
O que torna as máquinas baseadas nos princípios de von Neumann verdadeiramente boas é a sua ampla capacidade de emular uma ampla variedade de processos – não excluindo os mesmos sistemas de computação, mas produzidos por sistemas de arquitecturas radicalmente diferentes. E quanto mais densos os computadores de von Neumann se tornam, ou seja, quanto mais seus elementos básicos (ou seja, transistores, uma vez que as tecnologias de semicondutores para sua produção estão mais bem desenvolvidas hoje) cabem por unidade de área, mais lucrativo se torna emular meios de computação de um natureza completamente diferente usando esta tecnologia. Assim, embora os neurônios artificiais – perceptrons, dos quais já falamos mais de uma vez, possam ser implementados fisicamente sem quaisquer dificuldades particulares, inclusive em uma base de material semicondutor, acaba sendo muito mais eficaz (em termos da quantidade total de esforço de engenharia e dinheiro gasto) para formar redes neurais multicamadas em servidores de memória von Neumann ou mesmo em PCs de consumo.
Pelo menos, este tipo de raciocínio permaneceu válido até ao rápido e generalizado aumento de interesse na IA generativa, que ocorreu no outono de 2022, e até hoje este tema continua a ser muito quente.
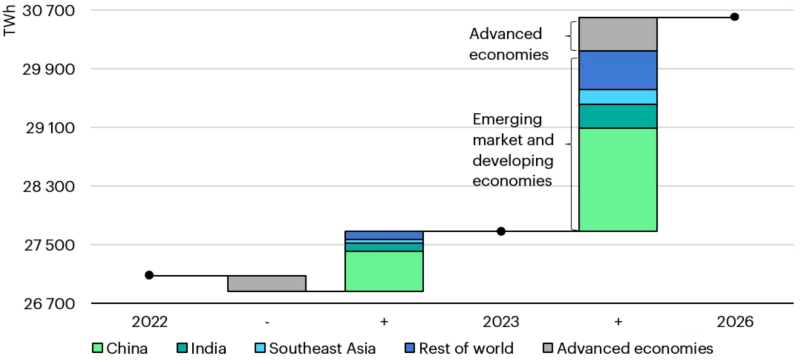
Mudanças no consumo de eletricidade por região do mundo em 2022-2023. e previsão para 2026, TWh (fonte: IEA)
«Quente” não apenas no sentido figurado: segundo a Agência Internacional de Energia (AIE), em 2026, o consumo global de energia pelos data centers dobrará em relação a 2022, atingindo 2% do volume total gerado por todas as usinas do mundo. É claro que nem todos esses incontáveis terawatts serão gastos para alimentar servidores de IA que animam, a pedido dos internautas, imagens fotorrealistas de gatos com chapéus engraçados, mas a contribuição da execução da inteligência artificial existente (e do treinamento de novas) modelos para diversos fins para o rápido crescimento do orçamento energético da civilização é enorme. Por exemplo, a Microsoft já assinou um contrato de fornecimento de energia de 20 anos com uma das usinas nucleares da Constellation Energy na Pensilvânia, e a AWS está contratando um engenheiro-chefe com experiência na indústria nuclear para desenvolver a direção de pequenos reatores modulares e estabelecer conexões com centrais nucleares tradicionais – tudo isto precisamente devido à necessidade urgente de energia mais barata e acessível possível para os centros de dados de IA.
