
Se há algum propósito na vida em geral, e na vida racional em particular, não é tanto uma questão filosófica, mas, talvez, religiosa. Ao mesmo tempo, qualquer criatura viva, em um nível tático, por assim dizer, estabelece continuamente para si mesma – embora nem sempre de forma totalmente consciente – certos objetivos: entrar nesta universidade específica, capturar este antílope específico, prender esta anêmona-do-mar específica à sua concha. Sim, formalmente, o estabelecimento de metas táticas pode parecer trivial: quando uma universidade é escolhida mais perto de casa, um antílope é o mais fraco (depois que a perseguição já começou, tendo percebido qual deles está ficando para trás dos outros), e uma anêmona é a primeira que aparece. Mas o caminho para o pico aparentemente mais inexpugnável e distante é, na verdade, uma cadeia de conquistas de objetivos táticos interconectados, então ensinar inteligência artificial, se não uma ação simples “consciente”, pelo menos uma ação simples “taticamente justificada” significa, em certo sentido, dar um passo em direção à notória “IA forte”. O que, esperamos, irá, precisamente no entendimento humano desta palavra, definir tarefas para si mesmo de forma independente – e então encontrar maneiras de resolvê-las. Não é fato que isso não acabará assombrando a humanidade (há tanta ficção científica escrita sobre esse tópico que é impossível contar), mas, por enquanto, uma IA forte continua sendo uma meta ilusória.
Pesquisadores que estudam o comportamento humano há muito estabeleceram na prática que atividades com um objetivo claro — mesmo algo tão banal quanto caminhar até um ponto de referência claramente visível — são muito mais eficazes do que simplesmente caminhar na direção indicada. Mais eficiente em um sentido puramente físico: os participantes do experimento que se concentraram em atingir o ponto de passagem indicado, sem perdê-lo de vista por um minuto, se moveram em média mais rápido e estavam menos cansados do que os representantes do grupo de controle, que foram simplesmente instruídos a “ir até serem parados”. Como um ser biológico, nem sempre faz sentido para um modelo generativo estabelecer metas “conscientes” para si mesmo – assim como, por exemplo, um adulto que leva uma colher à boca durante uma refeição não faz isso (mas uma criança que está aprendendo a comer de forma independente, pelo contrário, define metas ativamente durante cada ação desse tipo). Mas a IA orientada a objetivos tem sua própria área de aplicação importante – e tais sistemas têm sido desenvolvidos especialmente ativamente nos últimos anos.

Um dos objetivos instintivos do caranguejo eremita, essencial para sua existência, é encontrar um abrigo adequado. Se não houver uma concha livre de algum molusco azarado sob a garra, os caranguejos eremitas modernos precisam improvisar. Mas se um modelo de IA se comportasse de maneira semelhante, seus operadores não pensariam que ele estava alucinando ou até mesmo trapaceando? (Fonte: Wikimedia Commons)
⇡#Um sétimo
Especialistas do American Project Management Institute (PMI) identificam apenas sete modelos de aplicação de IA, aos quais — ou melhor, a várias combinações dos quais — centenas de milhares, se não milhões, de implementações práticas dessa tecnologia inovadora são reduzidas. Estamos falando de:
- Hiperpersonalização (quando, digamos, literalmente para cada cliente, dependendo de seu perfil pessoal – pode ser um histórico de compras, um registro médico, uma crônica de participação em negociações na bolsa de valores, etc. – um sistema inteligente formula uma oferta ideal especificamente para ele),
- Análise preditiva e comprovação de decisões de gestão (aqui, com base na análise de longas séries de eventos anteriores, os sistemas de aprendizagem de máquina fazem previsões fundamentadas sobre o desenvolvimento futuro da situação),
- Identificar padrões e anomalias (semelhante ao modelo anterior, mas em vez de séries temporais, são dados díspares sobre um determinado tópico que são estudados, dos quais são extraídos padrões, relações de causa e efeito e possivelmente suas violações estatisticamente significativas que não foram descobertas pelas pessoas – e estes, por sua vez, podem indicar a incompletude do conjunto de dados ou indicar a presença de algum fator não contabilizado),
- Interagir com pessoas usando linguagens naturais (olá, chatbots!),
- Reconhecimento (de rostos em vídeo, fala coerente em um fluxo de áudio, letras e palavras em uma receita escrita à mão, etc.),
- Sistemas autônomos (significando não apenas caminhões autônomos ou, digamos, empilhadeiras de armazém, mas também robôs de software que realizam uma certa gama de tarefas de forma independente),
- E, finalmente, sobre a IA orientada a objetivos, ou proposital (goal-driven AI – CII), que é definida como um determinado agente de software capaz de encontrar a maneira ideal de resolver uma tarefa definida diante dele por tentativa e erro: aqui a diferença fundamental do modelo anterior está justamente na permissibilidade de erros – afinal, ninguém observará com carinho um carro autônomo, repetidamente dirigindo até um cruzamento no vermelho, para receber uma observação do operador: “Errado, vamos tentar de novo”.
