
Durante uma grande transmissão ao vivo de apresentação do seu modelo de IA GPT-5, a OpenAI exibiu uma série de gráficos que deveriam ilustrar as impressionantes capacidades do novo modelo. No entanto, após uma análise mais detalhada, alguns dos gráficos apresentavam falhas graves.










Fonte da imagem: Mariia Shalabaieva / unsplash.com
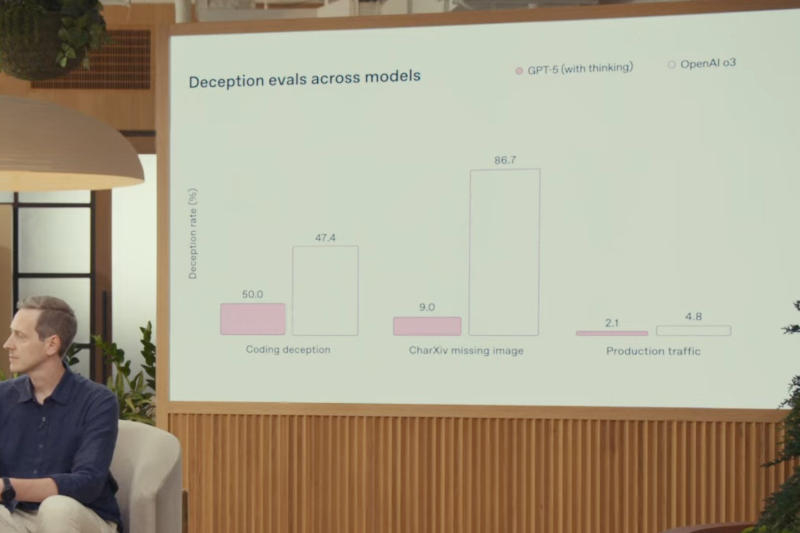
Em um gráfico que, ironicamente, deveria mostrar as altas pontuações do GPT-5 em “avaliação da propensão à fraude em modelos”, a escala não corresponde aos números. Por exemplo, para “fraude de código”, o GPT-5 é listado como 50,0%, enquanto o3 é listado como 47,4%. No entanto, a barra para o3 é mais alta no gráfico. Além disso, o blog corporativo da OpenAI lista um número completamente diferente para o GPT-5 — 16,5%, que provavelmente é o número correto.
Fonte da imagem: x.com/shreyk0
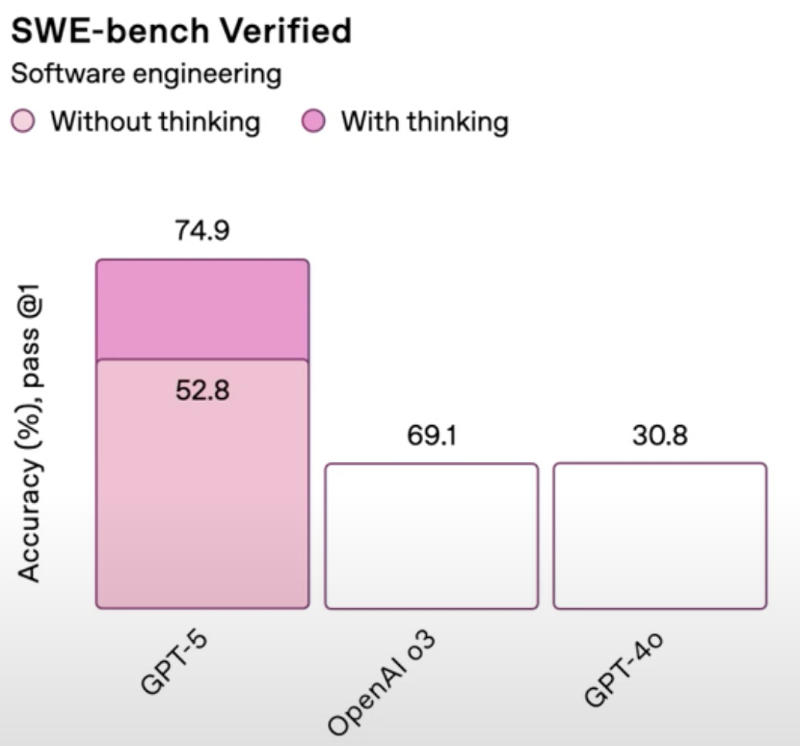
No teste SWE-bench Verified, uma das pontuações do GPT-5 deveria ser menor que a do o3, mas corresponde a uma barra mais alta no gráfico; no mesmo gráfico, as pontuações do o3 e do GPT-4o diferem, mas são ilustradas por barras do mesmo tamanho. A OpenAI levou o erro a sério: o CEO da empresa, Sam Altman, pediu desculpas e acrescentou que as versões corretas foram publicadas no blog corporativo.
Fonte da imagem: x.com/EgeErdil2
A OpenAI não especificou se o próprio GPT-5 foi usado para criar os diagramas, mas tal incidente claramente não acrescenta credibilidade no contexto de uma apresentação em larga escala do novo modelo. Especialmente considerando que os desenvolvedores alegaram que o GPT-5 reduziu significativamente o nível de alucinações.