⇡#Menos ruído, mais potência
Segundo o The Economist, treinar apenas o modelo GPT-4 (que hoje já conta com muitos concorrentes diretos) custou mais de 50 GWh – isso representa aproximadamente 0,02% do orçamento anual de energia do estado da Califórnia e 50 vezes mais que o GPT- 3 modelo necessário para seu treinamento. Os especialistas da Forbes temem que o desenvolvimento demasiado rápido da IA esteja a empurrar o planeta para uma crise energética – e a sua preocupação é compreensível: se um rack de servidor clássico de 19 polegadas num centro de dados típico consome cerca de 7 kW de energia, então o mesmo rack, mas com equipamentos orientados para realizar tarefas de IA serão necessários de 30 a 100 kW. É evidente que algo precisa de ser feito em relação a isto, e a opção “vamos aceitar e parar de criar gatos com chapéus engraçados com toda a humanidade de uma vez” – pelo menos a médio prazo – não parece realista. Sim, o entusiasmo em torno da IA, especialmente a negociação puramente de ações, está claramente em declínio, mas uma diminuição na atividade dos especuladores num tema quente pode ser uma indicação de uma penetração mais ampla e profunda desta nova tecnologia numa variedade de indústrias. incluindo os principais para as economias nacionais e globais.
«Metralhadora Da Vinci – duas opções de design em uma folha (fonte: Wikimedia Commons)
Aqui, tanto os desenvolvedores quanto os usuários de modelos de inteligência artificial enfrentam um dilema óbvio. Por um lado, para demonstrar aos cépticos não apenas o efeito económico positivo, mas a superioridade fundamental alcançada pela introdução da IA em vários tipos de actividades económicas, é necessária a aplicação mais ampla possível destas novas tecnologias. Por outro lado, os monstruosos custos de energia para operar (e, separadamente, treinar) modelos de IA colocam em questão a viabilidade económica de tal transição. A situação acaba por ser aproximadamente a mesma que a da disponibilidade potencial de armas automáticas já na Renascença: não há dúvida de que Leonardo da Vinci, que então trabalhava, teria sido capaz de passar do canhão de tiro rápido de 33 canos bateria de rifle que ele desenvolveu (no nível do esboço), tendo criado um cartucho unitário, para uma metralhadora – semelhante em design a, digamos, um esquema bastante simples de Gatling. Poderia, se houvesse pré-requisitos económicos para isso. No entanto, a produção em massa de cartuchos e balas que correspondem exatamente a determinados tamanhos (e a menor discrepância nas dimensões dentro de um único calibre leva inevitavelmente ao bloqueio de armas de carregamento automático e de disparo rápido) na era pré-industrial era completamente impossível ou tão trabalhoso que um cinto de metralhadora cheio de cartuchos feitos à mão por artesãos de oficina provavelmente custaria mais do que equipar algum esquadrão de besteiros. Desperdício vazio!
O apetite excessivo por energia dos sistemas modernos de IA também pode ser considerado uma indicação da discrepância entre a ideia de computação neuromórfica, ou seja, computação “semelhante ao cérebro” e a base de hardware utilizada para a sua implementação prática. As ferramentas de computação semicondutoras em geral são caracterizadas por uma eficiência energética extremamente baixa: basta comparar os orçamentos de energia de qualquer data center, gastos na operação dos próprios servidores, por um lado, e nos sistemas de remoção de calor deles, por outro. Ao mesmo tempo, uma pessoa – digamos, um artista profissional que desenha manualmente os mesmos gatos notórios com chapéus engraçados – gasta em sua atividade mental (nem levamos em conta os movimentos musculares, eles são ainda mais econômicos) pouco mais do que dez watts, ou seja, mais de três ordens de magnitude a menos que um rack cheio de aceleradores gráficos de servidor em um data center.
E a questão aqui não está na velocidade de processamento de tarefas simples: multiplicar, digamos, números de três dígitos na cabeça, mesmo para um professor de matemática, não é fácil, enquanto para a calculadora mais simples, até três dígitos, até trinta -três, é tudo igual – o principal é que haja posições suficientes na tela para exibir o resultado. A vantagem do cérebro biológico é o maior paralelismo de seu trabalho, graças ao qual é capaz de resolver problemas obviamente superiores em complexidade à multiplicação de inteiros – e que, de forma amigável, devem ser imitados pelo hardware envolvido na neuromórfica cálculos. Então, o que nos impede de passar da emulação ineficiente (do ponto de vista energético) de redes neurais em PCs von Neumann para a implementação das mesmas redes em hardware, como dizem, na forma?

