
Durante o Fórum Econômico Mundial de Davos, em janeiro de 2026, dois pontos de vista opostos entraram em forte confronto sobre inteligência artificial, para usar o termo consagrado em russo, também conhecida como inteligência artificial em sentido amplo (ou seja, não apenas adequada para criar vídeos convincentes com base em instruções de texto ou para traçar rotas de viagem complexas com reservas de hotéis e passagens, mas, em todos os aspectos práticos, indistinguível da inteligência humana biológica) – inteligência artificial geral, IAG. Um grupo de otimistas, liderado por Dario Amodei, CEO da Anthropic (com o apoio implícito, embora ele não tenha participado do evento este ano, mas entusiasmado, de Sam Altman, chefe da OpenAI), insistiu que a IAG não só é alcançável nos próximos anos, como os desenvolvedores já estão caminhando em direção a algum tipo de “superinteligência” artificial que supostamente será “mais inteligente do que todas as pessoas do planeta juntas”. Os pessimistas — ou, mais precisamente, os realistas cautelosos como Demis Hassabis, o laureado com o Prêmio Nobel que lidera o desenvolvimento do modelo Gemini no Google, ou Yann LeCun, pioneiro em IA e redes neurais em geral, ganhador do Prêmio Turing e detentor da mais prestigiosa distinção em ciência da computação — insistiram na inadequação fundamental dos grandes modelos de linguagem (LLMs) que estão sendo ativamente desenvolvidos hoje para alcançar uma IAG (Inteligência Artificial Geral) minimamente comparável ao nível humano.

“Quanto tempo podemos esperar até que finalmente me inventem?” (Fonte: Geração de IA baseada no modelo SeeDream 4.5)
Hassabis, no entanto, acrescentou que, em sua opinião, ainda existe uma chance de 50% (como encontrar um dinossauro) de criar a tão desejada IAG (Inteligência Artificial Geral) nos próximos dez anos — embora, para isso acontecer, “talvez precisemos de mais uma ou duas inovações revolucionárias”. Essas inovações são necessárias em áreas como a capacidade dos modelos de aprender com múltiplos exemplos, comparando-os e analisando-os; de adquirir conhecimento novo de forma contínua e independente; de operar livremente com uma extensa memória de longo prazo; e, finalmente, de desenvolver proativamente, refinando suas habilidades de raciocínio e planejamento — ainda longe do ideal.
E o salto que os desenvolvedores devem dar nesse caminho é fundamentalmente qualitativo: os BNMs (Modelos Nacionais de Inteligência) atuais, estritamente falando, não possuem inteligência alguma; nem geral, nem específica. Eles não passam de papagaios estocásticos (um termo bem estabelecido entre os especialistas), cuja ilusão de comportamento inteligente é meramente uma projeção (para não dizer uma repetição secundária) de dados criados pela inteligência humana real a partir do conjunto de dados com o qual foram treinados. O modelo de linguagem nada mais faz do que concatenar um token a outro, usando regularidades estatísticas com uma pitada de estocástica, mas ele próprio não tem compreensão do que está fazendo. Isso, aliás, explica as alucinações, a suscetibilidade a ataques por meio de “envenenamento” de dicas e conjuntos de dados, e a incapacidade de distinguir a realidade física da ficção. É evidente que, idealmente, a notória IAG (Inteligência Artificial Geral) deveria se livrar deA repetição, ou seja, a retransmissão (com algumas distorções, percebidas como criatividade) de pensamentos obtidos exclusivamente de um conjunto de dados de treinamento, leva à geração de ideias próprias. Partindo de um conjunto pré-aprendido, sim — mas é isso que a mente biológica também faz. Então, por que, exatamente, consideramos uma criança entusiasmada, que recita — muito apropriadamente — citações de grandes filósofos, um intelectual, ou, mais precisamente (e com links diretos para as fontes originais!), que cita as mesmas frases do ChatGPT, Grok ou Claude — não?

“A bunda não é burra! A bunda é estocástica!” (Fonte: Geração de IA baseada no modelo GPT-image-1)
Inteligência é um conceito multifacetado, mesmo quando abordada não de uma perspectiva filosófica, mas puramente prática. Abrange a assimilação de novas informações, a capacidade de resolver problemas emergentes, identificar padrões em conjuntos de dados, trabalhar com questões abstratas e complexas (convencionalmente, inteligência “fluida”) e a aplicação de conhecimento e experiência previamente adquiridos (“inteligência cristalizada”). Mas também existe a inteligência social, essencial para o trabalho em equipe, e a inteligência física (talvez mais precisamente chamada de inteligência corporal — referindo-se à habilidade de coordenar o corpo e manipular objetos no espaço), particularmente característica de atletas de destaque. Mas todas essas definições se aplicam a seres biológicos — com seus corpos e mentes moldados pela evolução. E por qual critério devemos abordar a inteligência artificial? Com base em que critérios devemos julgar se ela é inteligente o suficiente para se equiparar aos humanos? Como, de fato, podemos verificar na prática — quando e se chegar a hora — que a inteligência artificial finalmente se tornou poderosa? O teste de Turing claramente não é mais adequado hoje em dia; uma abordagem diferente é necessária.
⇡#Vamos Definir Definições
E, para começar, seria uma boa ideia definir como medir a inteligência em princípio — aliás, esclarecendo primeiro o que é inteligência, de fato. Primeiro, defina o objeto da medição e, em seguida, o método. A ideia parece sólida, mas sua implementação apresenta certos desafios, a começar pelos próprios conceitos.Definição e método. Isso fica evidente pelo fato de que medir a inteligência, mesmo em pessoas, é uma tarefa difícil. Os testes de QI são bastante eficazes em prever a capacidade de uma pessoa resolver certos problemas, o que, com algumas ressalvas, pode de fato ser considerado uma medida de inteligência — no contexto moderno da civilização urbana ocidental. Mas digamos que um caçador-coletor com uma lança e um arco improvisados sobreviva perfeitamente bem em sua natureza selvagem e inóspita, embora provavelmente obtivesse uma pontuação inferior a cinquenta pontos neste teste. Enquanto isso, um respeitado professor de Harvard com um QI acima de 130, nas mesmas condições e com o mesmo equipamento, dificilmente duraria mais do que três a cinco dias. Então, qual deles, nos perguntamos, possui a inteligência superior?
Para provar que você não é um robô, tente… ah, esquece; isso não vem mais ao caso (fonte: Prêmio Nobel de QI).
O problema é que é improvável que a inteligência possa ser definida universalmente — isoladamente do ambiente em que a atividade mental é aplicada. Não é de se admirar que ela seja comumente interpretada como uma habilidade cognitiva geral que se manifesta na forma como seu portador percebe, entende, explica e prevê o que está acontecendo consigo, principalmente consigo mesmo, quais decisões toma e com que eficácia age — especialmente, aliás, em situações incomuns. Caso contrário, o comportamento de um indivíduo se reduz a um coquetel mais ou menos complexo de reflexos condicionados; reações padronizadas a estímulos familiares. Os antropólogos chegam a definir inteligência como a capacidade de resolver problemas não convencionais usando métodos não convencionais — levando em conta, é claro, a experiência prévia.
Parece que tudo finalmente se encaixou: o papagaio estocástico é a priori incapaz de recorrer a métodos não padronizados — aqueles não presentes na amostra de dados com a qual foi treinado — muito menos de tomar qualquer decisão. O sistema recebe uma solicitação, decompõe-na em uma cadeia de tokens, continua essa cadeia de acordo com os padrões memorizados durante o treinamento e fixados na forma de pesos nas entradas de seus perceptrons, traduz a cadeia resultante de tokens de resposta em um conjunto de letras e sinais de pontuação (ou uma imagem, ou um vídeo — não importa) e a entrega ao operador. Não há compreensão da pergunta feita, nenhuma iniciativa na busca por uma resposta, nenhuma não-padronização de qualquer tipo (a menos que se considere a já mencionada pitada de estocástica adicionada por(Durante o processo autorregressivo) basicamente não existe nada assim aqui. O assunto está fora de questão; Hassabis e LeCun estão certos, a IAG não pode ser alcançada por meio do BNM — vamos deixar para lá até que surjam abordagens fundamentalmente novas para organizar a inteligência artificial. Ou talvez não?

