
A SiFive apresenta a segunda geração da família RISC-V Intelligent Core, que inclui os novos núcleos X160 Gen 2 e X180 Gen 2, bem como as soluções atualizadas X280 Gen 2, X390 Gen 2 e XM Gen 2. As novas soluções foram projetadas para oferecer recursos avançados de processamento escalar, vetorial e, no caso da série XM, matricial, adaptados às cargas de trabalho de IA atuais.
Conforme observado pelo EE Times, ao anunciar a nova linha de produtos, a SiFive visa capitalizar a crescente demanda por cargas de trabalho de IA, que a Deloitte prevê um crescimento de pelo menos 20% em todos os ambientes tecnológicos, incluindo um aumento impressionante de 78% na computação de IA de ponta.
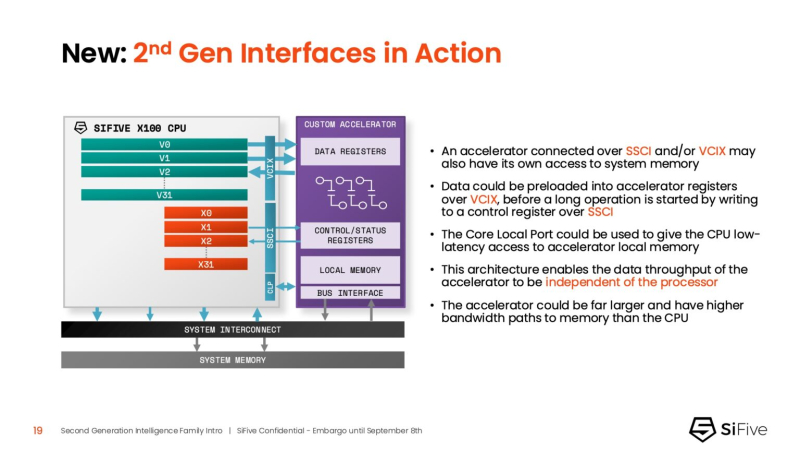
Os núcleos SiFive de segunda geração atendem a cargas de trabalho críticas de IA, como gerenciamento de memória e aceleração de funções não lineares. Uma inovação fundamental nos processadores da série X é sua capacidade de funcionar como uma unidade de controle do acelerador (ACU). Isso permite que os núcleos SiFive forneçam funções essenciais de controle e suporte para o acelerador do cliente por meio da Interface de Coprocessador Escalar (SSCI) e da Extensão da Interface de Coprocessador Vetorial (VCIX) do SiFive. Essa arquitetura permite que os clientes se concentrem na inovação de processamento em nível de plataforma, otimizando a pilha de software.

Crédito da imagem: SiFive/ServeTheHome
John Simpson, arquiteto-chefe do SiFive, disse ao EE Times que os núcleos inteligentes do SiFive oferecem flexibilidade, reduzem o tráfego do barramento do sistema ao processar localmente no chip acelerador e proporcionam um acoplamento mais estreito para tarefas de pré e pós-processamento. Ele disse que o SiFive introduziu duas importantes melhorias arquitetônicas que abordam diretamente os gargalos de desempenho: tolerância à latência da memória e um subsistema de memória mais eficiente.
A Tolerância à Latência de Memória é um recurso que ajuda a reduzir a latência de carga. Simpson explicou que a unidade de computação escalar, que processa todas as instruções, envia instruções vetoriais para a fila de comandos vetoriais (VCQ). Quando uma é encontrada, uma solicitação é enviada simultaneamente ao subsistema de memória (cache L2 ou superior). O envio antecipado de solicitações, separado da execução, permite que a resposta seja recebida da memória mais cedo e colocada na Fila de Carregamento de Dados Vetoriais (VLDQ) reordenável. Isso garante que os dados estejam prontos quando a instrução finalmente sair da VCQ, resultando em “um carregamento vetorial dentro de um ciclo”.
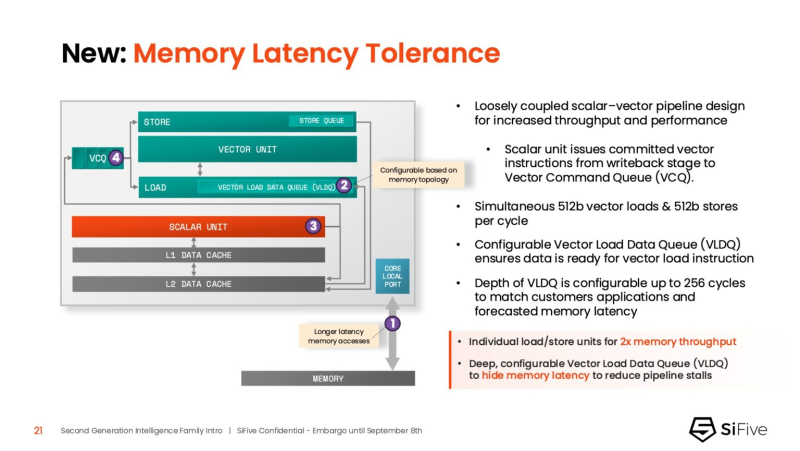
Simpson enfatizou a vantagem competitiva da solução, observando: “O Xeon que mostramos na Hot Chips pode atender a 128 solicitações pendentes, o que é o melhor para o Xeon, e nosso processador quad-core pode atender a 1.024”. Essa “bela tecnologia” garante que os dados sejam processados continuamente, prevenindo efetivamente paralisações no pipeline.