O microprocessador óptico Taichi usa circuitos fotônicos para receber sinais de informação/controle e processá-los (fonte: Universidade Tsinghua)
Em princípio, não existem obstáculos físicos para aumentar a eficiência energética da base de hardware da computação neuromórfica. Já abordamos a ideia de usar a fotônica (em vez ou em conjunto com a microeletrônica) para economizar energia na solução de problemas relacionados ao aprendizado de máquina (ML) – e essa direção está sendo implementada de forma bastante consistente em todo o mundo. Em particular, pesquisadores da Universidade Tsinghua de Pequim, juntamente com o Centro Nacional Chinês de Pesquisa para Ciência e Tecnologia da Informação, apresentaram na primavera de 2024 o Taichi, um microchip criado com base nos princípios da fotônica para organizar redes neurais ópticas. Ao combinar abordagens de interferência e difração para processamento de sinal óptico, um Taichi multi-chip é capaz de operar uma rede neural com quase 14 milhões de parâmetros operacionais. Como resultado, sua precisão demonstrada no reconhecimento de mais de 1,5 mil caracteres manuscritos de cinquenta alfabetos diferentes (retirados do banco de dados Omniglot, bem conhecido nos círculos de ML) chega a quase 92%. Além das tarefas discriminativas de IA, o Taichi também pode resolver tarefas generativas, como criar música no estilo de Bach ou paisagens no espírito de Van Gogh. Comparado ao Nvidia H100, este computador baseado nos princípios da fotônica, segundo seus desenvolvedores, é mais de mil vezes mais eficiente em termos energéticos – e este, ao que parece, é o caminho certo que o hardware de computação neuromórfica deve seguir no previsível futuro.
Infelizmente, em termos práticos, tudo está longe de correr bem com Taichi – e por uma série de razões, tais tecnologias até agora só podem reivindicar os louros da substituição de microprocessadores semicondutores, inclusive para cálculos complexos de IA. O próprio chip resolve problemas clássicos de MO da categoria “multiplicação de vetores de matrizes” de forma eficiente e rápida, enquanto ocupa uma área muito modesta – bastante comparável às dimensões do acelerador de silício subjacente ao mesmo H100. No entanto, para fornecer os dados necessários à entrada do Taichi na forma de pulsos de luz com certas características adequadas para processamento nela, e então ler os resultados dos cálculos na saída e convertê-los em sinais elétricos para operações posteriores sobre eles , é necessária uma quantidade razoável de máquinas bastante volumosas e que consomem muita energia – como lasers e filtros de alta frequência.

Uma das limitações mais importantes da fotônica de silício é a incapacidade de litografiar um gerador de radiação óptica coerente (laser) em um substrato de silício; por esse motivo, micro e nanolasers devem ser criados separadamente e depois integrados em uma placa vazia com circuitos ópticos (usando o método flip-chip, por exemplo; na foto mostrada, os módulos de laser são grandes blocos com nervuras cinza escuro) , o que não simplifica a fabricação desses chips e não os torna mais baratos (fonte: IEEE Spectrum)
Como resultado, toda a instalação, construída em torno de um único chip, caberá apenas em uma mesa. É claro que os pesquisadores estão trabalhando para reduzir o tamanho e o consumo de energia de seus sistemas – mas até agora, a fotônica como base de hardware para a computação neuromórfica claramente não está em primeiro lugar entre os potenciais substitutos para os computadores semicondutores de Von Neumann. Agora, se for possível passar de circuitos eletro-ópticos híbridos para circuitos puramente fotônicos, então a conversa será diferente; mas por enquanto esta é uma questão de um futuro bastante distante.