“Sou eu uma criatura trêmula ou tenho o direito de olhar para a luz?” (Fonte: Geração de IA baseada no modelo Nano Banana)
Na realidade, a situação é um pouco mais complexa, sobretudo devido ao amplo escopo do termo “inteligência” (do latim intellectus, que significa “entendimento, compreensão”), que se tornou significativamente vago ao longo de séculos de pesquisa filosófica, psicológica e social. A confusão começou com Immanuel Kant, que inverteu a distinção entre intellectus e ratio (razão) como faculdades cognitivas superiores e inferiores, familiares aos escolásticos medievais. Assim, o termo metafísico — pré-kantiano — intellectus denotava uma compreensão suprassensível de entidades espirituais, não relacionada à experiência mundana e bruta; simplex intuitus na terminologia tomista. Ratio, por sua vez, referia-se a uma abstração banal e elementar; A capacidade de extrair o geral do particular, que, em certo sentido, é acessível até mesmo às amebas: afinal, elas evitam a luz intensa e as temperaturas extremas, movendo-se para onde se sentem mais confortáveis — e, assim, transformam sua percepção sensorial, insignificante em comparação à nossa, em algo completamente prático e racional, ainda que ininteligível (elas simplesmente não têm nada a ver com isso, já que não possuem sistema nervoso).
Assim, se a ratio é característica da vida mundana, material, ativa, que requer comparações, raciocínio, tentativa e erro — e por essa razão, no sentido escolástico, básica —, então o intellectus, ao contrário, manifesta-se por meio da contemplação, da iluminação, da compreensão passiva da causa raiz do fenômeno compreendido; e, portanto, pode ser atribuído a qualidades divinas. A filosofia germânica antiga seguiu essa tradição, designando a ratio como discursiva, racional,razão lógica – como Vernunft (que em tradução do alemão significa “razão”), e intellectus – a mais alta penetração metafísica na essência das coisas – como Verstand (o significado principal é precisamente “entendimento”).

Immanuel Kant, um súdito leal de Sua Majestade Imperial Elizabeth Petrovna, critica a Razão Pura perante uma grande assembleia de pessoas seriamente interessadas; desenho de Pieter Bruegel, o Velho (fonte: geração de IA baseada no modelo Nano Banana).
Em sua obra seminal, Crítica da Razão Pura, Kant questionou a metafísica escolástica tradicional — uma vez que seu objeto de estudo está além do alcance da experiência humana, ela não pode ser uma ciência exata cujas proposições são derivadas logicamente e confirmadas experimentalmente. Aliás, seguindo Leibniz (Gottfried Wilhelm Leibniz), o filósofo definiu “pura” como a razão desprovida de conteúdo empírico; a razão em si, como a própria capacidade de cognição — não seria ela, em seu estado inicial, uma rede neural profunda, com pesos zero nas entradas de todos os perceptrons? Ao negar a intuição intelectual à mente humana — isto é, a compreensão direta das essências/causas primeiras/realidades metafísicas — Kant demonstrou que o intelecto humano é essencialmente discursivo e, por essa mesma razão, chamou de Vernunft aquela tentativa presunçosa, “tendendo à metafísica”, de apreender o absoluto fundamentalmente incompreensível — o que inevitavelmente leva a uma descida à ilusão. Em última análise, o filósofo designou a análise da experiência com a palavra Verstand; a habilidade bastante comum de formular conceitos aplicados e construir conclusões lógicas com base empírica. Ele chamou de Vernunft a mais alta capacidade de formular ideias metafísicas (e, ao mesmo tempo, expor dialeticamente as ilusões transcendentais), o antigo intellectus.
Essa classificação foi posteriormente adotada por Hegel (Georg Wilhelm Friedrich Hegel) e, mais tarde, por outros.Filósofos modernos. Foi com sua sutileza que o termo “inteligência” permeou as traduções — tanto para o russo quanto para o inglês — como o Verstand de Kant. O significado escolástico anterior desse termo — “compreensão direta” por meio de revelação divinamente inspirada vinda de fora — foi herdado pelo Vernunft, entendido como a capacidade de desenvolver ideias especulativas incondicionais (como “liberdade” ou “imortalidade”), abstraídas da prática bruta. E, como o Verstand de Kant implica o uso ativo de categorias inatas (como causalidade, substância e unidade) para formar experiências coerentes e significativas na consciência do indivíduo, esse processo está intimamente ligado à autoconsciência e à autonomia moral — ambas claramente ausentes na IA moderna. Talvez, aliás, seja uma coisa boa que estejam ausentes: uma IA moralmente autônoma seria bastante capaz de representar uma ameaça para a humanidade.