O subsistema de memória mais eficiente, que é outra atualização significativa, baseia-se na mudança de uma hierarquia de cache inclusiva para uma não inclusiva. No sistema de cache inclusivo da geração anterior, os dados do cache L3 compartilhado eram replicados para caches L1/L2 privados, o que a empresa considerou um uso ineficiente de “silício”. O design do núcleo da segunda geração elimina a cópia, o que, segundo Simpson, oferece “1,5x o desempenho da primeira geração” em um chip menor.
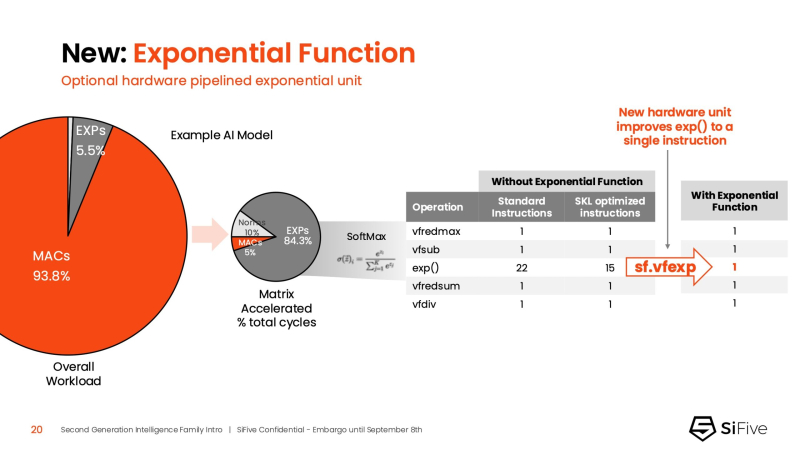
O SiFive também integrou uma nova unidade exponencial com pipeline de hardware. Embora as operações MAC dominem as cargas de trabalho de IA, a exponenciação está se tornando o próximo grande gargalo. Por exemplo, em LLMs BERT acelerados pelo mecanismo de matriz, as operações softmax envolvendo exponenciação ocupam mais de 50% dos ciclos restantes. Com otimizações de software, o SiFive reduziu a execução da função de exponenciação de 22 para 15 ciclos, e a nova unidade de hardware a reduz para uma única instrução, reduzindo o tempo total de execução da função para cinco ciclos.
A pilha de software para a família Intelligence de segunda geração suporta escalabilidade. Na série XM, o tempo de execução de aprendizado de máquina já distribui cargas de trabalho entre vários clusters XM em um único chip. No entanto, escalar além de um único chip requer um desenvolvimento adicional da biblioteca de comunicação entre processos (IPC).
As principais soluções X160 Gen 2 e X180 Gen 2 podem ser configuradas para executar um sistema operacional em tempo real, escreve a SiliconANGLE. O núcleo Intelligence IP de 32 bits do X160 foi projetado para otimizar a eficiência energética e aplicações com restrições de área de chip apertadas, enquanto o núcleo Intelligence IP de 64 bits do X180 fornece maior desempenho e melhor integração com subsistemas de memória maiores, informou a CNX-Software.

O X160 vem com até 200 KiB de cache e 2 MiB de memória. Além de equipamentos industriais, o núcleo pode ser aplicado em dispositivos de consumo, como rastreadores de fitness. Além disso, o X160 pode ser instalado em sistemas com múltiplos aceleradores de IA para gerenciar chips e evitar alterações de firmware. Com dois caches integrados com capacidade total de mais de 4 MiB, o núcleo permite trabalhar com grandes quantidades de dados. De acordo com a SiFive, o X160 é adequado para treinamento de modelos de IA e uso em equipamentos de data center.
Por sua vez, o núcleo X280 é voltado para dispositivos de consumo, como headsets de realidade aumentada, e o X390 também pode ser usado em carros e sistemas de infraestrutura. Este último núcleo realiza processamento vetorial quatro vezes mais rápido que o X280.
Todos os cinco produtos Intelligence Gen 2 já estão disponíveis para licenciamento, e os primeiros chips baseados neles devem chegar ao mercado no segundo trimestre de 2026. A SiFive anunciou que duas empresas líderes em semicondutores dos EUA licenciaram a nova série X100 antes de seu anúncio público. Elas estão usando a propriedade intelectual X100 em dois cenários diferentes: uma empresa está usando o núcleo vetorial escalar da SiFive com um mecanismo de matriz atuando como uma unidade de controle do acelerador, e a outra está usando o mecanismo vetorial como um acelerador de IA autônomo.