A Xiaomi anunciou o lançamento do modelo de IA MiMo-V2-Flash, gratuito e de código aberto. Ele se destaca pela alta potência, eficiência e velocidade, sendo excelente em cenários que envolvem raciocínio, programação e atuação como um agente de IA. O desenvolvedor afirma que é um assistente completo e excelente para tarefas do dia a dia.
Fonte da imagem: mimo.xiaomi.com
O modelo de IA MiMo-V2-Flash está disponível para usuários em todo o mundo na plataforma Hugging Face, na infraestrutura do Google Cloud AI Studio e na plataforma de desenvolvedores da Xiaomi. O MiMo-V2-Flash apresenta uma arquitetura de “mistura especializada” — seu tamanho total é de 309 bilhões de parâmetros, dos quais apenas 15 bilhões são ativos. Outro mecanismo de otimização é um híbrido de Atenção Global, que considera todos os tokens de contexto, e Atenção por Janela Deslizante, que considera apenas os tokens atuais e adjacentes. Ele é implementado em uma proporção de 1:5 — consideravelmente, o modelo passa a maior parte do tempo de resposta olhando para baixo, mas ocasionalmente escaneia toda a rua. Isso permite uma velocidade comparável à abordagem de janela deslizante, com precisão quase comparável à Atenção Global pura.
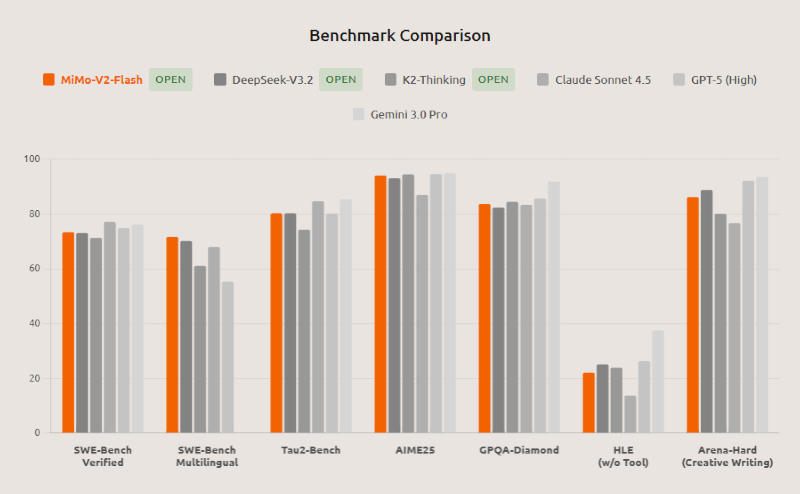
De acordo com a Xiaomi, o MiMo-V2-Flash ficou em primeiro lugar entre todos os modelos de código aberto nos testes padrão SWE-bench Verified e Multilingual, que avaliam as capacidades de desenvolvimento de software de IA, e teve um desempenho equivalente aos principais modelos proprietários do mundo. Também foi classificado entre os dois melhores modelos de código aberto no benchmark matemático AIME 2025 e no benchmark interdisciplinar GPQA-Diamond. O MiMo-V2-Flash suporta raciocínio híbrido, permitindo que os usuários alternem entre os modos de raciocínio e resposta rápida. Ele suporta a geração com um clique de páginas HTML completas e a integração com ferramentas de codificação de terceiros, incluindo Claude Code, Cursor e Cline. O comprimento da janela de contexto é de 256.000.tokens, o que permite que o MiMo-V2-Flash execute tarefas em poucoscentenas de rodadas de interação com agentes e chamadas para ferramentas de terceiros.
