
Em nossos materiais anteriores sobre hardware de computadores neuromórficos, discutimos brevemente os princípios gerais de sua operação e uma das implementações de semicondutores mais bem-sucedidas desse tipo de sistema – os chips Intel Loihi e Loihi 2. Ao mesmo tempo, enfatizamos repetidamente que embora o hardware. os neuromórficos teoricamente parecem ser uma direção incrivelmente promissora no desenvolvimento da IA, especialmente do ponto de vista da eficiência energética dos cálculos realizados, na prática ela é restringida por uma série de obstáculos sérios – cuja superação exigirá que os desenvolvedores parece exigir mais esforço e tempo do que inicialmente imaginado pelos entusiastas desta tendência. Ao mesmo tempo, as redes neurais hoje familiares, inteiramente implementadas em software – na RAM dos computadores clássicos de von Neumann – também não param. E, embora sejam muito caros para treinar e operar (se levarmos em conta o consumo astronômico de energia dos servidores de IA com adaptadores gráficos Nvidia, em primeiro lugar), os resultados são bastante tangíveis e atraentes. Os computadores neuromórficos continuam a ser, em grande parte, protótipos experimentais, e não burros de carga para clientes em vários setores da economia que precisam de resolver problemas de IA – e os seus criadores precisam claramente de fazer algo sobre isto.
⇡#Para memória (longa? boa?)
«Redes neurais comuns, chamadas simplesmente de redes neurais artificiais (RNA) em inglês, podem ser classificadas mais estritamente como redes neurais feed-forward (FFNN). O sinal de informação neles se move apenas em uma direção, da camada de entrada dos perceptrons, passando pelos ocultos, até a camada de saída, sem formar loops e/ou fluxos de retorno – e isso, como mostra a prática, é suficiente para resolver uma enorme classe de problemas discriminativos, como discriminação de imagens de cães e gatos, ou letras e números manuscritos, ou reconhecimento facial, etc.
O sinal que passa pelas camadas neurais não deixa rastro de informação; Para ajustar os pesos nas entradas dos perceptrons (o que é necessário durante o treinamento, quando o resultado produzido pelo FFNN não corresponde a um determinado padrão durante o aprendizado supervisionado, por exemplo), mecanismos especiais devem ser fornecidos. Para redes neurais emuladas inteiramente na memória do computador, não há problema nisso: cada peso é um número, e alterar o valor da variável desejada na tabela é trivial. Mas do ponto de vista dos neuromórficos de hardware, organizar um acesso rápido e confiável a centenas e milhares (ou melhor ainda, milhões e bilhões) de reostatos condicionais, que definiriam pesos nas entradas dos perceptrons físicos associados a eles, é um procedimento profundamente incomum. tarefa, e a dificuldade de sua implementação é justamente um dos fatores mais fortes que dificultam o desenvolvimento de computadores com redes neurais de hardware verdadeiramente grandes.
