
Segundo a previsão da Gartner, até 2030, a inferência de modelos de aprendizado de máquina (LLM) com um trilhão de parâmetros será mais de 90% mais barata para provedores de serviços de IA em comparação com 2025. Isso não significa acesso universal à computação avançada.
Para o estudo, a Gartner “avaliou” cada token em 3,5 bytes, ou aproximadamente quatro caracteres de texto em inglês. Especialistas preveem que essa redução de custos será impulsionada por uma combinação de maior eficiência em chips de IA e infraestrutura de suporte, inovações no desenvolvimento de modelos, maior utilização de chips, uso expandido de aceleradores de inferência especializados e a proliferação da computação de borda para cenários específicos.
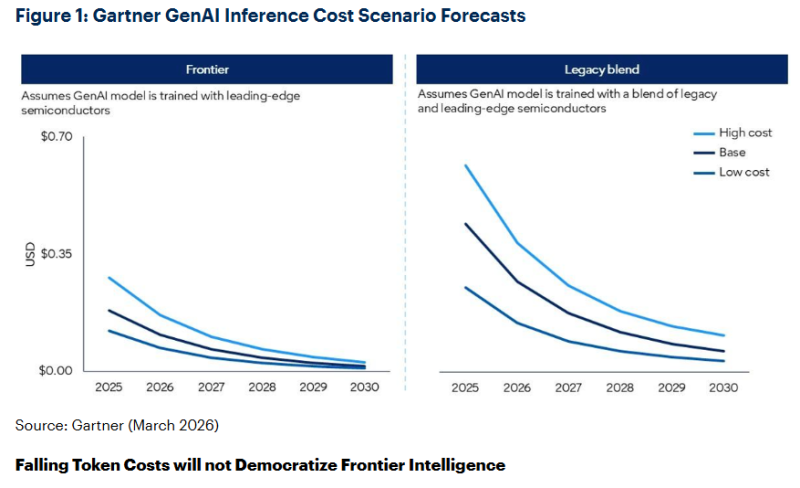
Como resultado, a Gartner prevê que, até 2030, os LLMs serão 100 vezes mais econômicos do que os primeiros modelos de escala semelhante introduzidos em 2022. De acordo com os cálculos da Gartner, executar modelos em chips de IA de ponta será previsivelmente muito mais barato do que usar hardware mais antigo ou misto baseado em semicondutores mais acessíveis, dada a sua menor capacidade de processamento. A NVIDIA, em particular, menciona isso regularmente.
Fonte da imagem: Gartner
No entanto, a queda nos preços dos tokens não significa necessariamente que as tecnologias avançadas se tornarão mais acessíveis a todos. Em primeiro lugar, a redução nos custos de produção para provedores de IA não se traduzirá em uma queda proporcional nos preços para clientes corporativos. Além disso, as tecnologias avançadas de IA exigirão significativamente mais tokens do que hoje. Por exemplo, agentes de IA requerem de 5 a 30 vezes mais tokens por tarefa do que um chatbot típico e são capazes de executar muito mais tarefas do que um humano típico usando IA.
Embora as capacidades da IA se expandam, isso será acompanhado por um aumento “desproporcionalmente grande” na demanda por tokens. O consumo está crescendo mais rápido do que a queda nos preços, portanto, espera-se que os custos de inferência aumentem. Ressalta-se que não se trata de democratizar a computação avançada. O custo da IA ”padrão” de fato continuará a cair, mas os recursos necessários para projetos complexos de IA permanecerão escassos. Os gerentes de projetos de IA, que atualmente mascaram as deficiências de suas arquiteturas com a queda nos preços dos tokens, enfrentarão desafios para escalar as computações baseadas em agentes de IA.
Segundo a Gartner, as plataformas mais procuradas serão aquelas que permitem a coordenação de cargas de trabalho distribuídas por um portfólio de modelos. Tarefas rotineiras devem ser delegadas a modelos de IA pequenos e especializados, que são mais adequados e econômicos para fluxos de trabalho específicos do que soluções de uso geral. Enquanto isso, os recursos dispendiosos de modelos avançados devem ser alocados com restrições rigorosas, reservando-os apenas para tarefas complexas, masInferência de alta margem.
Se você notar um erro, selecione-o com o mouse e pressione CTRL+ENTER. | Você pode melhorar? Ficaremos felizes em receber seu feedback.
Fonte: