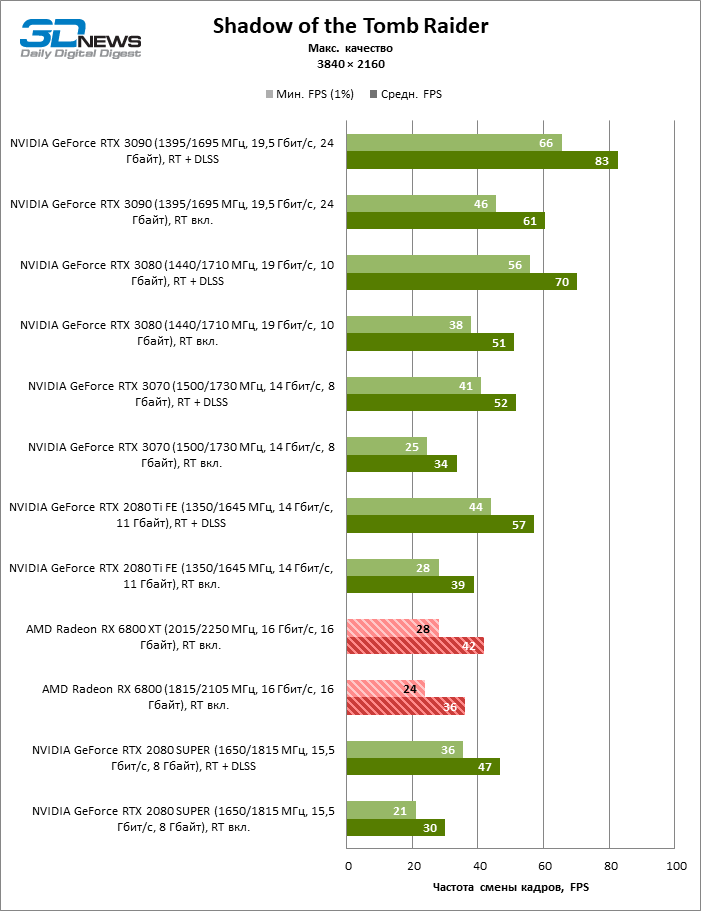
Quatro jogos permanecem na lista de benchmarks que, ao contrário do Minecraft com RTX e Quake II RTX, não contêm um ambiente totalmente rastreado e contam com um modelo híbrido de compromisso, quando o traçado de raios é usado apenas para renderizar os efeitos selecionados: sombras, reflexos, iluminação global, etc. etc. Seja como for, os resultados do teste mostram claramente que o hardware AMD está uma geração atrás dos concorrentes na velocidade de RT acelerado por hardware. Dependendo da resolução, a GeForce RTX 3080 supera a Radeon RX 6800 XT em 30-38% FPS, e a vantagem do RTX 3090 é de 43-64% FPS. Eles são apenas uma classe de peso diferente quando se trata de jogos DXR.
A GeForce RTX 2080 Ti e RTX 3070 são os temas certos para comparar com a Radeon RX 6800 XT. O acelerador da AMD regularmente os supera no Shadow of the Tomb Raider, indiscutivelmente a dose mais escassa de rastreamento de raios em nosso conjunto de testes. Mas no exigente Metro Exodus, ele conseguiu demonstrar um nível igualmente alto de desempenho e, em média, a vantagem do RTX 2080 Ti e RTX 3070 sobre o RX 6800 XT é reduzida para 2-6% FPS.
No entanto, o principal problema não é a falta de desempenho bruto, mas o fato de que a AMD ainda não possui uma tecnologia de upscaling semelhante ao DLSS (especialmente o DLSS versão 2.0). Com o aumento da carga que o traçado de raio cria, a GPU tem que lutar na resolução de tela inteira. Como resultado, mesmo no modo 1440p, o jogador não tem garantia de uma taxa de quadros superior a 60 FPS e, mesmo em 1080p com configurações de detalhes máximos, o Radeon RX 6800 XT se equilibra à beira de uma taxa de quadros confortável em títulos pesados como Metro Exodus e Controle.
Quanto à versão básica da Radeon RX 6800, seu análogo mais próximo entre as placas de vídeo NVIDIA participantes dos testes é a GeForce RTX 2080 SUPER. O RTX 3070, que sofreu uma derrota nos benchmarks sem ray tracing, lidera com uma vantagem média de 11-23%, e se separa do RX 6800 para a distância máxima precisamente a 1080p, que, aparentemente, os compradores do novo produto terão que aturar para lançar jogos de ponta com efeitos DXR.