Um ponto importante: o CII não pode, em princípio, ser uma rede neural com pesos fixos que é treinada uma vez e depois aplicada somente (no modo de inferência, com custos de recursos muito menores): ela é sempre dinâmica e pronta para treinamento adicional contínuo. AlphaZero, um sistema de aprendizado de máquina criado pelo Google DeemMind para superar jogadores humanos no xadrez clássico, shogi (uma variante japonesa do xadrez) e Go, é um exemplo bem-sucedido de um agente orientado a objetivos que alcançou sucesso indiscutível muito antes da era da IA generativa generalizada. Esse agente é fundamentalmente diferente de abordagens anteriores ao “projétil” do xadrez, como o outrora famoso desenvolvimento da IBM chamado Deep Blue: ele se baseava em um vasto banco de dados que incluía essencialmente todos os movimentos possíveis de peças no tabuleiro para um grande número de posições iniciais e, em meio a esse mar ilimitado de movimentos potenciais, usando métodos heurísticos — baseados na experiência de grandes mestres biológicos — ele buscava encontrar o melhor a cada vez.
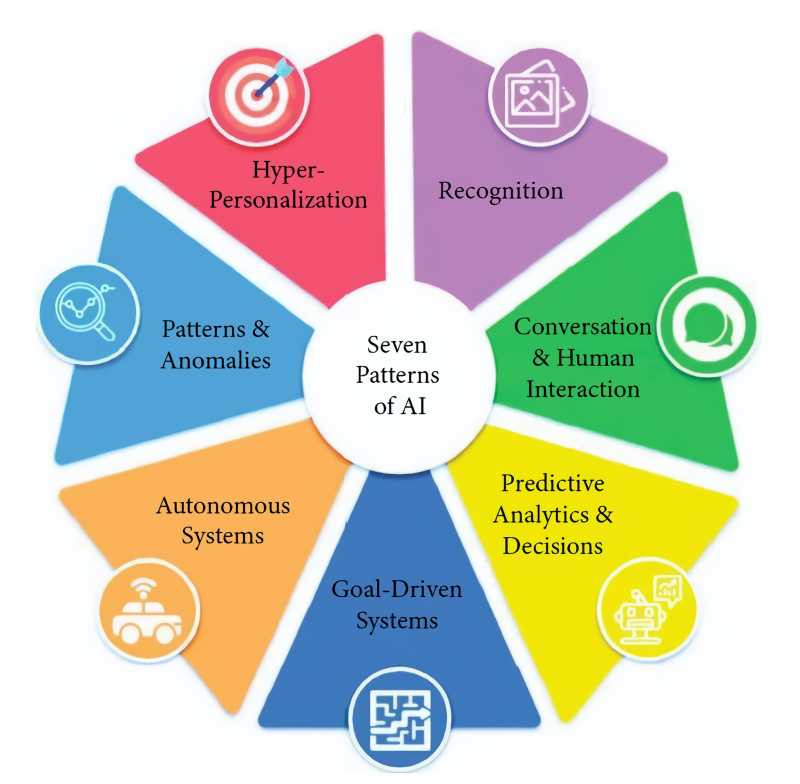
Os sistemas de IA implementados na prática não pertencem necessariamente exclusivamente a um dos modelos listados, mas muitas vezes combinam dois ou mais deles, assim como os temperamentos humanos raramente se manifestam estritamente em uma das quatro variantes clássicas de colérico, fleumático, melancólico ou sanguíneo (fonte: PMI)
O AlphaZero opera com um princípio diferente: é uma rede neural profunda, inicialmente treinada não em algumas técnicas complexas de grandes mestres, mas nas regras mais básicas para fazer movimentos. Após completar esse treinamento, o AlphaZero simplesmente começou a jogar (inicialmente no xadrez clássico) contra si mesmo, alternadamente escolhendo os lados preto e branco no mesmo tabuleiro; tentando honestamente vencer – essencialmente, contra si mesma, e sem se desviar das regras estabelecidas – e assim por diante, vários milhões de vezes. Esse processo é amplamente conhecido como aprendizado por reforço.
O importante aqui é que o aprendizado por reforço é conduzido de forma diferente de outros tipos populares de aprendizado de máquina – com e sem um professor (aprendizado supervisionado e aprendizado não supervisionado, respectivamente). A chave para o sucesso do aprendizado supervisionado é uma grande variedade de dados bem anotados — geralmente por humanos — que o sistema verifica regularmente durante seu treinamento. O aprendizado não supervisionado, por sua vez, envolve trabalhar com informações não rotuladas para descobrir de forma independente padrões e relacionamentos ocultos. O aprendizado por reforço é realizado, em essência, da mesma forma que as redes neurais biológicas aprendem na natureza: por tentativa e erro, usando recompensas e penalidades para cada decisão tomada. Existe, é claro, o risco aqui de que o sistema, em vez de procurar maneiras não convencionais de vencer de forma justa, comece a trapacear, distorcendo as regras a seu favor ou encontrando uma maneira de contorná-las – modelos atuais treinados por reforço, como OpenAI o1-preview e DeepSeek R1, já foram notados por isso. Por outro lado, não há alguns trapaceiros entre os portadores de inteligência biológica?
