
A empresa financeira Bloomberg decidiu provar que existem maneiras mais inteligentes de ajustar aplicativos de IA que não apresentam os problemas éticos ou de segurança que acompanham o uso do ChatGPT, por exemplo.
A Bloomberg lançou seu próprio grande modelo de linguagem BloombergGPT com 50 bilhões de parâmetros, projetado para aplicações financeiras. É menor que o ChatGPT, que é baseado em uma versão aprimorada do GPT-3 com 175 bilhões de parâmetros. Mas, de acordo com pesquisadores da Bloomberg e da Johns Hopkins, modelos pequenos são o que você precisa para aplicativos específicos de domínio. A Bloomberg disse que não abriria o BloombergGPT devido ao risco de vazamento de dados confidenciais, como do banco de dados FINPILE usado para treinamento.

Fonte da imagem: Pixabay
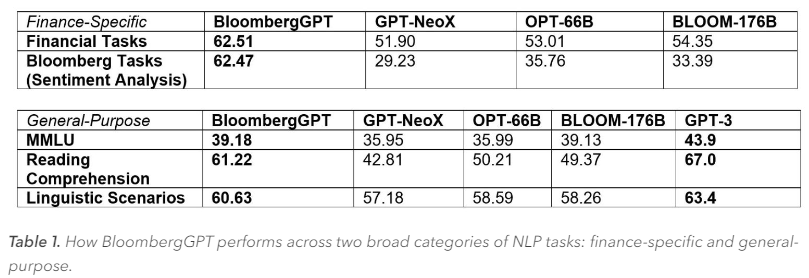
Segundo os pesquisadores, o BloombergGPT é funcionalmente semelhante ao ChatGPT, mas oferece maior precisão do que modelos comparáveis com mais parâmetros. Eles também argumentam que os modelos gerais não podem substituir os específicos do domínio. Modelos menores são mais precisos e podem treinar muito mais rápido do que modelos genéricos como o GPT-3. Além disso, eles exigem menos recursos de computação.
A Bloomberg gastou aproximadamente 1,3 milhão de horas de GPU treinando a BloombergGPT em aceleradores NVIDIA A100 na nuvem AWS. O treinamento foi realizado em 64 clusters de aceleradores, cada um com oito A100 (40 GB) conectados por NVswitch. Para comunicação, foram utilizadas conexões 400G via AWS Elastic Fabric e NVIDIA GPUDirect Storage, e para armazenamento de dados, foi utilizado o sistema de arquivos paralelo distribuído Lustre com suporte para velocidades de leitura e gravação de até 1000 MB/s.
Fonte: Bloomberg
A capacidade total de memória de todos os aceleradores não era suficiente, então a Bloomberg fez otimizações para o treinamento do modelo: divisão em estágios separados, usando cálculos de precisão mista (BF16/FP32), etc. “Depois de experimentar várias tecnologias, alcançamos um [desempenho] médio de 102 teraflops e cada etapa de treinamento levou 32,5 segundos”, disseram os pesquisadores.
A Bloomberg usou pouco mais da metade (54%) de seu conjunto de dados – 363 bilhões de documentos (desde 2007) do banco de dados interno da Bloomberg. Os 345 bilhões de documentos restantes vieram de comunicados de imprensa disponíveis ao público, notícias da Bloomberg, documentos públicos e até mesmo da Wikipedia. Os documentos são chamados de “token”. Os pesquisadores pretendiam que as sequências de treinamento tivessem 2.048 tokens de comprimento para manter o uso do acelerador o mais alto possível.