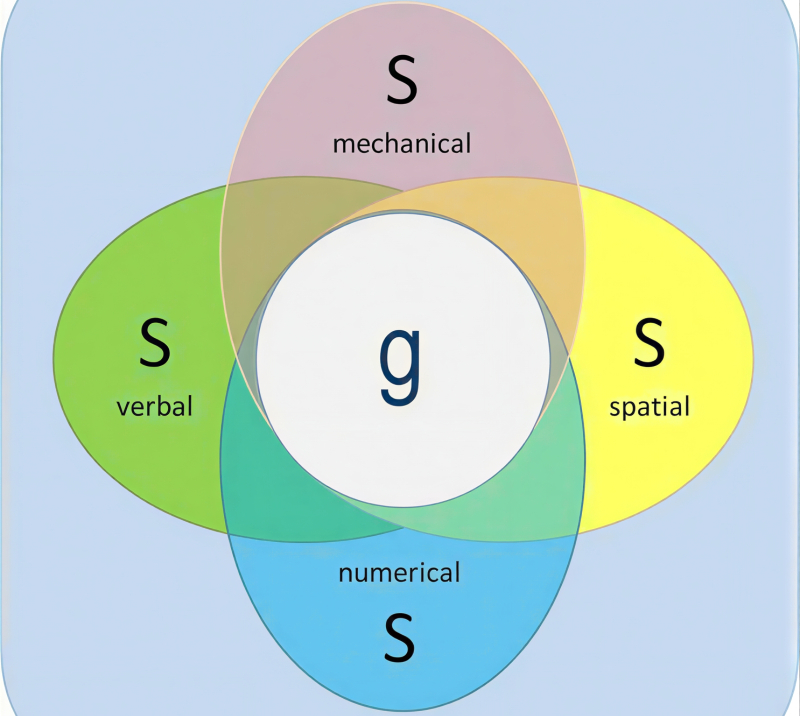
Os fatores s especializados de várias habilidades mentais determinam indiretamente o fator g geral da inteligência (fonte: Simply Psychology)
⇡#Tudo se resume ao fator G
No entanto, existem muitos paralelos entre a definição kantiana de inteligência e o conteúdo semântico transmitido pelo mesmo termo na expressão “IA” (Inteligência Artificial). E a questão não se limita à filosofia clássica: no final do século XIX e início do século XX, em meio à industrialização desenfreada e à transição generalizada para o serviço militar obrigatório, a necessidade de mensurar a inteligência tornou-se premente, deixando de lado até mesmo a questão de sua natureza física ou metafísica. Ficou evidente que algumas pessoas conseguem operar uma máquina a vapor com segurança, mesmo em situações críticas, enquanto outras estão fadadas a receber as chaves erradas; que um recruta dominará a telegrafia sem fio em uma semana, enquanto outro não deve ser confiado com nada mais frágil do que um pé de cabra para varrer o campo de desfile.
Nesse sentido, a abordagem testológica (ou psicométrica) para o estudo da inteligência começou a se desenvolver: Charles Edward Spearman, um dos pioneiros da psicometria, forneceu uma base estatística para o conhecido ditado: “Uma pessoa talentosa é talentosa em tudo”. Ele observou, ao estudar os resultados dos exames escolares no início do século XX, que se um aluno obtivesse uma nota alta em uma matéria, então, com alta probabilidade, ele também teria um desempenho acima da média em outras. Spearman atribuiu a correlação positiva entre áreas formalmente não relacionadas da atividade mental à influência de um certo fator predominante, que ele denominou g (de geral, é claro – a mesma palavra que mais tarde seria usada para descrever o termo “g” em inglês).(Este termo, que se tornou parte do acrônimo “AGI”), refere-se a um fator geral de inteligência. Ele simplesmente chamou as habilidades específicas de uma determinada atividade mental de “fatores-s”. Assim, um teste quantitativo para identificar a magnitude do fator g neste modelo consiste em medir e contabilizar corretamente (já que, a priori, não estão em equilíbrio) um certo número de fatores-s — por meio de testes relativamente simples e bem calibrados. E embora a psicometria tenha evoluído significativamente desde então — por exemplo, a metodologia de Raymond Cattell distingue entre fases “fluidas” e “solidificadas” das habilidades mentais, Gf (de fluido) e Gc (de cristalizado) — o fator g continua sendo a base para medições quantitativas da inteligência humana em testes de QI e similares, que têm aplicações puramente práticas. Especialmente para empregadores: pesquisas acadêmicas mostram que pessoas com pontuações mais altas em inteligência quantitativa têm melhor desempenho em tarefas porque processam informações mais rapidamente e conectam ideias díspares com mais eficácia, criando novas ferramentas aplicadas por meio de sua síntese.