No início, AlphaZero movia peças pelo tabuleiro quase que caoticamente (observando todas as regras básicas, é claro). Mas muito rapidamente – graças à implementação bem-sucedida dessa mesma função de recompensa, que teve de ser definida e estabelecida com antecedência – ela parou de permitir “bocejos”, “palavrões infantis” e outros erros banais. Os pesos nas entradas dos seus perceptrons, alterados pela função de recompensa, contribuíram para um aumento na probabilidade de fazer movimentos menos triviais — se estivéssemos a falar de uma pessoa, seria apropriado dizer “mais ponderados”; aquelas que, em uma determinada posição específica, teriam mais probabilidade de ser vantajosas para aquele jogador em particular (para as pretas ou para as brancas) a longo prazo. O computador que treinou o AlphaZero com reforço era bastante poderoso, e o número de movimentos possíveis em cada posição é limitado de qualquer maneira, então não é de se surpreender que, a partir de algum momento, CII começou a jogar melhor do que quase qualquer grande mestre – sem ter a menor ideia sobre aberturas, finais de jogo e outros fundamentos teóricos do jogo. Curiosamente, a propósito, treinar essa rede neural a um nível aceitável, na opinião dos desenvolvedores, levou cerca de 9 horas para xadrez, 12 horas para shogi e 13 dias para go (onde o tabuleiro, para ser justo, é muito maior).
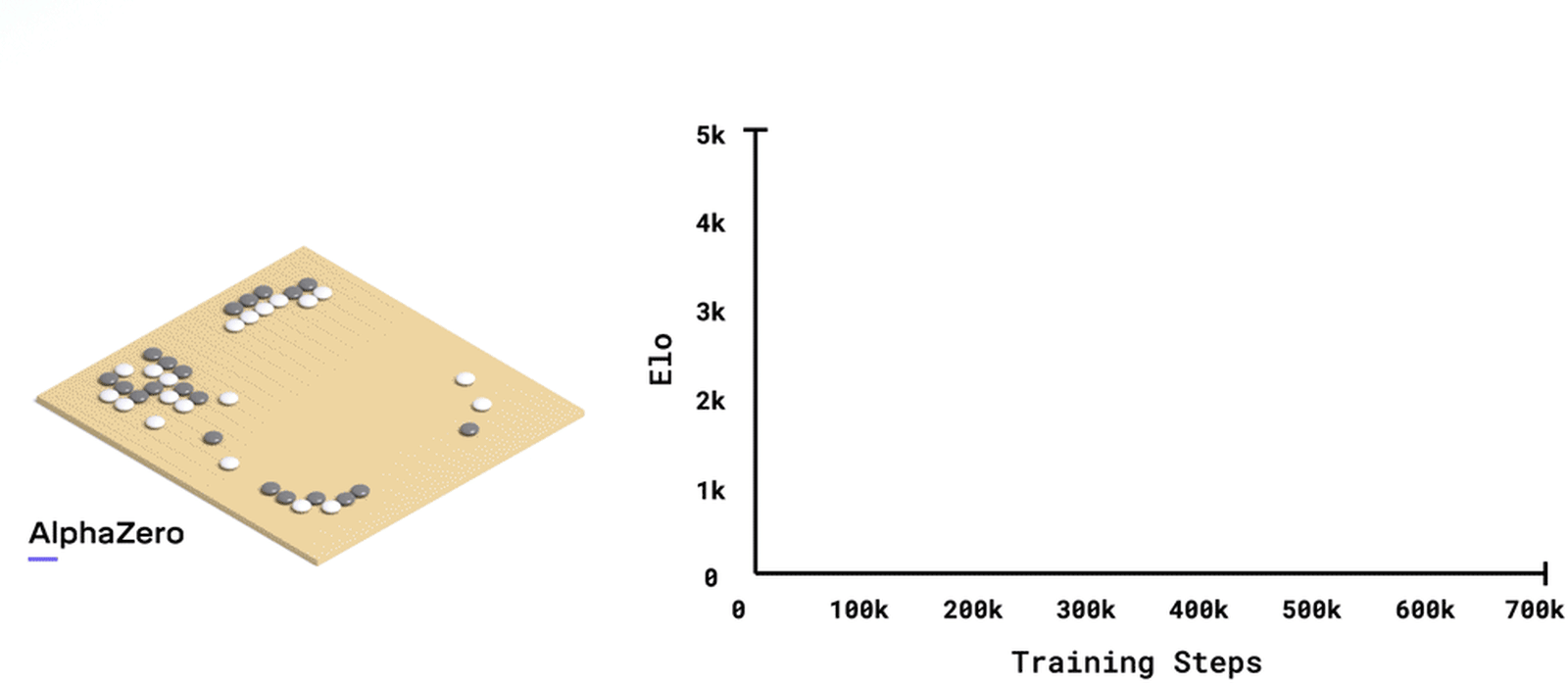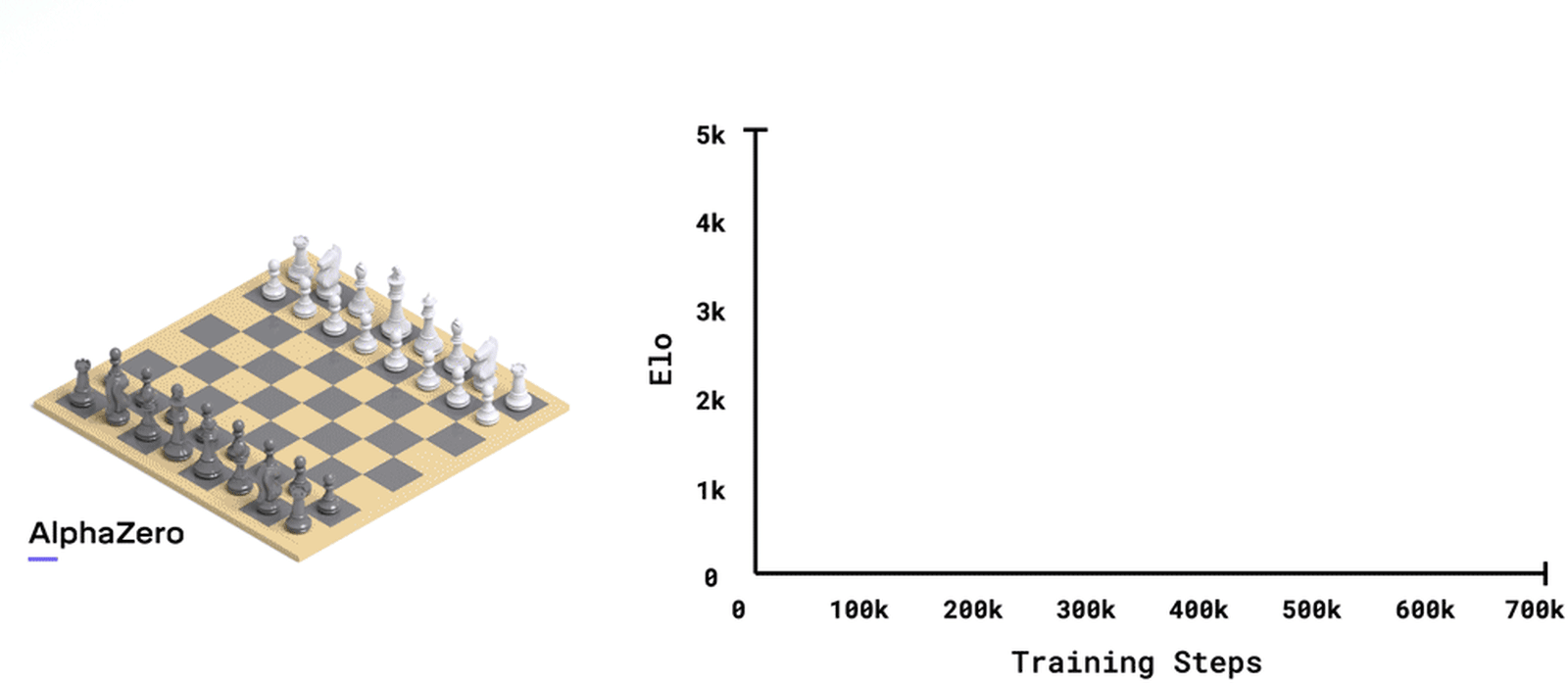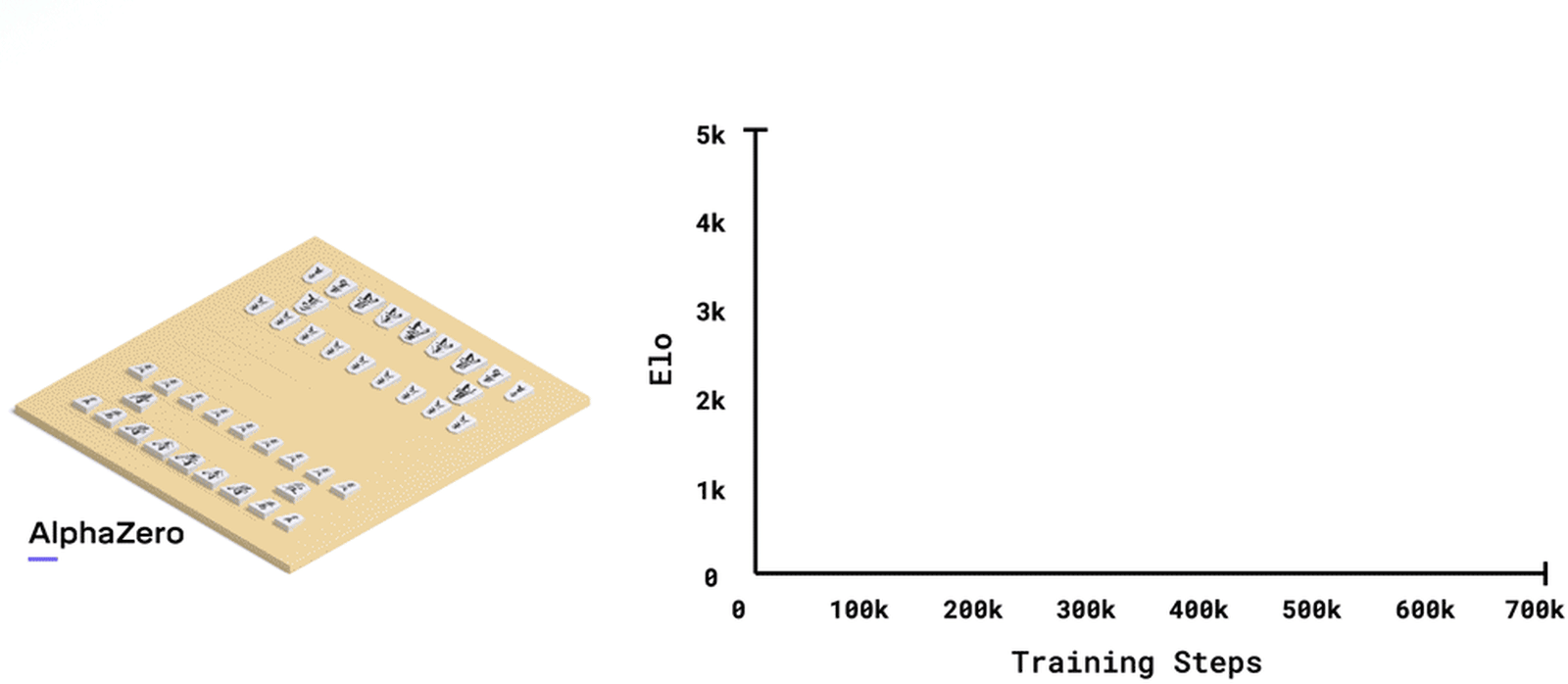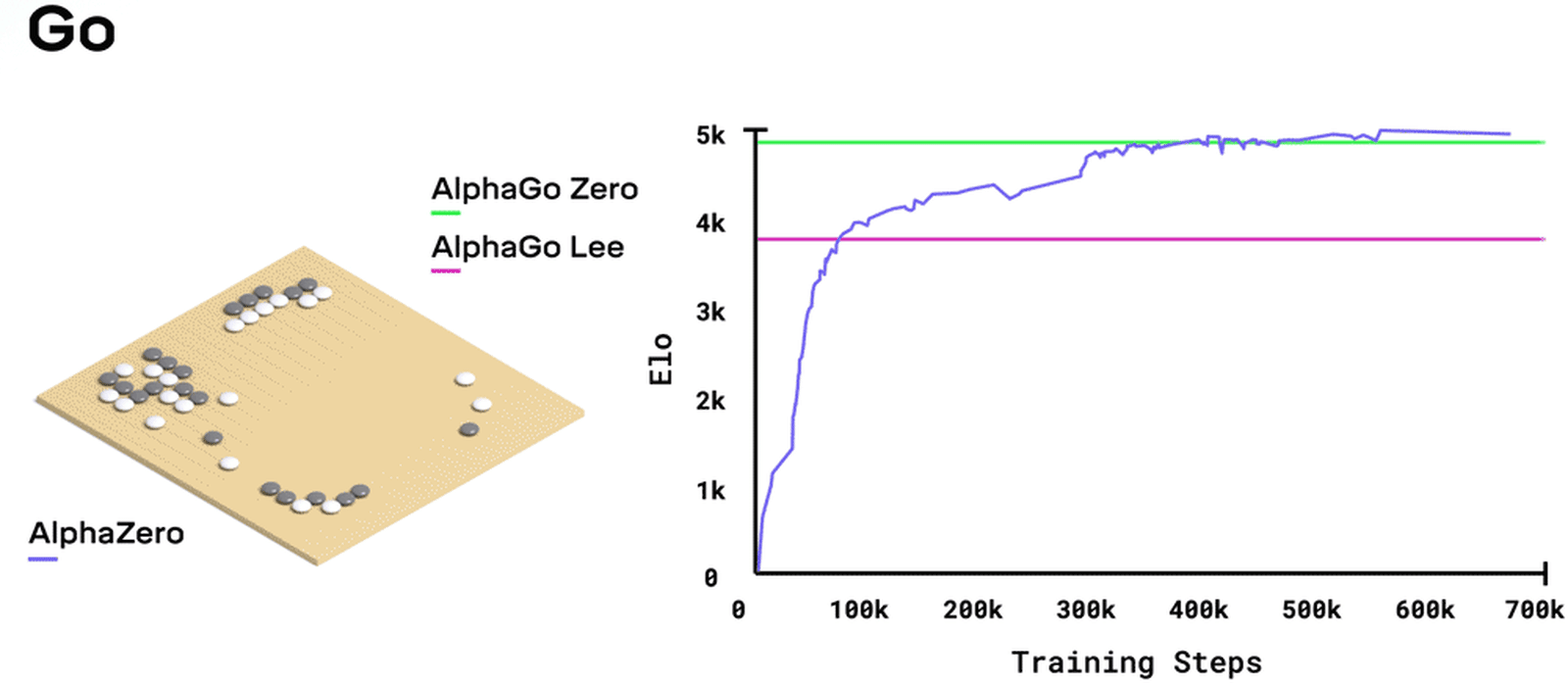
Uma ilustração visual de como o AlphaZero gradualmente igualou ou superou o desempenho dos sistemas de aprendizado de máquina específicos do jogo por meio do aprendizado por reforço (fonte: DeepMind)
A equipe do DeepMind cita Yoshiharu Habu, um 9º dan e o único jogador de shogi na história a ter conquistado todos os sete principais títulos de shogi, dizendo com admiração: “Alguns dos movimentos do AlphaZero, como mover o rei (王将, oosho) para o centro do tabuleiro, são contraintuitivos e, para um humano, colocam o jogador do computador em uma posição perigosa. Mas, ao mesmo tempo, curiosamente, ele mantém o controle sobre o tabuleiro, e um estilo tão único abre novas oportunidades para jogadores reais.” Ao mesmo tempo, enquanto máquinas especializadas em resolver problemas de xadrez (o mesmo Deep Blue) realizam dezenas de milhões de movimentos possíveis de peças a cada passo em busca do melhor movimento, o AlphaZero está limitado a apenas dezenas de milhares. Sim, a mente humana é ainda mais perfeita – um grande mestre, confiando nas conquistas da teoria e em sua própria experiência, cristalizadas em heurísticas, repassa em sua cabeça “apenas” centenas de movimentos possíveis. Mas os grandes mestres às vezes perdem para o CII, enquanto este último, não limitado por coleções memorizadas de aberturas (exatamente porque ele não memorizou nenhuma coleção), traz novas ideias e movimentos não triviais para o jogo, muitas vezes confundindo jogadores biológicos.