⇡#O que está sob o neuro-capô
Antes de passarmos à descrição de implementações mais práticas de computadores neuromórficos, vamos mergulhar brevemente nos recursos de design de redes neurais biológicas naturais. Qualquer célula, incluindo células nervosas, é delimitada do ambiente por uma membrana. Devido à presença de tal limite e passagens reguladas (canais) nele, as propriedades físico-químicas dos espaços internos e externos da célula podem diferir visivelmente. Em particular, a concentração e a composição de íons nas superfícies interna e externa da membrana de uma célula que está em estado quieto são diferentes (neste caso, a carga total de todos os íons dentro de uma célula normal em estado quieto é, claro, zero – apenas diferentes tipos deles são retidos na membrana e em quantidades diferentes, tanto dentro quanto fora). Do ponto de vista da física, isso leva automaticamente ao aparecimento de uma diferença de potencial estável na fronteira entre o volume interno da célula e o ambiente circundante – cerca de 70-90 mV em valor absoluto e com sinal negativo.
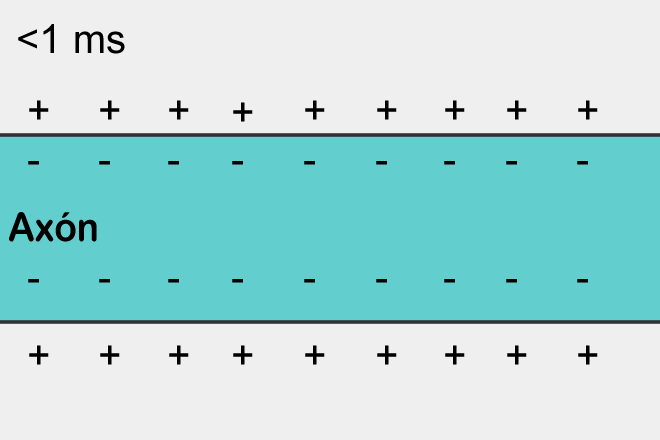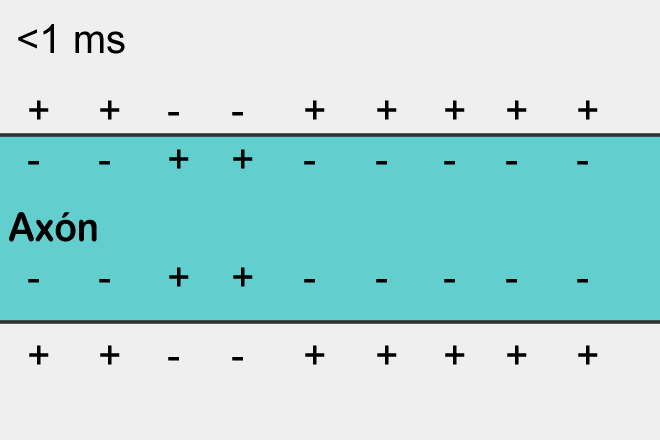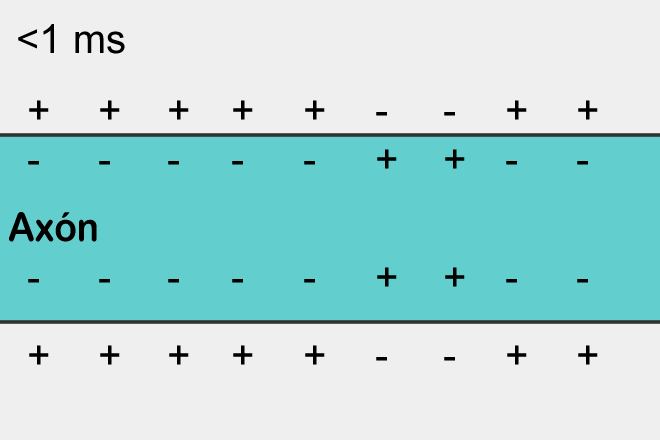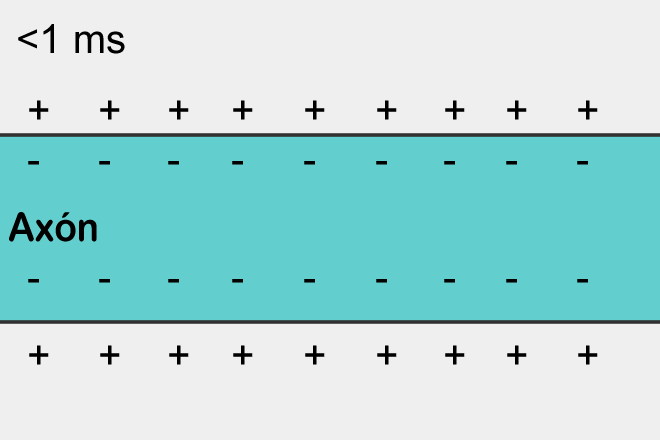
O impulso nervoso mais simples (uma área com carga negativa na parte externa da membrana e carga positiva na parte interna), propagando-se ao longo da superfície de um axônio (cuja carga na parte externa é inicialmente positiva) devido a uma mudança em o potencial transmembrana (fonte: Wikimedia Commons)
Assim, sob a influência de vários estímulos – na maioria das vezes, para uma célula nervosa, são sinais químicos que entram pela sinapse – o potencial de membrana pode mudar. A mudança – geralmente manifestada como uma substituição local de curto prazo de uma carga externa positiva por uma negativa – é iniciada em um determinado ponto da membrana e se espalha por sua superfície. Os termos “positivo” e “negativo” são relativos aqui: os potenciais dos lados externo e interno da membrana em cada área específica são comparados. O processo de tal propagação de excitação ao longo da superfície da membrana, caso contrário, uma onda de excitação, é chamado de potencial de ação (ou simplesmente um pico, um papel vegetal do termo inglês spike). E este é um dos conceitos-chave da neurofisiologia, pois é assim que os sinais de informação – impulsos nervosos – são transmitidos através do tecido biológico.
