
No último dia do Shipmas, que prometeu mostrar, anunciar e falar sobre novos recursos de IA por 12 dias, a OpenAI revelou um par de grandes modelos de linguagem de próxima geração, o3 e o3-mini, que têm a capacidade de raciocinar.

Fonte da imagem: OpenAI
A OpenAI observa que não estamos falando em lançar novos modelos de linguagem hoje. A empresa explicou que o treinamento dessas redes neurais ainda não foi concluído e o resultado final do seu treinamento pode ser diferente do que diz hoje. Ao mesmo tempo, a OpenAI está aceitando submissões da comunidade de pesquisa para testar esses modelos antes de liberá-los ao público. A empresa ainda não decidiu quando isso acontecerá.
Em setembro deste ano, a OpenAI lançou o modelo de IA pensante o1 (codinome Strawberry). A decisão de chamar os novos modelos de o3 deve-se ao facto de desta forma a empresa ter decidido evitar confusões (ou conflitos de marca) com a empresa britânica de telecomunicações O2.
O termo “modelo de raciocínio de IA” tornou-se recentemente muito popular no desenvolvimento de inteligência artificial e tecnologias de aprendizado de máquina. Porém, em essência, significa apenas que, para resolver uma determinada questão, a máquina divide as instruções fornecidas em tarefas menores. Em última análise, isso permite que você obtenha resultados mais precisos. Os modelos de “raciocínio” de IA geralmente mostram todo o processo de decisão e como a IA chegou a uma resposta específica, em vez de simplesmente dar uma resposta final sem explicação.
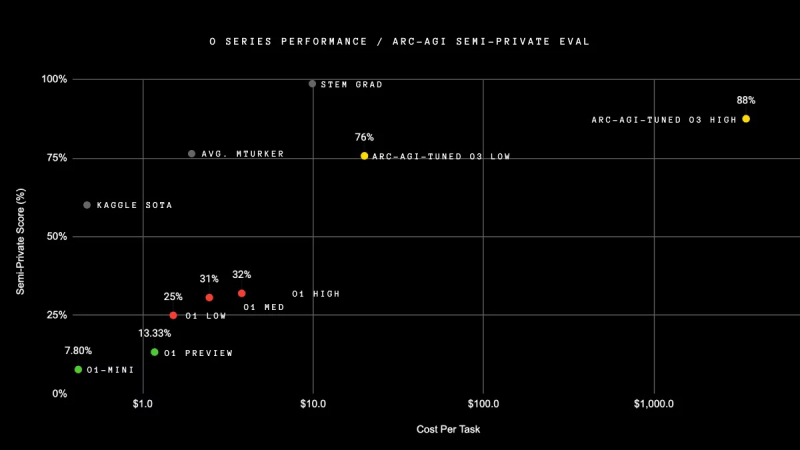
OpenAI afirma que seu novo modelo o3 excede os recordes de desempenho anteriores em todos os aspectos. No teste ARC-AGI, que foi projetado especificamente para comparar as capacidades da inteligência artificial com a inteligência humana, o modelo o3 superou o o1 em mais de três vezes, demonstrando um resultado de 88%.
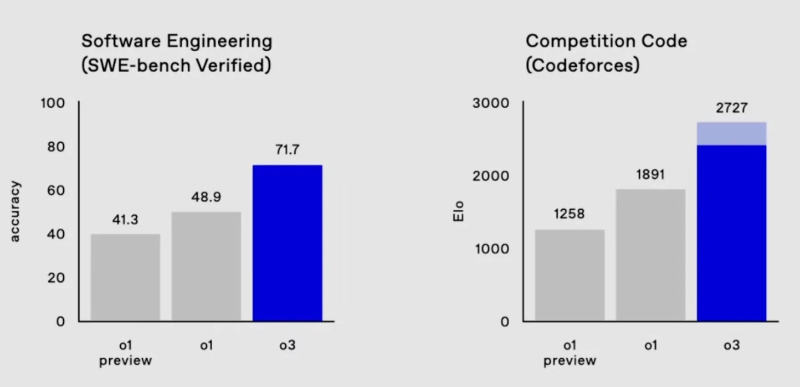
O novo modelo também é 22,8% mais rápido que seu antecessor na escrita de código (teste SWE-Bench Verified) e até superou o cientista líder da OpenAI em programação esportiva.