No início de 1996, o computador Deep Blue da IBM fez história no xadrez ao derrotar decisivamente o então campeão mundial humano, sob as regras clássicas de torneio — e a coroa do xadrez nunca mais retornou ao Homo sapiens (fonte: IBM).
À medida que a complexidade do trabalho aumenta, também aumenta a importância da inteligência — e essa conclusão é tão verdadeira para as diversas implementações de IA quanto para um funcionário de escritório ou um professor universitário. Mas como comparar diretamente um ser humano a uma máquina? Deveríamos usar o mesmo teste de QI, visto que os modelos generativos são especialmente requisitados hoje para a resolução de problemas aplicados? Pelo menos, foi o que o próprio Altmann afirmou há muito tempo: “Grosso modo, na minha opinião — esta não é uma definição científica, apenas uma impressão —, a cada ano aumentamos o QI da nossa IA em um desvio padrão.” De fato, quando formalizados ao extremo, esses testes são perfeitamente adequados para alimentar chatbots multimodais. Mas essa formalização também tem uma desvantagem: tendo aprendido (especialmente por meio de aprendizado por reforço) como resolver corretamente os problemas apresentados, o papagaio estocástico se tornará cada vez melhor nisso — compensando com a eficiência computacional de sua rede neural a falta de inteligência humana, que era o que o QI originalmente se propunha a medir. Mesmo deixando de lado o uso controverso desse teste como a única medida das habilidades cognitivas humanas, certamente não é adequado para identificar o momento da suposta transição da IA simples para a IAG (Inteligência Artificial Geral).
E então, o que dizer do xadrez? Nem hoje é tão engraçado quanto era na década de 1950.Pesquisadores da IBM chegaram a especular seriamente que “se conseguíssemos criar uma máquina de xadrez capaz de competir com sucesso contra um humano, isso nos daria uma visão sobre o que acontece no cérebro biológico durante a busca intelectual”. Mas não; o Deep Blue, construído e programado pela mesma empresa, embora tenha derrotado o então campeão mundial de xadrez em 1997, ainda que não na primeira tentativa, não demonstrou nenhum sucesso significativo em outras áreas. O teste mencionado anteriormente para distinguir máquinas inteligentes de humanos, proposto por Alan Turing em 1950, não funciona mais para os modernos BNMs do nível do GPT-4.5: durante uma conversa online de cinco minutos com o bot em 2025, 73% dos voluntários o reconheceram como humano — apesar de terem feito perguntas deliberadamente sobre uma ampla gama de áreas do conhecimento e de terem tentado detectar sinais de “artificialidade” no próprio estilo de sua linguagem. Não se engana um papagaio estocástico com palha; ele imita perfeitamente. E, em todo caso, o teste de Turing é qualitativo (máquina/humano, “1”/”0″), não quantitativo. No entanto, se nos lembrarmos do significado original da letra “g” na sigla AGI e nos basearmos no conhecimento acumulado sobre os pontos fortes e fracos das IAs atuais, ainda é possível comparar diretamente a inteligência artificial com a inteligência humana.
Uma das tarefas propostas pelo ARC sobre abstração e raciocínio: uma IA deve derivar regras abstratas, neste caso, definindo o arranjo mútuo de figuras em um plano sem sobreposições ou vazios, a partir de apenas alguns exemplos (fonte: Fundação Prêmio ARC).