⇡#Computação de uso geral
A AMD ainda precisa aperfeiçoar os drivers das placas de vídeo da série Radeon 6000, então o teste de estreia de novos produtos teve problemas de compatibilidade com certos aplicativos. Desta vez não foi possível executar a suíte de testes para o editor de vídeo Premiere Pro em um sistema com um Radeon RX 6800 (XT), portanto o Blender será o principal teste de suas capacidades no ambiente GP-GPU. Infelizmente, sem o rastreamento de raio acelerado por hardware: não conseguimos encontrar nem mesmo uma versão beta do plug-in ProRender com suporte a bloco Ray Accelerator compilado no Windows, e a integração com o mecanismo Cycles acontecerá em versões futuras do editor.
Como você pode esperar, as placas de vídeo para jogos da AMD não são mais tão fortes em aplicativos de produção como eram durante a arquitetura GCN. Mas se ajustarmos para o número de ALUs shader nos chips Navi 21 e GA102, os novos itens fizeram um excelente trabalho com o benchmark Cycles, ocorrendo entre a GeForce RTX 3070 e RTX 3080.
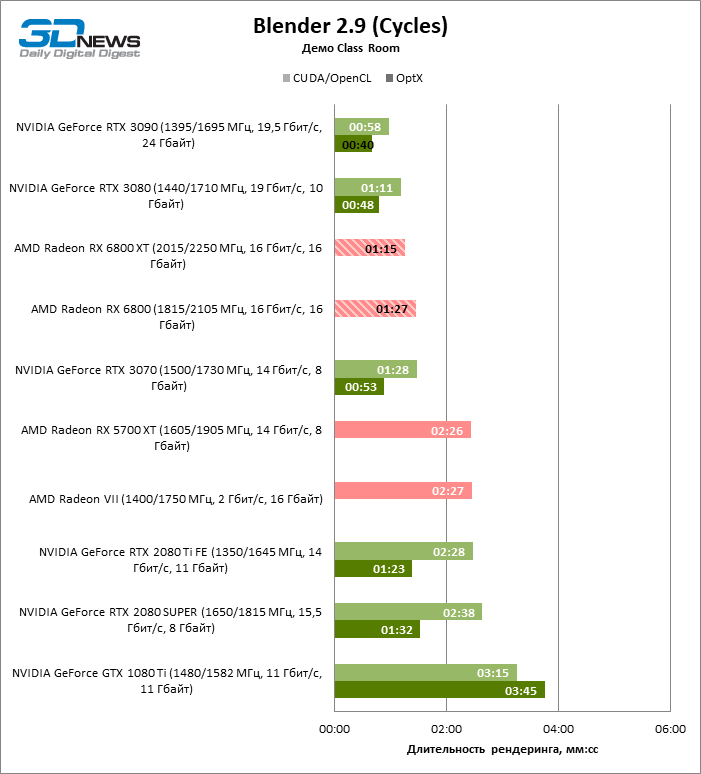
Na avaliação da velocidade da Radeon ProRender da versão mais antiga, a Radeon RX 6800 também obteve destaque após a GeForce RTX 3080 após derrotar a RTX 2080 Ti, mas a Radeon RX 6080 já cede à RTX 3070. O que é mais revelador, a RX 6800 XT em ambos os testes é quase dois tempo de renderização reduzido por vezes em comparação com a placa de vídeo prosumer da arquitetura GCN – Radeon VII.