Do ponto de vista dos sistemas neuromórficos, é importante que um potencial de ação seja gerado em uma célula nervosa ao atingir um certo nível de despolarização (isto é, atingir um certo valor limiar positivo) da membrana neuronal. A lei do “tudo ou nada”, conhecida na neurofisiologia desde o século 19, afirma que a membrana celular de um tecido excitável ou não responde a um estímulo ou responde com a força máxima possível no momento – é claro , este é o caso modelo ideal; Com células reais, tudo costuma ser muito mais complicado. De uma forma ou de outra, a lei do “tudo ou nada” acabou sendo a abstração matemática mais conveniente, que formou a base de toda uma classe de redes neurais artificiais, agora por razões óbvias chamadas de redes neurais de pico (SNN). Os perceptrons de pico diferem dos perceptrons das redes neurais artificiais “comuns” que consideramos anteriormente (chamadas na literatura inglesa simplesmente de redes neurais artificiais ANN) tanto no tipo de sinais de entrada quanto na forma como a função de sua operação é implementada no “ corpo” do neurônio artificial.
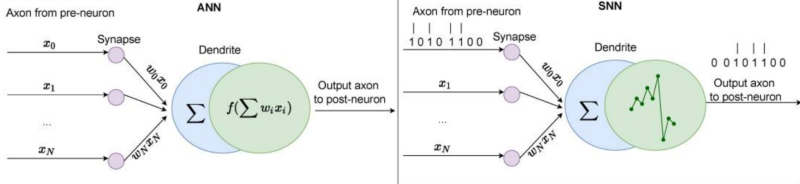
Representações esquemáticas dos princípios de operação de perceptrons de uma rede neural artificial (ANN) “regular” e de uma rede neural pulsada (SNN) (fonte: PubMed)
Lembremos que o princípio geral de funcionamento de um perceptron é produzir um determinado sinal através de uma única saída, dependendo de quais sinais chegam às suas numerosas entradas. Essa dependência é determinada pela função de ativação, que para perceptrons de RNA pode ser desempenhada pelo “passo” de Heaviside, sigmóide, tangente hiperbólica, ReLU e outros. Os argumentos de entrada dessas funções – sinais modificados por pesos – são considerados como quantidades contínuas e, em geral, uma rede neural artificial profunda totalmente conectada (ou seja, com o número de camadas internas – ocultas – excedendo duas) lida precisamente com contínuas (em um caso particular, fluxos de dados de entrada fixos. E é extremamente útil para uma variedade de aplicações de RNA, incluindo reconhecimento de padrões. A imagem – mesmo que seja um dos quadros da transmissão do vídeo – está parada; cada um de seus pixels que cai na entrada de uma rede neural convolucional, por exemplo, gera um sinal com certos parâmetros constantes (brilho, composição de cores) – e é extremamente simples processá-lo com uma rede neural que opera com quantidades contínuas na entrada.