⇡#Flexibilidade à Beira da Fluidez
Assim como Charles Spearman tentou estimar seu fator g medindo uma infinidade de fatores s heterogêneos, François Chollet, ex-Google e posteriormente fundador da startup de IA Ndea, propôs em 2019 avaliar indiretamente a capacidade intelectual de redes neurais. Especificamente, ele determinaria até que ponto um determinado modelo é, em princípio, capaz de adquirir novas habilidades e com que facilidade e rapidez o faz. Essa abordagem, é claro, também é controversa: se a inteligência forte é percebida como uma superposição de habilidades cognitivas individuais, então, idealmente, todas elas deveriam ser medidas. Contudo — lembremos a definição antropológica de inteligência — a disposição de um sistema que se declara inteligente em desenvolver novas maneiras de resolver problemas antes inexplorados pode, de fato, ser considerada o indicador mais confiável de sua inteligência condicional. No mínimo, se uma IA não for capaz de adquirir novas habilidades, certamente jamais se tornará uma IAG (Inteligência Artificial Geral). Tomemos, por exemplo, os notórios primeiros BNMs (Máquinas Naturais de Robótica) — aqueles sem acesso à internet, não equipados com circuitos de “raciocínio” e não preparados para passar por aprendizado por reforço diretamente por meio da comunicação com o operador: se a resposta para uma pergunta que lhes fosse feita não estivesse contida no banco de dados de treinamento, eles, na melhor das hipóteses, admitiriam sua incapacidade e, na pior, teriam alucinações.
Sholle
SholleChollet propôs o benchmark Abstraction and Reasoning Corpus (ARC), atualmente denominado ARC-AGI-1, para redes neurais que almejam o prestigioso título de Inteligência Artificial Geral (IAG). Ele consiste em centenas de problemas de quebra-cabeça visual: cada problema contém diversas demonstrações — aqui está a condição, aqui está a solução correta — e um teste de controle. Isso testa precisamente a inteligência flexível (“de fase fluida”) que a escola de Cattell enfatiza, e na qual as Redes Neurais de Bayes clássicas são francamente fracas. Resolver os quebra-cabeças propostos não exige conhecimento prévio — você precisará da capacidade de identificar a coerência dos objetos, detectar sinais de simetria e identificar elementos complementares. Em resumo, você precisará do tipo de senso comum (praticamente um Verstand kantiano) que crianças em idade pré-escolar capazes de resolver problemas semelhantes possuem. A ideia de Chollet provou ser tão bem-sucedida que, por cinco anos, o ARC-AGI-1 eliminou de forma confiável os concorrentes ao título de “quase IAG”, atribuindo-lhes pontuações pateticamente baixas. No entanto, a OpenAI se recuperou e lançou o modelo de “raciocínio” o3, que superou um grupo de controle de especialistas em biologia. É verdade que a vitória foi pírrica — o custo computacional para resolver um dos quebra-cabeças foi estimado em US$ 20.000 —, mas quem disse que a Inteligência Artificial Geral (IAG) nas plataformas de hardware atuais seria barata?

Menos de um ano se passou desde a introdução de um novo benchmark de IA “superdesafiador”, e já existem modelos com pontuação acima de 70% (fonte: ARC Prize Foundation).
No entanto, o ARC-AGI-1 não escapou das críticas que caracterizam quase todos os benchmarks de TI (não apenas de IA). Como seu conjunto de testes é necessariamente limitado — caso contrário, como poderíamos falar em uma comparação justa de resultados entre os participantes? — os modelos desafiados frequentemente buscavam soluções corretas por força bruta em vez de “adquirir novas capacidades” e/ou sofrer sobreajuste, sacrificando sua versatilidade para alcançar pontuações mais altas em um teste excepcionalmente difícil. Por fim, o próprio Chollet admitiu que passar com sucesso na primeira versão do teste não indica, de forma alguma, a conquista da IAG (Inteligência Artificial Geral) — já que, novamente, captura apenas o fato de resolver um problema específico, e não a ampla adaptabilidade ou o desenvolvimento do proverbial senso comum no sistema, após o qual se pode começar a questionar seu grau de inteligência.