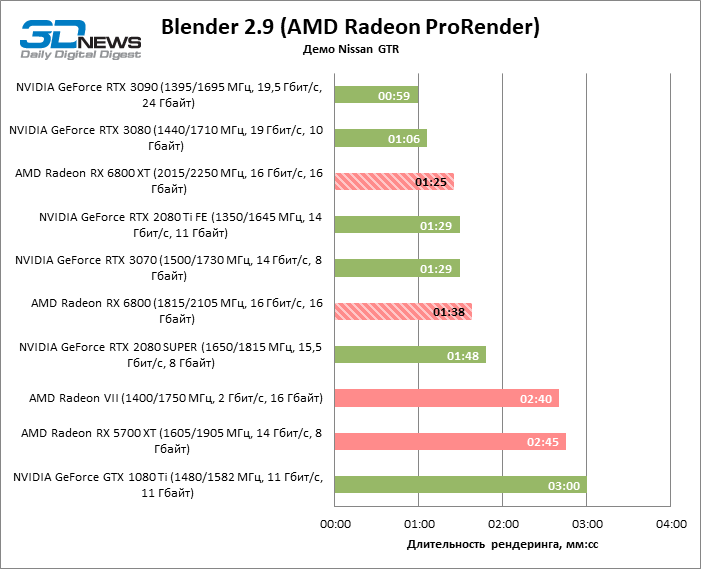
A decodificação de registros RED R3D é um teste completamente desfavorável para aceleradores AMD devido ao fato de que ele usa núcleos tensores NVIDIA para depuração de código-fonte, enquanto os chips Navi são forçados a transferir a tarefa para o processador central. Mas isso não é surpreendente, mas o fato de que os dois novos itens deram lugar à velha placa de vídeo Radeon VII.
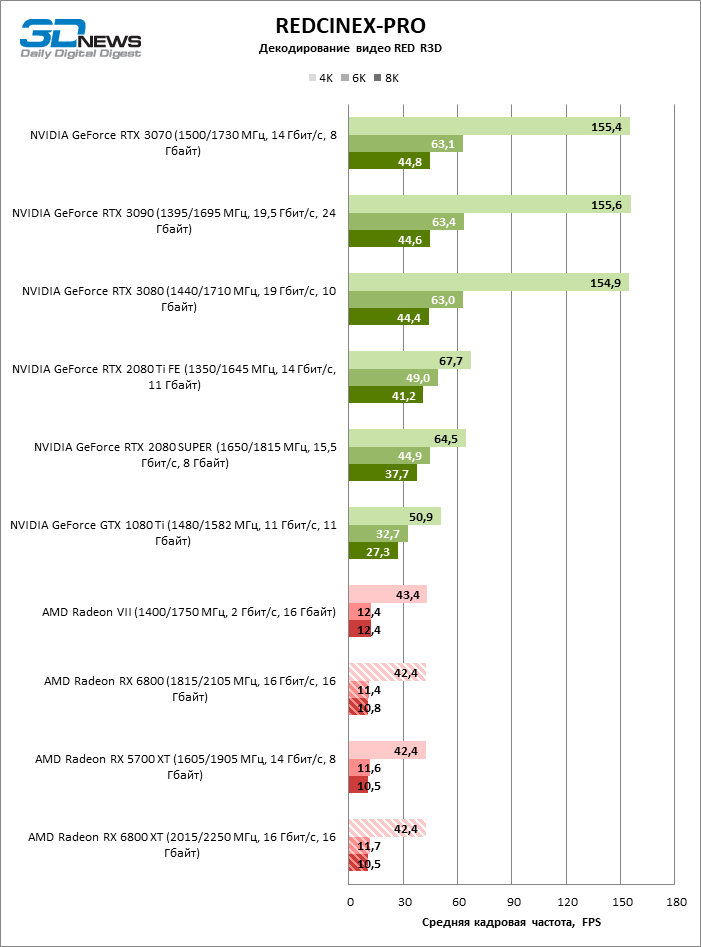
⇡#Codificação / decodificação de vídeo
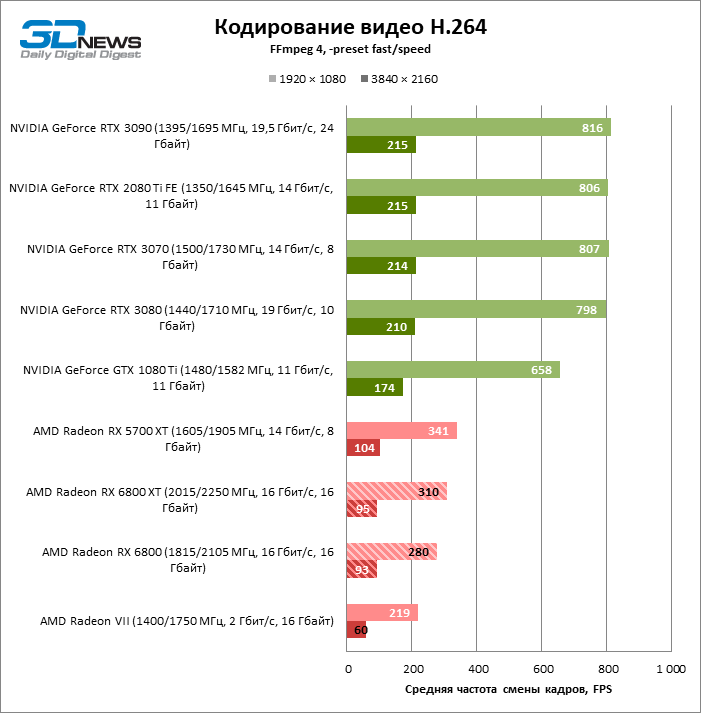
