
A startup americana Cerebras Systems, que desenvolve chips para sistemas de aprendizado de máquina e outras tarefas que consomem muitos recursos, anunciou o lançamento do que é considerada a plataforma de IA mais produtiva do mundo para inferência – Cerebras Inference. Espera-se que concorra seriamente com soluções baseadas em aceleradores NVIDIA.
O sistema de nuvem Cerebras Inference é baseado em aceleradores WSE-3. Esses produtos gigantescos, fabricados com a tecnologia de processo de 5 nm da TSMC, contêm 4 trilhões de transistores, 900 mil núcleos e 44 GB de SRAM. A largura de banda total da memória interna chega a 21 PB/s, e a interconexão interna – 214 PB/s. Para efeito de comparação, um único chip HBM3e no NVIDIA H200 possui uma taxa de transferência de “apenas” 4,8 TB/s.

Fonte da imagem: Cerebras
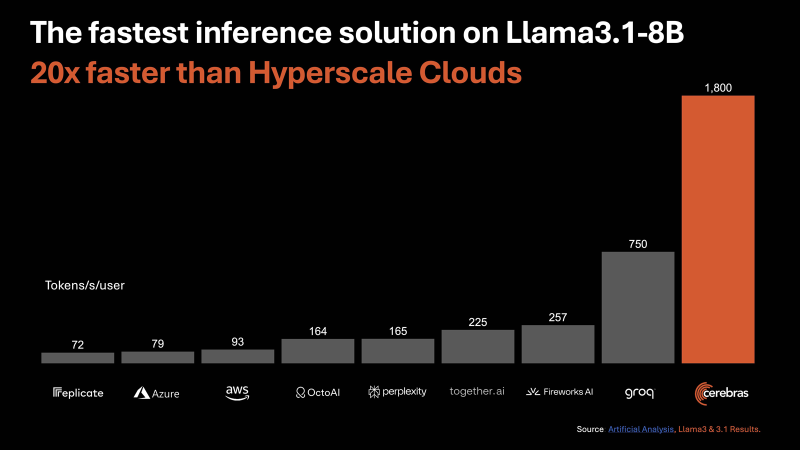
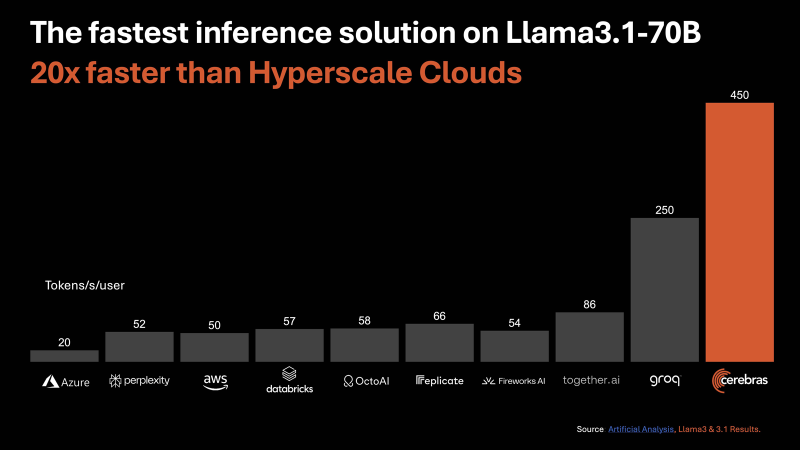
De acordo com a Cerebras, a nova plataforma de inferência oferece desempenho até 20 vezes maior em comparação com soluções comparáveis em chips NVIDIA em serviços hiperescaladores. Em particular, o desempenho é de até 1.800 tokens por segundo por usuário para o modelo Llama3.1 8B AI e de até 450 tokens por segundo para o Llama3.1 70B. Para efeito de comparação, para AWS esses valores são 93 e 50, respectivamente. Estamos falando de operações FP16. Cerebras afirma que o melhor resultado para clusters baseados em NVIDIA H100 no caso do Llama3.1 70B é de 128 tokens por segundo.
«Ao contrário de abordagens alternativas que sacrificam a precisão pela velocidade, o Cerebras oferece o mais alto desempenho, mantendo a precisão de 16 bits para todo o processo de inferência”, afirma a empresa.
Ao mesmo tempo, os serviços de inferência da Cerebras custam várias vezes menos em comparação com as ofertas concorrentes: US$ 0,1 por 1 milhão de tokens para o Llama 3.1 8B e US$ 0,6 por 1 milhão de tokens para o Llama 3.1 70B. Pague conforme usar. A Cerebras planeja fornecer serviços de inferência por meio de uma API compatível com OpenAI. O benefício dessa abordagem é que os desenvolvedores que já construíram aplicativos baseados em GPT-4, Claude, Mistral ou outros modelos de IA em nuvem não terão que alterar completamente seu código para migrar cargas de trabalho para a plataforma Cerebras Inference.
Para empresas maiores, o plano de serviço Enterprise Tier oferece modelos altamente customizados, experiências customizadas e suporte dedicado. O pacote Developer Tier padrão requer um preço de assinatura a partir de US$ 0,1 por 1 milhão de tokens. Além disso, há um acesso gratuito de nível básico com restrições. Cerebras afirma que o lançamento da plataforma abrirá oportunidades inteiramente novas para a implementação de IA generativa em vários campos.