Mas o tecido nervoso biológico funciona de maneira fundamentalmente diferente! Os potenciais de ação se propagam nele como impulsos únicos separados por determinados intervalos de tempo. Isso afeta a natureza do trabalho da rede neural como um todo: digamos, impulsos que ocorrem com muita frequência, um após o outro, não serão detectados por ela (e uma reação a eles nos neurônios, conseqüentemente, não será formada) – uma vez que o receptor, que é uma seção da membrana dendrítica sob a fenda sináptica correspondente, não terá tempo de retornar seu potencial elétrico ao seu valor original para acionar a próxima operação em resposta a um novo sinal que chega muito rapidamente.
A ideia de reproduzir esse comportamento do tecido nervoso por meios artificiais leva logicamente ao conceito de uma rede neural com picos, a primeira abordagem matematicamente baseada para a qual – o modelo de neurônios com picos de Hodgkin-Huxley (HH) – foi proposta por Alan Hodgkin e Andrew Huxley em 1952. Os perceptrons em tal rede processam não quantidades contínuas de entrada, mas sequências de pulsos únicos, usando sistemas de equações diferenciais ordinárias de vários graus de complexidade. O próprio modelo HH (construído por Hodgkin e Huxley com base em observações de como as concentrações de íons potássio e sódio mudam ao longo da membrana do axônio da lula gigante à medida que o potencial de ação se propaga) ainda permanece um dos mais precisos em termos de conformidade com o protótipo biológico. No entanto, hoje quase não é utilizado devido à sua complexidade computacional extremamente alta – muitas outras implementações práticas de SNN foram desenvolvidas até o momento.
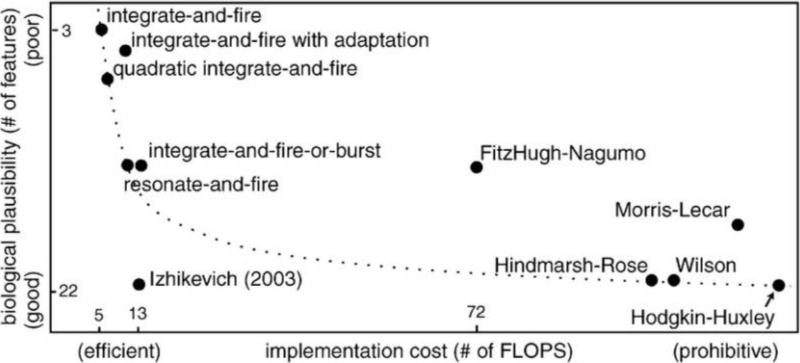
Vários modelos SNN em termos de preço de venda – plausibilidade biológica (fonte: PubMed)
⇡#Semicondutores não desistem
Faz sentido falar sobre a “praticidade” de tais implementações justamente no caso em que esses modelos são emulados digitalmente em computadores von Neumann, e é possível medir com precisão os recursos computacionais gastos na execução de um ou outro. Parece que, com base em hardware adequado, as redes neurais artificiais pulsadas deveriam funcionar com eficiência muito maior – se não exatamente igual a um cérebro biológico, pelo menos visivelmente superiores neste parâmetro à emulação em servidores x86 ou ARM convencionais com processadores semicondutores.