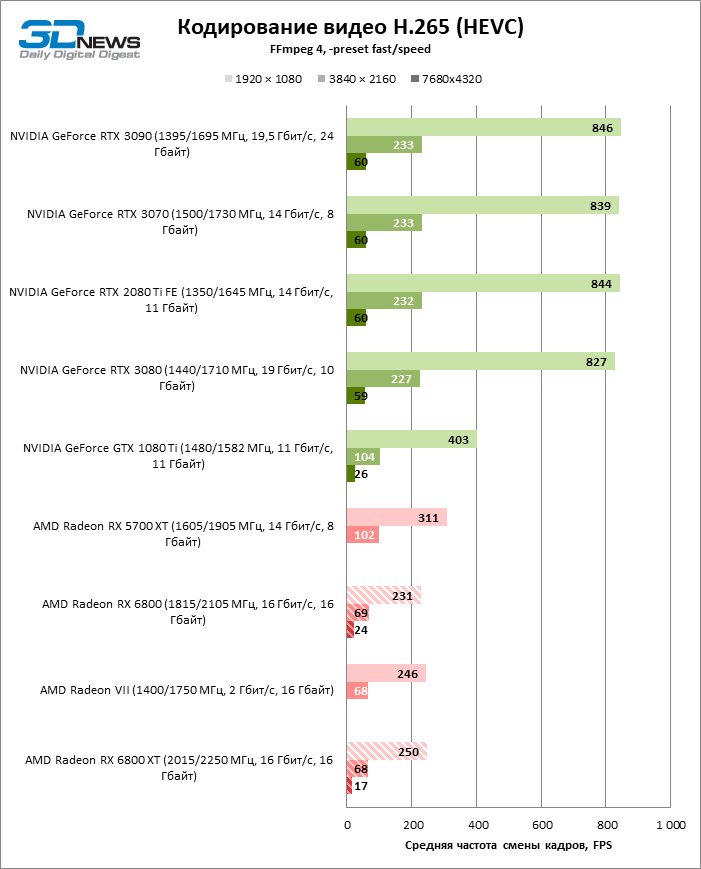
Embora a AMD não esteja falando sobre nenhuma mudança no ASIC dedicado para decodificação de vídeo, o Radeon RX6800 melhorou a velocidade de processamento dos formatos H.264, HEVC e VP9. Às vezes é bastante significativo, embora tenha conseguido arrancar a palma das mãos da NVIDIA apenas no teste do codec H.264. Felizmente, o desempenho do bloco de mídia Navi 21 é o suficiente para decodificar HEVC e VP9 mesmo em resolução de 8K com uma taxa de quadros de 46–49 FPS.