⇡#De acordo com o mérito
Retirados diretamente da psicologia comportamental, termos como “reforço”, “recompensa” e “penalidade” podem ser enganosos para um não especialista: afinal, um agente de IA orientado a objetivos de software nem mesmo é um robô; Você não pode recompensá-lo com uma lata de WD-40 ou dar-lhe um choque elétrico por seu erro. Tanto os incentivos quanto as penalidades para o CII são simplesmente representados por números — positivos e negativos, respectivamente. É esse reforço numérico, que expressa uma avaliação das ações do sistema em uma determinada situação, que substitui, por exemplo, o modelo de “respostas verdadeiras” com o qual o aluno e o professor da IA generativa verificam. Criar uma tabela de reforço eficaz para um determinado modelo é uma verdadeira arte, pois pode haver muitas delas, dependendo da tarefa definida pelo operador. Por exemplo:
- Recompensa fixa simples – pela conclusão bem-sucedida de um determinado procedimento de rotina (por exemplo, um personagem liderado pelo CII em um jogo de computador saltou com sucesso de uma plataforma móvel para outra – +1 ponto),
- Uma penalidade fixa simples – por falhar em uma tarefa de rotina semelhante (um robô operando em um ambiente virtual simulado deixou cair uma caixa que havia tirado de uma prateleira – -5 pontos),
- Grande (por módulo), mas raramente emitia reforços (CII encontrou uma saída de um labirinto particularmente difícil – +100; perdeu a pista de pouso e caiu o avião no simulador – -500),
- Reforço baseado no tempo (outro labirinto simples concluído 1 ms mais rápido que o recorde — +1; um pacote entregue no destino final de uma rede complexa ao resolver o “problema do caixeiro viajante” 1 minuto mais lento que antes — -1),
- Recompensa cumulativa, que é, em última análise, maior quanto mais tempo o sistema executa sua tarefa corretamente (um robô subindo uma escada ganha +1 ponto para cada degrau que sobe sem perder o equilíbrio e, se tropeçar, o prêmio é zerado – então o CII que o controla se esforçará para maximizar a recompensa cumulativa, em vez de se concentrar em melhorar cada degrau),
- Recompensas que são internas ao ambiente de aprendizagem (um modelo que coleta determinados objetos no jogo ganha +0,05 pontos para cada um – isso ajuda, por um lado, a estimular o acúmulo de recursos e, por outro – a não tornar essa tarefa secundária uma prioridade em relação à principal, neste caso, passar pelo labirinto no qual esses objetos estão espalhados),
- Recompensas externas em relação ao mesmo ambiente (na maioria das vezes concedidas pelo operador que observa o aprendizado por reforço – podem ser comparadas com pontos “por arte” na patinação artística: o robô simplesmente moveu um objeto de um lugar para outro – sem reforço externo; fez isso de uma forma particularmente graciosa, do ponto de vista humano – imediatamente +50 pontos),
- Reforços específicos (dependem inteiramente da tarefa definida antes do CII e podem ser bastante diversos no grau de impacto no sistema; por exemplo, se durante o processo de treinamento em realidade virtual o robô acidentalmente descobre um bug de software que lhe permite encontrar-se imediatamente na saída do labirinto, então seria lógico que um sistema projetado para resolver problemas lógicos concedesse uma grande multa por isso, mas para um sistema destinado a encontrar falhas no código do jogo, pelo contrário, uma recompensa igualmente significativa).