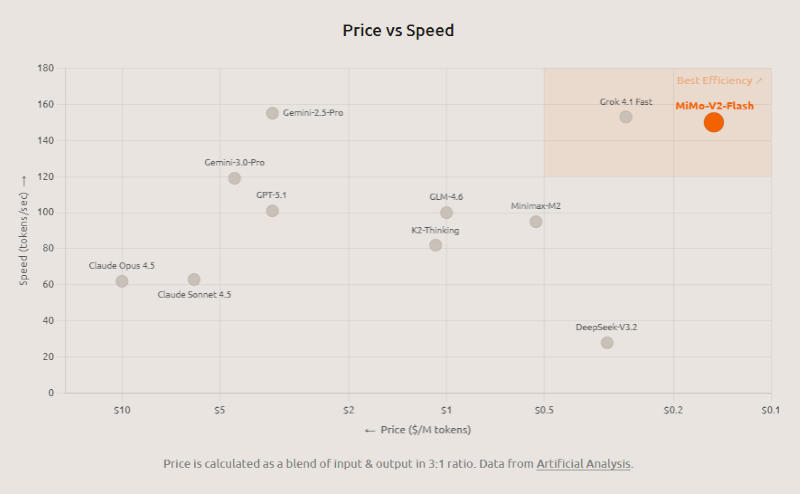
Mecanismos de otimização ajudaram a acelerar o MiMo-V2-Flash para uma taxa de resposta de 150 tokens por segundo — subjetivamente, eles são emitidos quase instantaneamente. Na infraestrutura da Xiaomi, quando conectado via API, o custo de execução do modelo é de US$ 0,1 por 1 milhão de tokens de entrada e US$ 0,3 por 1 milhão de tokens de saída. Além do mecanismo híbrido de atenção total e janela deslizante, o desenvolvedor aumentou a velocidade do modelo treinando-o para gerar múltiplos tokens simultaneamente (Previsão de Múltiplos Tokens, ou MTP): eles são inicialmente gerados em formato de rascunho, verificados e podem ser enviados imediatamente como resposta. Na prática, o modelo gera uma média de 2,8 a 3,6 tokens em paralelo, o que ajuda a acelerar sua operação de 2,0 a 2,6 vezes.
A Xiaomi implementou outra inovação na fase de pós-treinamento do MiMo-V2-Flash: o paradigma de Destilação de Políticas Online com Múltiplos Professores (MOPD). Isso significa que as respostas do modelo treinado são avaliadas em tempo real por modelos mentores, que fornecem feedback não com base em “certo ou errado”, mas sim oferecendo correção de erros. O modelo treinado, por sua vez, analisa suas próprias respostas em vez de agir dentro de cenários predeterminados. Esse esquema utiliza apenas 2% dos recursos computacionais de um modelo tradicional de aprendizado por reforço com ajuste fino (SFT/RL). Além disso, a estrutura descentralizada do MOPD permite que um “aluno” treinado atue posteriormente como um “mentor” — em outras palavras, o modelo se aprimora continuamente.
Com base em uma combinação de testes, o modelo MiMo-V2-Flash demonstra resultados comparáveis aos dos principais sistemas chineses K2 Thinking e DeepSeek V3.2 Thinking. Além disso, em tarefas com contextos longos, a rede neural da Xiaomi superou o K2 Thinking, que é significativamente maior, justificando sua arquitetura de janela deslizante. No teste SWE-Bench Verified, obteve 73,4%, superando todos os seus pares de código aberto e apresentando desempenho quase equivalente ao do OpenAI GPT-5-High. No SWE-Bench Multilingual, resolveu 71,7% das tarefas, confirmando seu status como o modelo de código aberto mais eficaz para desenvolvimento de software. Nos testes τ²-Bench para desempenho de agentes de IA em setores específicos, alcançou pontuações de 95,3 para telecomunicações, 79,5 para varejo e 66,0 para companhias aéreas. No benchmark de agente de busca BrowseComp, obteve 45,4 pontos, e 58,3 pontos quando o gerenciamento de contexto é considerado. Os pesos do modelo, incluindo MiMo-V2-Flash-Base, estão disponíveis no Hugging Face sob uma licença MIT, e o código de inferência foi submetido aos desenvolvedores da estrutura SGLang.