
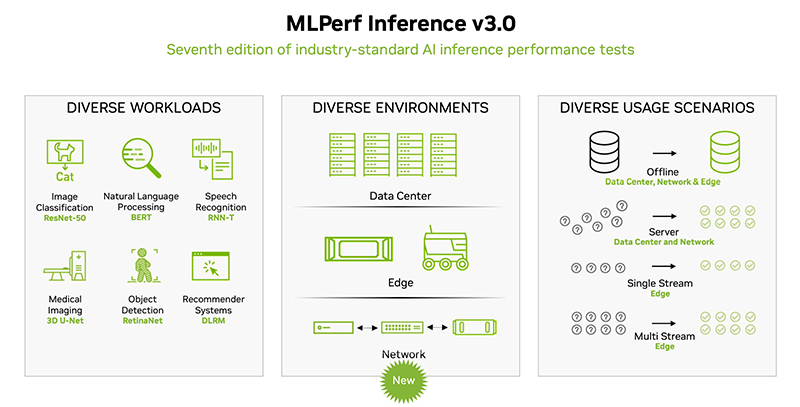
O consórcio aberto de engenharia MLCommons publicou os últimos resultados do benchmark AI MLPerf Inference (v3.0). Desta vez, 25 empresas se inscreveram para testes, enquanto 21 empresas participaram dos testes no outono passado e 19 na primavera passada. HPCWire destacou os resultados e atualizações mais notáveis da última rodada.
As empresas forneceram mais de 6.700 resultados de desempenho e mais de 2.400 medições de desempenho e eficiência energética. Os participantes incluíram Alibaba, ASUS, Azure, cTuning, Deci.ai, Dell, Gigabyte, H3C, HPE, Inspur, Intel, Krai, Lenovo, Moffett, Nettrix, NEUCHIPS, Neural Magic, NVIDIA, Qualcomm, Quanta Cloud Technology, rebeliões, SiMa , Supermicro, VMware e xFusion, com quase metade deles também medindo o consumo de energia durante os testes.
Fonte da imagem: hpcwire.com
Observou-se que cTuning, Quanta Cloud Technology, Relations, SiMa e xFusion forneceram seus primeiros resultados, cTuning, NEUCHIPS e SiMa realizaram as primeiras medições de eficiência energética, e os fornecedores HPE, NVIDIA e Qualcomm que participaram repetidamente apresentaram resultados de teste expandidos e atualizados .
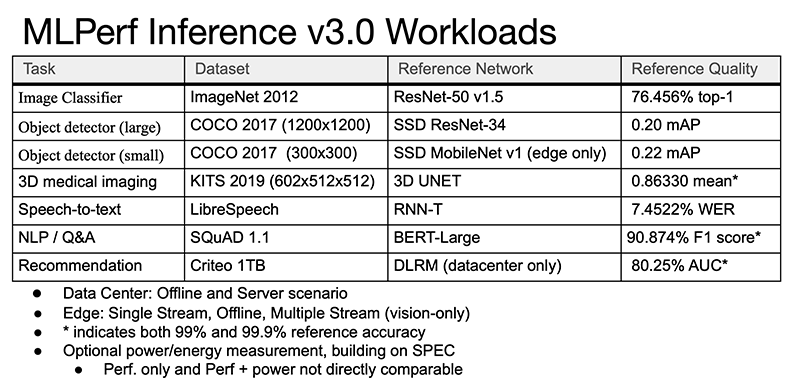
O conjunto de testes no MLPerf Inference 3.0 não foi alterado, mas um novo script foi adicionado – network. Além disso, métricas de inferência aprimoradas para Bert-Large foram fornecidas, o que é de particular interesse, pois é, por natureza, mais próximo de modelos de linguagem grande (LLMs), como ChatGPT. Embora a inferência geralmente não seja tão computacionalmente intensiva quanto o treinamento, ainda é um elemento crítico na implementação da IA.