Observemos, aliás, que não é tão necessário abandonar a microeletrônica de semicondutores para criar um computador verdadeiramente neuromórfico. É perfeitamente possível criar estruturas “semelhantes ao cérebro” por fotolitografia à base de silício. Outra coisa é que uma limitação significativa aqui é a falta fundamental de conectividade espacial entre perceptrons individuais; Os neurônios biológicos no cérebro podem ter milhares de conexões sinápticas com seus vizinhos (às vezes separados fisicamente por distâncias bastante significativas), enquanto as estruturas semicondutoras planares formadas na superfície do silício devem contar com barramentos de interconexão metálicos – que são litografados sequencialmente em camadas cada vez mais altas. – para trocar informações de um circuito integrado. Quanto mais camadas houver, maior será a probabilidade de ocorrência de erros/imprecisões durante a fabricação do chip, além de mais difícil será projetar comprimentos ideais (afinal, o tempo de atraso durante a passagem do sinal também é importante!) contatos entre perceptrons individuais. Como resultado, neurônios artificiais semicondutores feitos usando meios clássicos podem ostentar apenas dezenas, na melhor das hipóteses centenas, de conexões sinápticas com seus vizinhos, o que francamente não é suficiente para um neuromorfismo verdadeiramente universal. E se levarmos em conta também a monstruosa dissipação de calor dos dispositivos semicondutores durante os cálculos…

Um grupo de pesquisadores indianos posa com protótipos de engenharia de seus computadores neuromórficos BTBT (fonte: Instituto Indiano de Tecnologia, Bombaim)
Engenheiros e cientistas microeletrônicos, é claro, não admitem a derrota final nesta área – e propõem regularmente novas maneiras de desenvolver neuromórficos semicondutores. Assim, em 2022, um grupo do Instituto Indiano de Tecnologia de Bombaim (Mumbai) propôs um método engenhoso e muito econômico (em termos de consumo de energia) para construir uma rede perceptron neuromórfica – ou seja, pulsada – em semicondutores usando o efeito de inter tunelamento de banda (túnel inter-banda ou banda a banda, BTBT). É interessante que para dispositivos semicondutores clássicos este efeito quântico seja considerado extremamente indesejável, pois é um dos motivos para o aparecimento de vazamentos parasitas entre o dreno e a fonte (mais precisamente, da banda de valência da fonte para a banda de condução do dreno) em um transistor desligado.
A ideia dos pesquisadores indianos é compor (em um plano por enquanto, como prova de conceito) a partir de capacitores obviamente suscetíveis ao efeito BTBT, uma matriz retangular, a cada nó da qual é fornecido um barramento de entrada para transferência carregar para o capacitor. Depois de acumular até um determinado valor, ocorre o tunelamento interbanda – e toda essa carga, que é importante, flui ainda mais ao longo do barramento de saída de acordo com o circuito da rede neural artificial; para a próxima camada perceptron, por exemplo. Como resultado, um fluxo de dados pulsado é formado – mesmo que na entrada da primeira camada de capacitores eles (na forma de corrente elétrica entrando no circuito) fossem contínuos – e o capacitor que enviou esse impulso em sua jornada posterior é “ reset”, entrando em estado de prontidão para novo enchimento.
O esquema proposto é atraente sob vários pontos de vista, e principalmente do ponto de vista energético. Como estamos falando de um efeito quântico, sua manifestação requer correntes relativamente fracas fluindo através de dispositivos semicondutores em miniatura. Assim, ao mesmo tempo, fica resolvida a questão da compactação de um computador neuromórfico: inicialmente terá apenas que ser realizada por método fotolitográfico, embora utilizando processos tecnológicos bastante maduros, uma vez que os capacitores semicondutores têm restrições muito mais rígidas quanto às dimensões permitidas do que transistores. Assim, o protótipo de engenharia do chip SNN descrito foi fabricado em uma fábrica contratada de acordo com os padrões de produção “45 nm”.
