
A Intel divulgou os resultados dos testes do acelerador Habana Gaudi2 no benchmark GPT-J (parte do MLPerf Inference v3.1), baseado em um modelo de linguagem grande (LLM) com 6 bilhões de parâmetros. Os dados obtidos sugerem que este produto pode se tornar uma alternativa à solução NVIDIA H100 no mercado de IA.
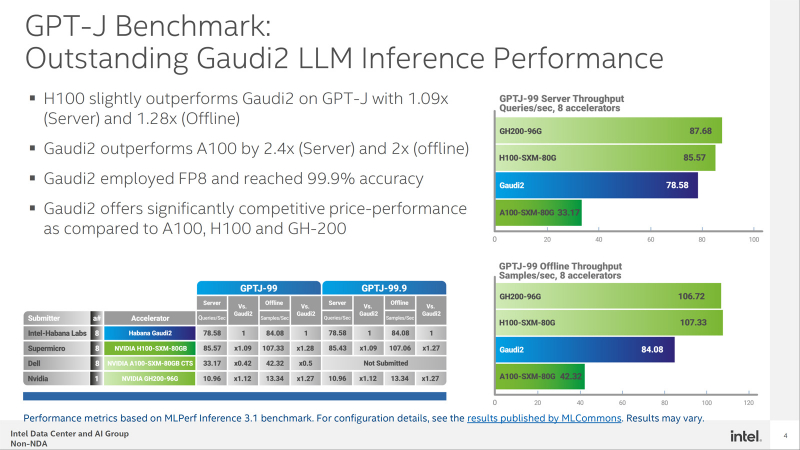
Em particular, no teste GPT-J, o acelerador H100 mostra uma vantagem de desempenho relativamente pequena sobre Gaudi2 – ×1,09 no modo servidor e ×1,28 no modo offline. Ao mesmo tempo, Gaudi2 supera o acelerador NVIDIA A100 em 2,4 vezes no modo servidor e 2 vezes no modo offline.
Além disso, a solução da Intel está à frente do H100 nos modelos BridgeTower. Este teste foi treinado em 4 milhões de imagens. Diz-se que a precisão da resposta visual a perguntas (VQAv2) chega a 78,73%. Quando ampliado, o modelo tem uma precisão ainda maior de 81,15%, superando os modelos treinados em conjuntos de dados muito maiores.
Fonte da imagem: Intel
O teste GPT-J fala da competitividade de Habana Gaudi2. Ao processar consultas on-line, esse acelerador atinge uma taxa de transferência de 78,58 amostras por segundo e, no modo off-line, atinge 84,08 amostras por segundo. Para efeito de comparação: para o NVIDIA H100 esses números são 85,57 e 107,33 amostras por segundo, respectivamente.

No futuro, a Intel planeja melhorar o desempenho e a cobertura do modelo nos testes MLPerf por meio de atualizações regulares de software. Mas a Intel ainda está se atualizando – a NVIDIA preparou uma ferramenta TensorRT-LLM aberta e gratuita, que não apenas dobra a velocidade de execução do LLM no H100, mas também oferece alguns ganhos de desempenho em aceleradores mais antigos.