Em março de 2025, o ARC-AGI-2 foi apresentado ao mundo, agora sob a supervisão de uma organização sem fins lucrativos, a ARC Prize Foundation, com a missão declarada de “servir como guia para a criação de inteligência artificial, estabelecendo parâmetros de referência de longo prazo”. O prêmio de US$ 1 milhão (“Esses são números de novato!” — como Google, Microsoft, Nvidia e outros gigantes bilionários da indústria global de IA parecem nos dizer) deve ser distribuído entre as equipes cuja IA consiga resolver 85% ou mais dos 120 novos problemas — MAS! — com limitações significativas: usar apenas quatro GPUs e em 12 horas ou menos.De fato, tornaram-se mais complexas: agora exigem a identificação e aplicação simultânea de múltiplas regras a partir de exemplos fornecidos, a realização de raciocínio coerente em múltiplos estágios, a interpretação de símbolos específicos, etc. O resultado médio de uma pessoa submetida ao ARC-AGI-2 é de cerca de 60%, e seis meses após o teste ser disponibilizado publicamente, a melhor IA da época, Grok 4 (Thinking), apresentou apenas 16%. No entanto, no momento da redação deste artigo, os principais modelos generativos melhoraram consideravelmente: Claude Opus 4.6 (120K, High) alcançou 69,2% com um custo de solução de US$ 3,47 por tarefa, Gemini 3 Pro (Refine) – 54,0% a US$ 30,57 por tarefa e GPT-5/2 (Refine) – 72,9% a US$ 38,99 por tarefa. E os especialistas, mais uma vez, não estão tanto esfregando as mãos em antecipação à chegada iminente, quase imediata, da IAG (Inteligência Artificial Geral) ao público (Sam Altman está esfregando as mãos, é claro — mas ele vem fazendo isso sem parar há anos), quanto reclamando, como de costume, de sobreajuste e ataques de força bruta — certamente agora em um nível significativamente novo e muito mais avançado. Assim, o ARC-AGI-3, um benchmark com tarefas dinâmicas (minijogos no mesmo campo retangular), está atualmente em desenvolvimento — mas não há dúvida de que a história se repetirá em grande parte com ele.

Os interessados podem experimentar uma versão de pré-visualização do ARC-AGI-3 em three.arcprize.org: lembrem-se apenas de que não há instruções para esses minijogos — vocês terão que descobrir os controles, as regras e o objetivo final (fonte: ARC Prize Foundation).
Quebra-cabeças gráficos como os oferecidos pelo ARC representam um desafio realmente sério para os modelos de IA modernos — especialmente porque, nas aplicações práticas em que esses modelos são usados regularmente, eles não precisam montar quebra-cabeças de quadrados coloridos. Especialistas afirmam que esse tipo de benchmark é uma boa diretriz teórica que ajuda a desenvolver as capacidades dos Modelos de Navegação Baseados em Bing (BNM), mas ainda não contribui para alcançar os níveis de Inteligência Artificial Geral (IAG). No entanto, o caminho geral delineado por Chollet parece bastante razoável: apresentar a uma IA uma ampla gama de desafios, e a melhoria em cada um deles indicará seu progresso geral na direção g. Contudo, em vez da avaliação um tanto arbitrária da “capacidade de adquirir habilidades” na resolução de quebra-cabeças gráficos, faz sentido empregar meios mais diversos. Especificamente, resolver problemas multimodais (usando texto, gráficos estáticos, vídeo, áudio e modelagem 3D), criar mundos virtuais estáveis e atingir objetivos específicos dentro deles, jogar videogames projetados para humanos, etc.
E isso é apenas o começo: para atingir o nível de inteligência verdadeiramente avançada, a IA terá que aprender a conduzir uma comunicação social adequada com outros seres inteligentes (principalmente com humanos).(Embora você possa começar com suas colegas inteligências artificiais), operar no mundo real (muito menos tolerante a erros do que mundos virtuais), definir metas de forma independente e determinar os meios para alcançá-las. Aqui, retornamos à questão de até que ponto a autonomia moral de uma IAG — quando e se ela a alcançar — corresponderá à de um ser humano (e qual ser humano, aliás? Seriam bandidos e estranguladores?) E também sobre qual caminho a inteligência artificial deveria seguir se uma BNM baseada em redes neurais profundas for realmente um beco sem saída; esta é uma opinião bastante difundida entre os especialistas, que, aliás, é compartilhada pelo próprio François Chollet. Então, como a inteligência artificial pode ser fortalecida para que um dia alcance o nível da notória IAG? Existem ideias, mas este tópico merece uma discussão à parte.