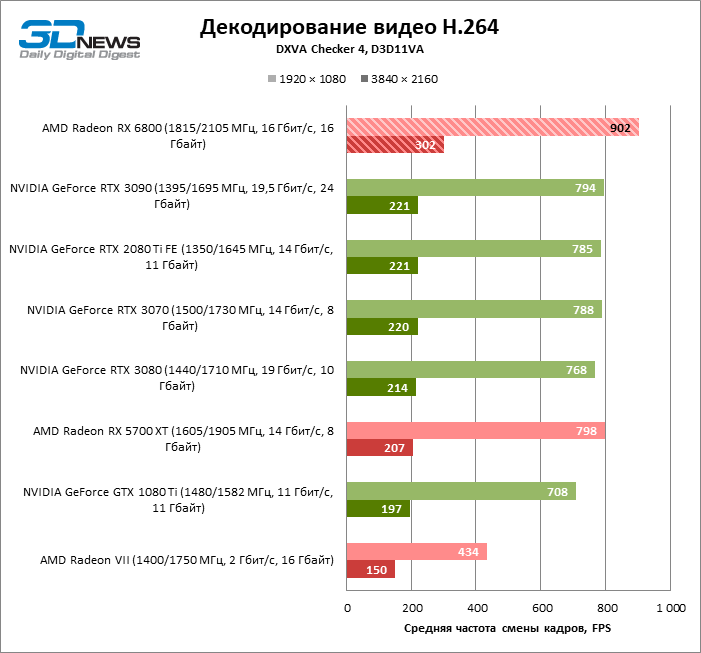
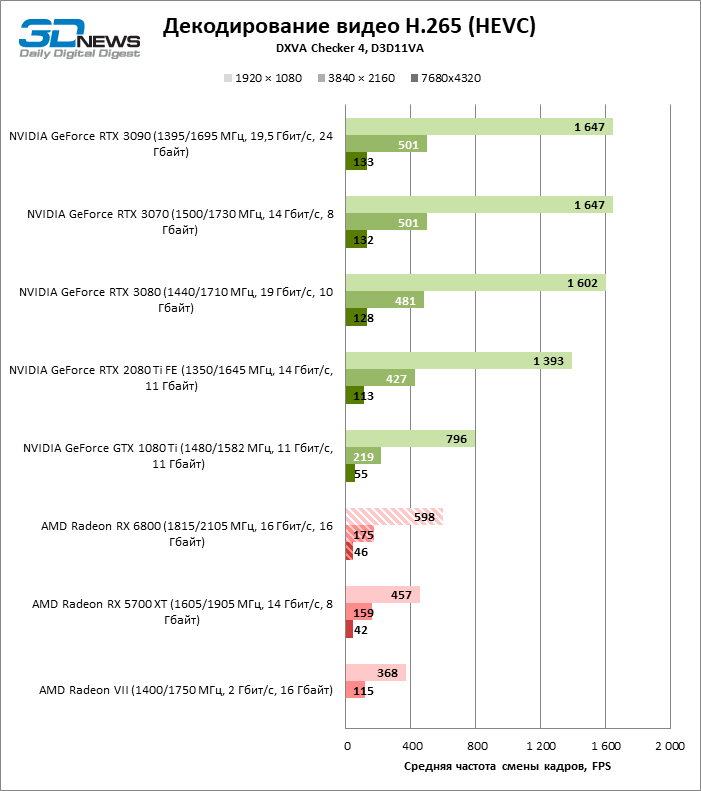
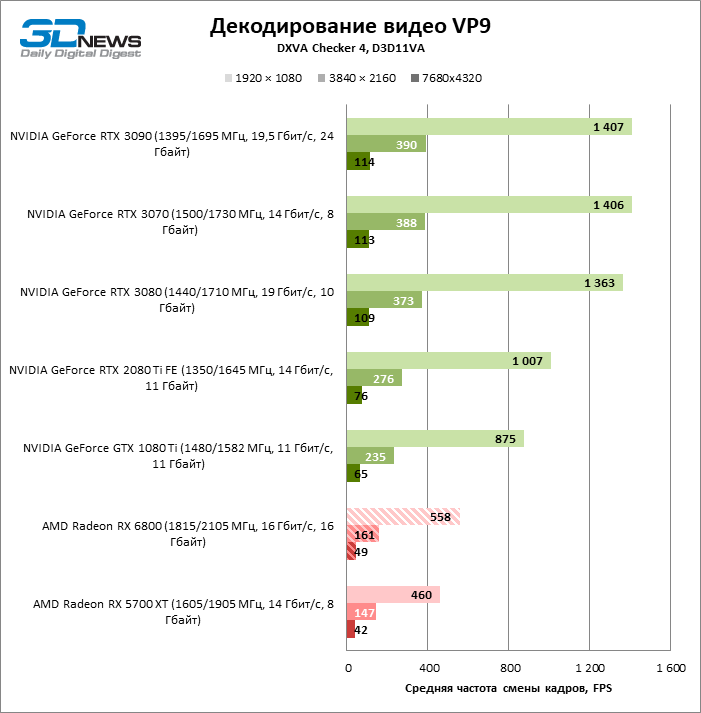
A novidade processa o formato AV1 avançado e extremamente intensivo em recursos quase à mesma velocidade. Sim, 60 FPS está fora de questão, mas o conteúdo de 8K em si ainda é uma raridade.