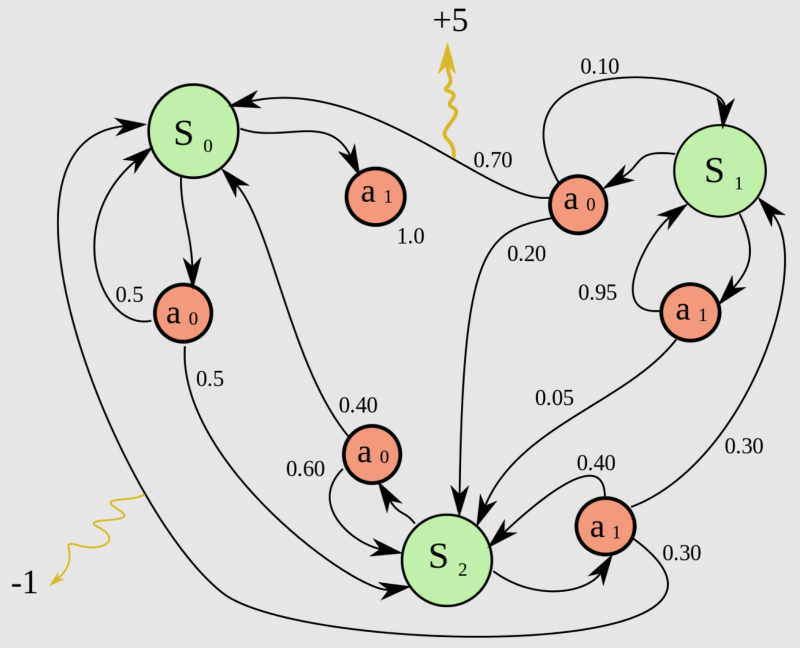
Um exemplo de um processo de decisão de Markov com três estados e duas ações possíveis em cada um, onde o sistema recebe recompensas com base nos resultados de ações individuais: neste caso, -1 ponto para uma e +5 para a outra (fonte: Wikimedia Commons)
Como pode ser visto nos exemplos dados, o ambiente no qual o aprendizado por reforço ocorre é tão importante em termos de desenvolvimento da estratégia correta para a ação do sistema quanto a própria IA de definição de metas. É por isso que as IAs são mais frequentemente classificadas como agentes em vez de modelos generativos universais, já que quando as condições para conceder recompensas e incentivos mudam, o próprio modo de ação da inteligência artificial pode mudar significativamente. O AlphaZero discutido anteriormente conseguiu jogar três jogos diferentes com igual sucesso, precisamente porque os tabuleiros e as regras para todos os três são significativamente diferentes: não é fato que seria possível treinar um modelo demonstrando resultados igualmente altos para jogar damas clássicas e, digamos, dar de presente. Também é importante escolher a proporção certa entre os diferentes tipos de recompensas: se o robô não chegar a um beco sem saída após outra volta no labirinto, ele merece uma pequena recompensa, enquanto uma saída bem-sucedida do labirinto merece uma grande.
Por mais surpreendente que pareça, esse conjunto geralmente simples de regras para recompensa e punição na verdade permite que o CII forme estratégias bem-sucedidas para resolver certos problemas em certos ambientes – assim como reações básicas a estímulos externos ajudam os organismos mais simples, que não têm células nervosas, a sobreviver, se reproduzir e evoluir. Ao mesmo tempo, como o modelo mantém a capacidade de alterar pesos o tempo todo enquanto está em operação e não usa uma configuração desses mesmos pesos para inferência que é memorizada de uma vez por todas durante o processo de treinamento, os CIIs são capazes, ao contrário de vários outros sistemas de aprendizado de máquina, de resolver o “dilema exploração-exploração”. Sua essência é que, tendo descoberto uma certa maneira bem-sucedida de resolver um problema, um agente inteligente – não necessariamente um computador, a propósito, isso também acontece com as pessoas o tempo todo – se esforça para parar de procurar o bem no bem e começa a usar (explorar) esse mesmo método repetidamente. Embora o ambiente ao seu redor possa mudar dinamicamente, e suas próprias habilidades, necessidades e recursos possam evoluir de alguma forma, não importa; “se não está quebrado, não conserte.” E quando algo importante acontece de repente, geralmente é tarde demais.
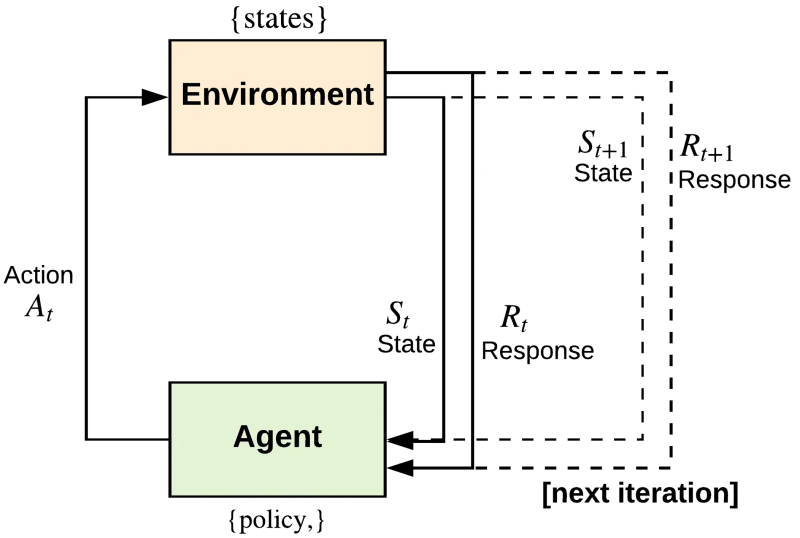
Uma estrutura geral para ajustar a política de um agente de IA orientado a objetivos que opera no paradigma de reconhecimento de uso (fonte: Medium)
Portanto, não é tão difícil “programar” o CII de uma certa maneira para uma pesquisa regular, embora limitada em profundidade, de seu ambiente, que parece já ter sido estudado anteriormente, no curso do autotreinamento, ou melhor, definir-lhe, entre outras metas, a tarefa de conduzir esse tipo de pesquisa (exploração) de tempos em tempos. Para sair da zona de conforto, na linguagem dos psicólogos, é preciso considerar novas possibilidades (que, a propósito, podem não aparecer – é por isso que a tarefa de reconhecimento não deve ter a maior prioridade, ou seja, reforço máximo; a menos, é claro, que estejamos falando de um agente de pesquisa especializado), testá-las e, se forem adequadas, reconstruir o padrão de ações desenvolvido para atingir um novo ótimo.
