
O desenvolvedor de soluções de IA generativa, MosaicML, recentemente adquirido pela Databricks, relatou bons resultados no treinamento de modelos de linguagem grande (LLMs) usando os aceleradores AMD Instinct MI250 e sua própria plataforma.
A empresa disse que está procurando um novo hardware de aprendizado de máquina em nome de seus clientes, já que a NVIDIA atualmente não pode fornecer seus aceleradores a todos. MosaicML explicou que os requisitos para tais chips são simples:
- Cargas de trabalho do mundo real: oferece suporte ao treinamento LLM com precisão de 16 bits (FP16 ou BF16) com a mesma convergência de modelo final e qualidade treinada em sistemas NVIDIA.
- Velocidade e Custo: Desempenho competitivo e relação custo/desempenho.
- Desenvolvimento: alterações mínimas de código em comparação com sua pilha existente (PyTorch, FSDP, Composer, StreamingDataset, LLM Foundry).

Fonte da imagem: MosaicML
Como a empresa observou, nenhum dos chips até o momento foi capaz de satisfazer totalmente todos os requisitos do MosaicML. No entanto, com o lançamento de versões atualizadas da estrutura PyTorch 2.0 e da plataforma ROCm 5.4+, a situação mudou – o treinamento LLM tornou-se possível nos aceleradores AMD Instinct MI250 sem alterações de código ao usar sua pilha LLM Foundry.
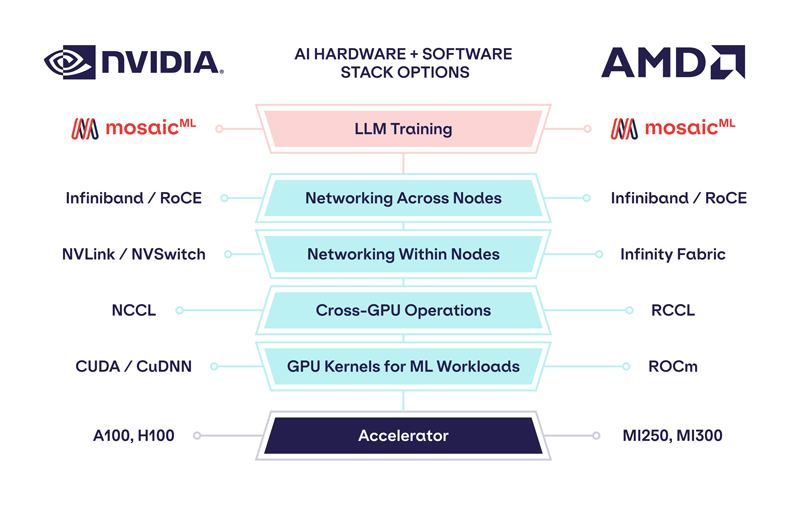
Alguns destaques:
- O treinamento LLM tem sido estável. Com a pilha de treinamento LLM Foundry altamente determinística, o treinamento do LLM MPT-1B nos aceleradores AMD MI250 e NVIDIA A100 produziu curvas de perda quase idênticas ao iniciar do mesmo ponto de teste. Os pesquisadores conseguiram até alternar entre os aceleradores AMD e NVIDIA durante um treinamento.
- O desempenho era competitivo com os sistemas A100 existentes. Os pesquisadores traçaram o perfil da taxa de transferência de treinamento de modelos MPT com parâmetros de 1 a 13 Gb e descobriram que a velocidade de processamento do MI250 por acelerador está dentro de 80% de A100-40GB e dentro de 73% de A100-80GB. A empresa espera que essa lacuna diminua à medida que o software da AMD for aprimorado.
No entanto, nenhuma alteração no código foi necessária.
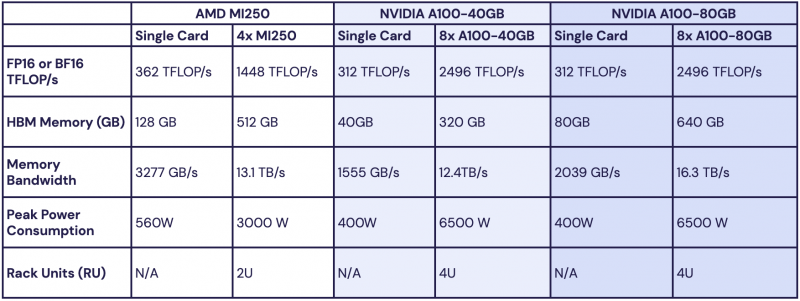
Todos os resultados são de um nó de quatro MI250s, mas a empresa está trabalhando com hiperescaladores para testar os recursos de aprendizado em clusters AMD Instinct maiores. “No geral, nossos testes iniciais mostraram que a AMD criou uma pilha de hardware e software eficiente e fácil de usar que pode competir com a NVIDIA”, disse MosaicML. Este é um passo importante na luta contra o domínio da NVIDIA no mercado de IA.