No lado da codificação, o Navi 21 adquiriu a capacidade de criar arquivos HEVC com resolução de 8K. Mas parece que os problemas com a operação do decodificador, sofridos pelos primeiros drivers das placas de vídeo da série 5000, voltaram: agora os novos aceleradores exportam vídeo mais devagar do que os antigos.
Desempenho por watt e área de GPU
Embora a AMD afirme que o silício Navi 21 em eficiência energética é 54% superior ao chip Navi 10 da geração anterior, ele ainda tem uma vantagem de 38% sobre o Radeon RX 5700 XT, que foi demonstrado pelo Radeon RX 6800 XT dentro da mesma norma de 7 nm. é uma grande conquista. Mais importante ainda, a paridade há muito perdida de desempenho de jogos por watt entre dispositivos NVIDIA e AMD próximos foi finalmente restaurada: neste, o RX 6800 XT e o GeForce RTX 3080 são praticamente equivalentes, embora o RTX 3090 baseado no chip GA102 quase intocado tenha uma vantagem 7. %.
Ao mesmo tempo, a versão básica do Radeon RX 6800 sem o console XT, ao contrário de nossas expectativas, não só não é inferior ao modelo anterior, mas também o supera em eficiência energética em 15%, o que é provavelmente devido à tensão de alimentação necessária para executar o chip Navi 21 em velocidades de clock mais altas.
⇡#Resultados e preços do teste do jogo
⇡#Benchmarks de jogos com rastreamento de raio
Achados
Bem, podemos dar os parabéns à AMD pelas próximas conquistas, que, ao que parece, já são tidas como certas quando se trata de novos produtos desta empresa. A arquitetura RDNA, cujas bases a AMD lançou na série 5000 de placas de vídeo Radeon, mostrou um potencial notável de crescimento e agora, pela primeira vez em quase cinco anos, surgiram dispositivos com a marca vermelha que podem desafiar os principais aceleradores NVIDIA.
Sim, a Radeon RX 6800 XT é de 3% a 7% FPS mais lenta do que a GeForce RTX 3080 em jogos sem rastreamento de raio, mas a última vez que vimos tal resultado foi na época da Radeon R9 Fury X. Igualmente importante, ela foi totalmente restaurada paridade perdida há muito tempo entre os chips “vermelhos” e “verdes” no desempenho por watt. A lógica RDNA 2 fez pelo silício da AMD o que a arquitetura Maxwell fez pela NVIDIA. Finalmente, a elegante solução Infinity Cache é digna de crédito, que fez uma GPU do calibre do Navi 21 com bus de memória de 256 bits de baixo custo.
O rastreamento de raio continua sendo uma vulnerabilidade no Radeon RX 6800 e no RX 6800 XT. Tudo o que a AMD conseguiu até agora neste campo foi repetir o sucesso da GeForce RTX 2080 Ti dois anos atrás. Por outro lado, a RTX2080 Ti foi considerada a melhor placa de vídeo para jogos há dois meses, então neste caso os esforços da AMD não podem ser subestimados. Um problema mais sério é a falta de soluções de upscaling no lado Radeon, comparável em qualidade de imagem com DLSS 2.0. “Mas o produto AMD é mais barato” – esse slogan não perde sua relevância.
Quanto à versão básica do Radeon RX 6800, aqui a AMD não tem motivos para tentar o comprador com economias. O modelo mais jovem lidera incondicionalmente em testes de jogos em comparação com a GeForce RTX 3070 (por 5-11% FPS dependendo da resolução), carrega o dobro de memória local e, portanto, é esperado mais caro. É verdade que você precisa fazer a mesma alteração para jogos de rastreamento de raios, nos quais o equivalente mais próximo do RX 6800 são as placas de vídeo GeForce RTX 2080 e RTX 2080 SUPER da geração anterior.
Finalmente, temos o prazer de anunciar que a AMD finalmente descobriu como fazer um sistema de refrigeração eficiente e silencioso para suas placas de vídeo de referência. O cooler de dois slots Radeon RX 6800 já é um grande passo à frente em comparação com as turbinas da série 5000. E a Radeon RX 6800 XT acabou por ser uma das placas de vídeo mais silenciosas e frias com que lidamos, apesar do impressionante consumo de energia abaixo de 300 W, que, aparentemente, continuará sendo a referência de potência para todos os futuros aceleradores de alto escalão – acostume-se com isso.