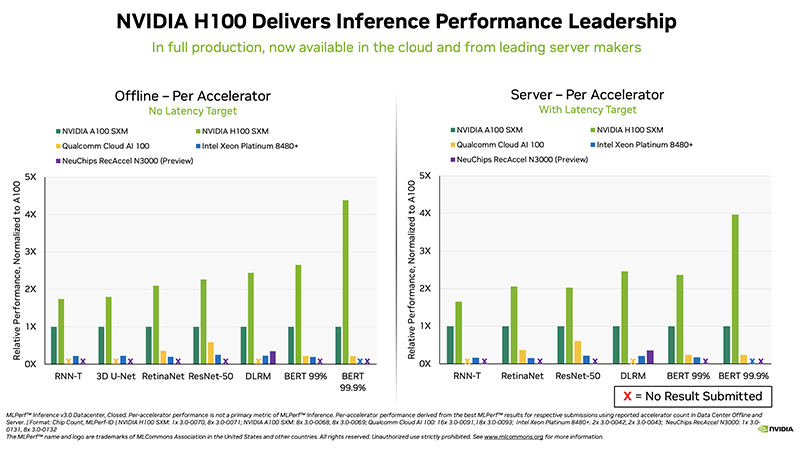
No geral, a NVIDIA continua a dominar em termos de desempenho, liderando em todas as categorias. Ao mesmo tempo, as startups Neuchips e SiMa ultrapassaram a NVIDIA em termos de desempenho por watt em comparação com a NVIDIA H100 e a Jetson AGX Orin, respectivamente. O acelerador Qualcomm Cloud AI100 também teve um bom desempenho em eficiência de energia em comparação com o NVIDIA H100 em alguns cenários.
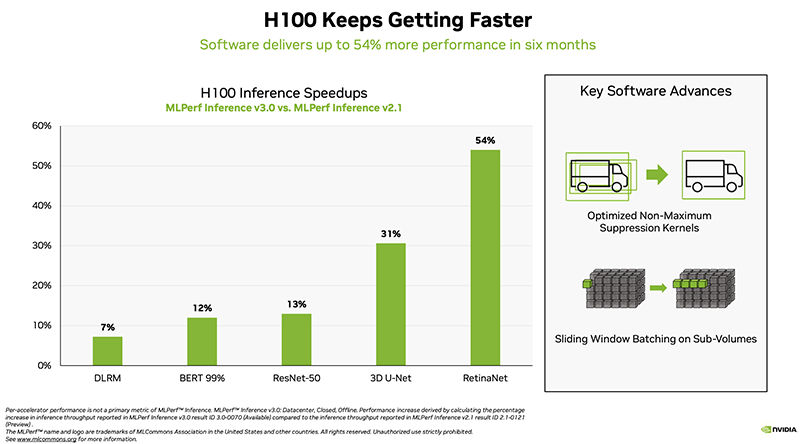
A NVIDIA demonstrou o desempenho do novo acelerador H100, bem como o recém-lançado L4. Segundo o diretor de IA, benchmarking e tecnologias de nuvem da NVIDIA, a empresa conseguiu um aumento de desempenho de até 54% em relação aos primeiros aplicativos há seis meses. Separadamente, é enfatizado um aumento de mais de três vezes no desempenho do L4 em comparação com o T4, bem como a eficiência do software com o Transformer Engine.
Finalmente, outro relatório interessante foi preparado em conjunto pela VMware, NVIDIA e Dell. Um sistema virtualizado com o H100 “atingiu 94% de 205% de desempenho bare metal” usando 16 vCPUs de 128 disponíveis. As 112 vCPUs restantes, conforme observado, podem ser usadas para outras cargas de trabalho e não afetam o desempenho da inferência.
Na última rodada do MLPerf Inference, a Intel também publicou alguns resultados interessantes na categoria preliminar de produtos que devem ser lançados dentro de seis meses. Nesta rodada, a Intel apresentou sistemas de nó único (1-nó-2S-SPR-PyTorch-INT8) com dois processadores Sapphire Rapids (Intel Xeon Platinum 8480+) em um aplicativo fechado para data centers.

A Qualcomm observou que seu acelerador Cloud AI 100 tem um bom desempenho consistente em MLPerf, mostrando baixa latência e alta eficiência de energia. A empresa informou que seus resultados no MLPerf Inference 3.0 superaram todos os recordes anteriores de pico de desempenho off-line, eficiência de energia e menor latência em todas as categorias. Desde o MLPerf 1.0, o desempenho do Cloud AI 100 aumentou em 86% e a eficiência energética em 52%. Tudo isso é alcançado graças à otimização de software, de modo que a recusa da Meta* desses chips na época parece justificada.
* Está incluída na lista de associações públicas e organizações religiosas em relação às quais o tribunal tomou uma decisão final para liquidar ou proibir atividades com base na Lei Federal nº 114-FZ de 25 de julho de 2002 “No combate a extremistas atividade”.