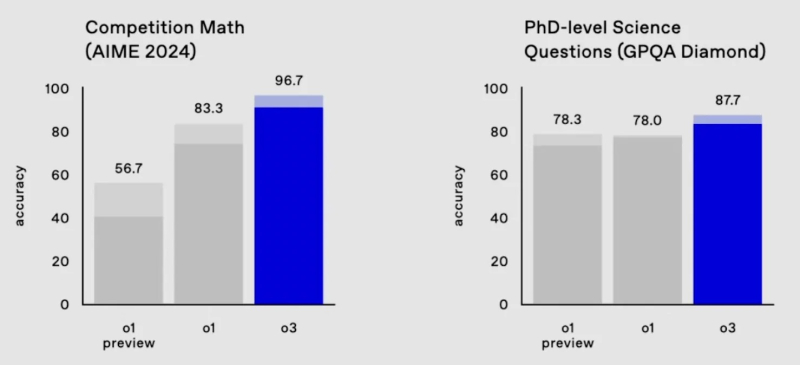
O modelo o3 quase acertou em um dos testes de matemática mais difíceis, AIME 2024, errando apenas uma questão, e também obteve 87,7% no benchmark GPQA Diamond – significativamente mais alto do que qualquer resultado de um especialista humano.
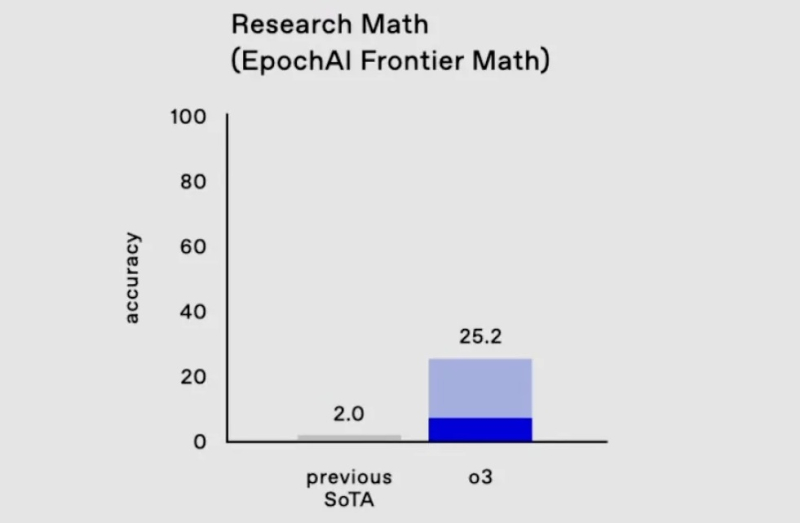
Nos testes mais difíceis de matemática e lógica, que geralmente confundem qualquer outra IA, o3 resolveu 25,2% dos problemas – os resultados de outros modelos não excedem 2%.
Uma vantagem significativa do o3, assim como do o1, é a capacidade dos modelos de “raciocinar” e verificar efetivamente seus próprios fatos, a fim de evitar vários tipos de erros e alucinações. No entanto, os desenvolvedores da OpenAI afirmaram que o processo de verificação de fatos antes de emitir uma resposta leva a um ligeiro atraso – de vários segundos a vários minutos (dependendo da complexidade da pergunta). Além disso, o atraso se deve ao fato de o modelo determinar se a solicitação do usuário está em conformidade com a política de segurança da OpenAI. A empresa afirma que ao testar o novo algoritmo de segurança no o1, ele seguiu as regras de segurança muito melhor do que os modelos anteriores, incluindo o GPT-4.
E, no entanto, como observam os jornalistas do TechCrunch, a principal desvantagem dos modelos de “raciocínio” é que requerem muito mais poder computacional para funcionar, pelo que, no final, a sua utilização é muito mais cara do que as soluções “convencionais”.