
Meta✴ relatou os resultados das pesquisas mais recentes no campo da inteligência artificial no âmbito dos projetos FAIR (Fundamental AI Research). Os especialistas da empresa desenvolveram um modelo de IA responsável pelos movimentos verossímeis de personagens virtuais; um modelo que opera não com tokens – unidades de linguagem – mas com conceitos; e muito mais.

Fonte da imagem: Google DeepMind/unsplash.com
O modelo Meta✴ Motivo controla os movimentos de personagens humanóides virtuais ao realizar tarefas complexas. Foi treinado com reforço em uma matriz não rotulada com dados sobre os movimentos do corpo humano – este sistema pode ser utilizado como sistema auxiliar na concepção dos movimentos e posições corporais dos personagens. “O Meta Motivo é capaz de realizar uma ampla gama de tarefas de controle de corpo inteiro, incluindo rastreamento de movimento e postura do alvo, sem qualquer treinamento ou planejamento adicional”, afirmou a empresa.
Uma conquista importante foi a criação de um grande modelo conceitual (Large Concept Model ou LCM) – uma alternativa aos grandes modelos tradicionais de linguagem. Os pesquisadores da Meta✴ notaram que os sistemas avançados de IA atuais operam no nível de tokens – unidades de linguagem que normalmente representam um fragmento de uma palavra – mas não demonstram raciocínio hierárquico explícito. No LCM, o mecanismo de raciocínio é separado da representação linguística – de forma semelhante, uma pessoa primeiro forma uma sequência de conceitos e depois a coloca em forma verbal. Assim, ao realizar uma série de apresentações sobre um tema, o palestrante já possui uma série de conceitos formada, mas a redação do discurso pode mudar de um evento para outro.
Ao gerar uma resposta a uma consulta, o LCM prevê uma sequência não de tokens, mas de conceitos representados em frases completas num espaço multimodal e multilingue. À medida que o contexto na entrada aumenta, a arquitetura LCM, segundo os desenvolvedores, parece ser mais eficiente no nível computacional. Na prática, este trabalho ajudará a melhorar o desempenho de modelos de linguagem com qualquer modalidade, ou seja, formato de dados, ou na saída de respostas em qualquer idioma.
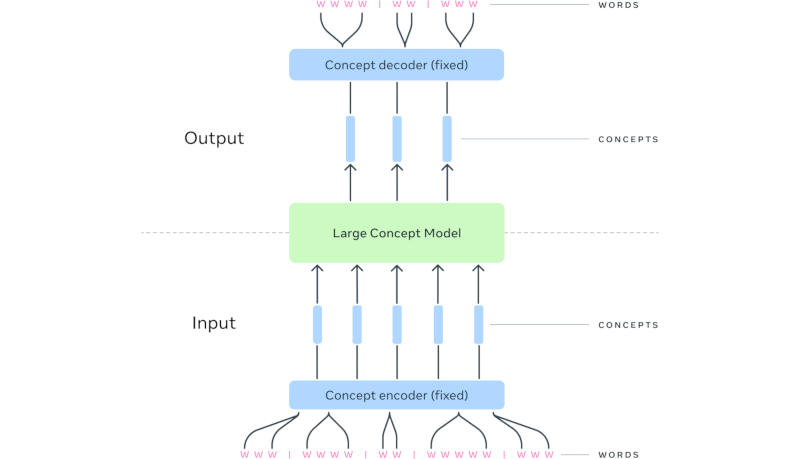
Fonte da imagem: Meta✴
O mecanismo Meta✴ Dynamic Byte Latent Transformer também oferece uma alternativa aos tokens de linguagem, mas não expandindo-os em conceitos, mas, pelo contrário, formando um modelo hierárquico no nível do byte. Isso, segundo os desenvolvedores, aumenta a eficiência ao trabalhar com longas sequências no treinamento e execução de modelos. A ferramenta complementar Meta✴ Explore Theory-of-Mind foi projetada para incutir habilidades de inteligência social em modelos de IA à medida que são treinados, para avaliar o desempenho dos modelos nessas tarefas e para ajustar sistemas de IA já treinados. Meta✴ Explore a Teoria da Mente não se limita a uma determinada gama de interações, mas gera seus próprios cenários.
A tecnologia Meta✴ Memory Layers at Scale visa otimizar os mecanismos reais de memória de grandes modelos de linguagem. À medida que aumenta o número de parâmetros nos modelos, trabalhar com memória real requer cada vez mais recursos, e o novo mecanismo visa salvá-los. O projeto Meta✴ Image Diversity Modeling, que está sendo implementado com o envolvimento de especialistas terceirizados, visa aumentar a prioridade das imagens geradas por IA que correspondem com mais precisão aos objetos do mundo real; também ajuda a tornar os desenvolvedores mais seguros e responsáveis ao criar imagens usando IA.
O modelo Meta✴ CLIP 1.2 é uma nova versão do sistema projetado para estabelecer uma conexão entre texto e dados visuais. Também é usado para treinar outros modelos de IA. A ferramenta Meta✴ Video Seal foi projetada para criar marcas d’água em vídeos gerados por IA – essa marcação é invisível ao visualizar o vídeo a olho nu, mas pode ser detectada para determinar a origem do vídeo. A marca d’água é preservada por meio de edição, incluindo desfoque e codificação usando vários algoritmos de compactação. Por fim, Meta✴ lembrou o paradigma Flow Matching, que pode ser usado para gerar imagens, vídeo, som e até estruturas tridimensionais, incluindo moléculas de proteínas – esta solução ajuda a usar informações sobre o movimento entre diferentes partes da imagem e atua como uma alternativa ao mecanismo de difusão.