
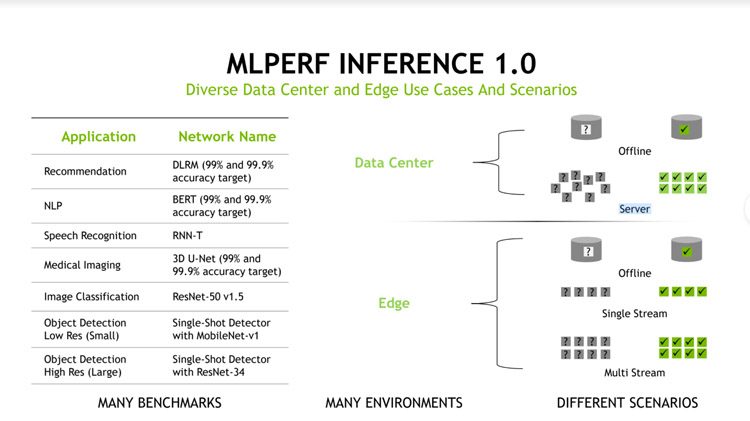
Open Engineering Consortium MlCommons Postado por Resultados de Benchmarque Mlperf Inferência V1.0, testando testes para avaliar o desempenho dos sistemas da Insta. Mlperf – reconhecido no ramo do benchmark para medir o desempenho da AI em várias tarefas, incluindo visão de computador, imagens médicas, sistemas de recomendação, reconhecimento de fala e processamento da linguagem natural.
As aplicações de 17 organizações foram submetidas à última rodada de testes, e 1994 resultados de resposta para sistemas de aprendizagem de máquina na categoria de dispositivos periféricos e servidores de data centers foram publicados. O pacote Mlperf Inference V1.0 apresenta novos métodos, ferramentas e indicadores que complementam os testes de desempenho.
Esses novos indicadores permitem que você compile relatórios e compare o consumo de energia, o desempenho e o consumo de energia. O benchmark foi desenvolvido em conjunto com a Avaliação Padrão de Desempenho Corp. (Spec), um fornecedor líder de testes padronizados e ferramentas para avaliar o desempenho dos modernos sistemas de computação. Em particular, o MLPERF usa ferramentas de medição de energia de especificação de ptdaemon.
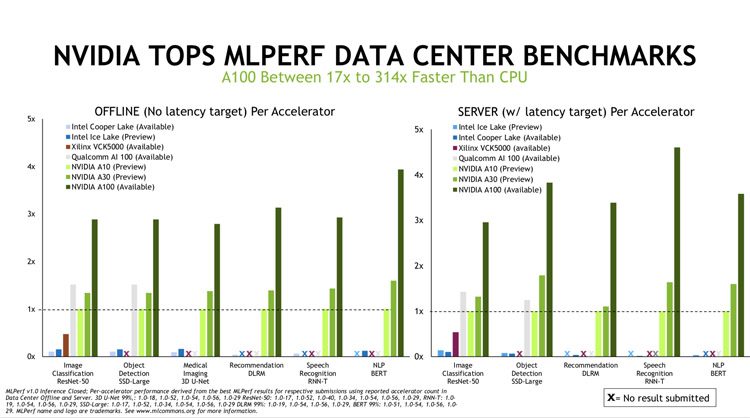
A NVIDIA tornou-se a única empresa que apresentou os resultados de todos os testes nas categorias de data center e sistemas periféricos. Além de seus próprios resultados, Nvidia, parceiros de Alibaba, Dellemc, Fujitsu, Gigabyte, HPE, Insurre, Lenovo e Supermicro apresentaram um total de mais de 360 resultados de seus sistemas baseados em aceleradores da NVIDIA.
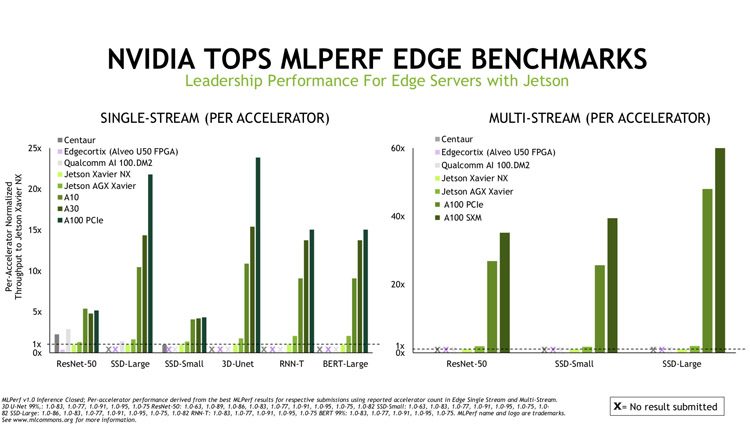
A NVIDIA informou que sua plataforma INFERLA, recentemente reabastecida com os processadores gráficos da NVIDIA A30 e A10 para servidores, apresentou desempenho recorde em todas as categorias. De acordo com a empresa, foram alcançadas altas taxas devido à ampla gama de ecossistemas NVIDIA E, cobrindo uma ampla gama de processadores gráficos e software e software, incluindo Tensorrt e NVIDIA Triton Inference Server.

Além disso, a NVIDIA demonstrou as capacidades da arquitetura da NVIDIA Ampere da GPU multi-instance, enquanto executando todos os sete testes off-line MLPerf em um processador gráfico usando sete instâncias MIG, que mostrava quase o mesmo desempenho (98%), como no caso de uma única instância MIG.