Aliás, um ambiente bem escolhido para o trabalho do agente CII pode, por si só, criar os pré-requisitos para o equilíbrio correto entre uso e reconhecimento. Não foi à toa que os desenvolvedores do AlphaZero o forçaram a jogar contra si mesmo: se seu oponente fosse uma pessoa específica ou um sistema especializado como o DeepBlue, não construído no princípio de uma rede neural generativa, o máximo que ele teria alcançado seria o nível de seu oponente. Não haveria razão para ele sair da sua zona de conforto, na qual ele já vence, digamos, mais da metade dos jogos. Em oposição a si mesmo, o agente CII com a mentalidade de vitória (em essência, ao que parece, de vitória sobre si mesmo; os nietzschianos aplaudem silenciosamente) cresceu e se desenvolveu continuamente a cada jogo, finalmente ultrapassando os limites de sua zona de conforto para os limites fisicamente alcançáveis estabelecidos por sua própria base de hardware.
Uma abordagem particularmente bem-sucedida para o aprendizado por reforço provou ser o método Q-learning sem modelo, proposto por Chris Watkins em 1989. Sua natureza “sem modelo” reside precisamente na ausência inicial das “ideias” do sistema sobre a estrutura do ambiente em que ele opera – há apenas um conjunto de regras necessárias para ações neste ambiente. Uma pessoa, olhando para o desenho de um labirinto, vê a imagem inteira de uma vez e imediatamente descarta muitas opções obviamente inadequadas para passar por ele, enquanto um robô, colocado no ponto inicial do caminho, não tem ideia de onde fica a saída. O CII que o controla simplesmente tem instruções (uma tabela contendo uma lista de todos os reforços possíveis para todas as ações possíveis), que dizem que um passo em qualquer direção disponível é executado sem penalidade, que bater em uma parede significa perder um ponto e que chegar a uma área aberta em todos os quatro lados (a saída em si) é recompensado com uma grande recompensa. Isso por si só é suficiente para que o agente comece a aprender o curso de ação ideal simplesmente recebendo feedback do seu ambiente – isso é o que chamamos de programação dinâmica assíncrona. Assim, o Q-learning é um aprendizado por reforço que encontra uma política de ação ótima para qualquer processo de decisão de Markov finito.
Como resultado, um sistema de IA que aprende com reforço é focado em maximizar a recompensa total que pode, em princípio, ser obtida durante a execução de uma tarefa específica, levando em consideração sutilezas como penalidades por lentidão excessiva, a proporção dos tamanhos de recompensas pela ausência de erros óbvios (poucos pontos) e uma vitória esmagadora (muitos de uma vez), etc. O resultado do (auto)treinamento de tal agente de IA pode parecer para um observador externo quase uma evidência da inteligência genuína do modelo de computação operando na RAM de um grande computador – da mesma forma que os primeiros naturalistas se recusaram a reconhecer os instintos complexos dos animais (a auto-organização de uma colmeia, a migração anual de pássaros, etc.) como consequência da adaptação gradual ao ambiente natural, e não da intervenção direta de um Criador onisciente. Mas não, os agentes orientados a objetivos de hoje ainda estão muito longe de uma IA forte – aproximadamente o mesmo que organismos unicelulares que se auto-organizam em colônias estão longe de organismos multicelulares qualitativamente mais complexos. No entanto, a evolução biológica deu esse salto, o que significa que há uma chance para sistemas de inteligência artificial, ainda que em um futuro distante (por enquanto?).
Materiais relacionados
- Pesquisadores da DeepMind propuseram treinamento distribuído de grandes modelos de IA que podem mudar toda a indústria.
- A CoreWeave fornecerá o supercomputador de IA baseado em NVIDIA GB200 NVL72 da IBM para treinar modelos Granite.
- Cientistas do MIT se basearam em grandes modelos de linguagem de IA para criar um método eficaz de ensino de robôs.
- O Prêmio Nobel de Física foi concedido aos pais das redes neurais e do aprendizado de máquina.
- CoreWeave e Run:ai ajudarão os clientes a treinar IA.