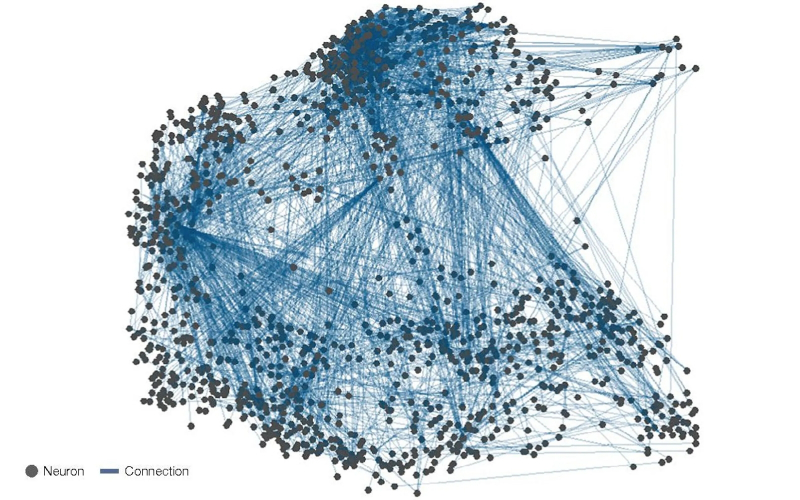
Só para entender a escala das tarefas que os criadores dos computadores neuromórficos enfrentam: o diagrama mostra um conectoma (mapa de interconexões) de neurônios na parte mais densa do sistema nervoso da Drosophila. Apenas moscas da fruta! (fonte: Física da Natureza)
As tentativas de implementar uma rede neural pulsada em dispositivos semicondutores clássicos (nos quais o efeito BTBT é considerado nada menos que parasita) foram feitas há muito tempo, mas os dispositivos resultantes não entram em séries amplas – em grande parte devido à sua intensidade energética significativa. O desenvolvimento indiano, segundo os pesquisadores, aumenta a eficiência da computação neuromórfica da maneira mais fundamental: a energia de pico de um potencial de ação artificial que se propaga ao longo de tal capacitor SNN acaba sendo cinco mil vezes menor do que para sistemas semicondutores semelhantes, onde os transistores desempenham o papel principal (e são feitos usando padrões tecnológicos semelhantes), e o consumo de energia de um único nó em repouso é uma ordem de grandeza menor. Para demonstrar a aplicabilidade prática de sua ideia, um grupo do Instituto Indiano de Tecnologia organizou uma pequena rede neural BTBT (20 neurônios artificiais que codificam o sinal e outros 36 para processá-lo), inspirada na estrutura do córtex auditivo do cérebro, e, segundo eles, alcançou um reconhecimento confiável das palavras proferidas pelos experimentadores, mesmo em uma base de hardware tão escassa.
A computação neuromórfica – e a computação – tem hoje seu quinhão de desafios, é claro; e talvez o mais importante deles seja o âmbito limitado de aplicabilidade. Assim, o já mencionado problema de reconhecimento de imagem é resolvido muito melhor (ou seja, com mais precisão e rapidez) por RNAs profundos mais familiares que operam com quantidades contínuas nas entradas dos perceptrons, e mesmo um ganho dramático na eficiência energética não se torna decisivo argumento a favor dos SNNs. Outra coisa é a imitação direta de estruturas nervosas biológicas: aqui as redes neurais de impulso realmente não têm igual (o exemplo indiano com um modelo de uma área do córtex auditivo confirma isso diretamente). E nessa direção – no caminho de transformar em realidade as mais loucas fantasias científicas sobre inteligência artificial, sobre a notória inteligência artificial forte – eles definitivamente têm um grande futuro.
⇡#Materiais relacionados
- Os cientistas criaram um novo elemento de memória quântica – um memcapacitor de micro-ondas supercondutor
- SpiNNcloud apresentou o primeiro “supercomputador neuromórfico” SpiNNaker2 comercial baseado em Arm
- A Intel lançou o computador neuromórfico Hala Point em chips 1152 Loihi 2 com arquitetura semelhante ao cérebro
- Um chip de IA supereficiente foi criado na Coreia do Sul, combinando abordagens clássicas e neuromórficas
- O supercomputador neuromórfico de IA DeepSouth aparecerá na Austrália para imitar o cérebro humano