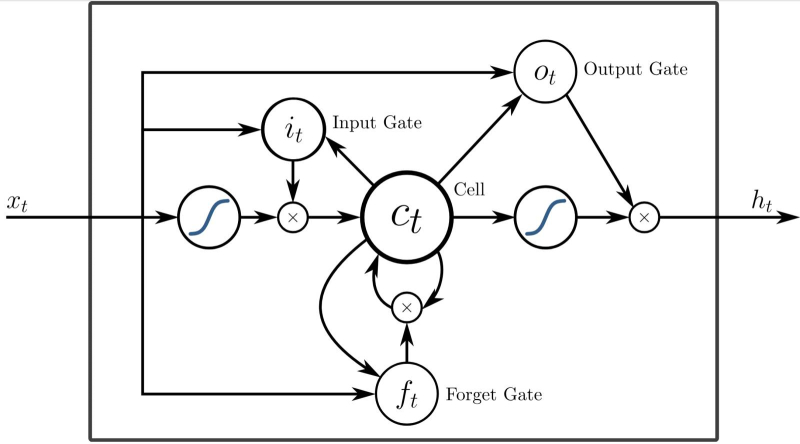
Uma das possíveis implementações de uma célula RNN com uma porta especial que ativa o “esquecimento” (apagamento) de informações previamente armazenadas na memória local (fonte: Wikimedia Commons)
Com redes neurais recorrentes (RNN), cujo subtipo é a rede neural de impulso (SNN) que discutimos anteriormente, as coisas são ainda mais interessantes. Na RNN, os neurônios trocam informações entre si, e não apenas as transmitem estritamente adiante, de camada para camada em particular, eles têm a capacidade de verificar dados sobre seus estados anteriores no processo de mudança do atual sob a influência do; próxima porção de informações recebidas por eles. Essencialmente, as RNNs são redes neurais com memória interna (um exemplo disso é o dispositivo de chips Loihi com células SDRAM ligadas a neurônios artificiais individuais) e, portanto, são mais adequadas para processar sequências de dados. Não uma imagem estática, cuja imagem precisa ser classificada (gato/cachorro), mas uma cadeia de eventos que se estende ao longo do tempo; digamos, uma sequência de notas em uma composição musical gerada, quando, com base nos conceitos de harmonia “aprendidos” pela rede neural e na estrutura de gênero especificada pelo operador, a sequência de sons já selecionada nos estágios anteriores é complementada com um novo, que certamente não é dissonante dos anteriores. Os especialistas comparam o FFNN com funções matemáticas simples: aqui está uma certa sequência de operações estritamente especificada (neste caso, por pesos nas entradas dos perceptrons), aqui estão os dados de entrada – e como resultado, em uma passagem, um certo bem- resposta definida é obtida, como se por uma fórmula. As RNNs, ao contrário, lembram mais computadores programáveis: a própria fórmula para obter uma resposta é definida pelas informações recebidas. A rigor, a presença de memória interna torna as redes neurais recorrentes de Turing completas, ou seja,capaz, com tempo suficiente, de resolver essencialmente qualquer problema computacional.
A propósito, isso não é um elogio: se houver, então, em particular, também é obviamente malicioso, o que imediatamente abre o mais amplo espaço para possíveis hackers em computadores RNN neuromórficos. O que não pode ser evitado, como dizem, intencionalmente – uma vez que a própria possibilidade potencial de hacking acaba sendo devida às propriedades inerentes à estrutura interna de tais sistemas. Na verdade, é a mesma história com a estrutura de rede neural natural mais avançada que conhecemos, o cérebro humano: não foram inventadas inúmeras maneiras de hackear esta máquina completa de Turing – desde propaganda e truques fraudulentos até a ativação química de certas conexões neurais induzidas. de fora do corpo. Portanto, se num futuro próximo computadores neuromórficos sofisticados tomarem o lugar dos atuais chatbots “inteligentes” emulados na memória dos servidores x86, será possível enganar suas cabeças – ou como serão chamados os contêineres de hardware RNN – com muito maior eficiência do que hoje implementar o jailbreak de grandes modelos de linguagem.

A célula LSTM contribui para o processamento sequencial dos dados que chegam ao neurônio artificial da rede de picos, mas ao mesmo tempo retém informações sobre seus valores anteriores até que seja recebida uma instrução explícita para “esquecê-los” (fonte: Wikimedia Commons)
A memória como parte de uma RNN pode ser organizada de uma forma bastante complexa – vale a pena mencionar a este respeito a “memória estendida de curto prazo” LSTM, memória longa de curto prazo, capaz de armazenar informações não apenas sobre o estado anterior do célula, mas também sobre (várias no caso geral) anteriores. Ao controlar portas de esquecimento especiais (forget gate), o sistema ganha a capacidade de trabalhar com séries muito longas de dados de entrada – impulsos de pico no caso do SNN. Apenas redes neurais com células LSTM (implementadas, é claro, exclusivamente em nível de software) até o boom da IA generativa eram utilizadas principalmente em sistemas de tradução automática, pois garantem bem a preservação não apenas do contexto da frase que está sendo traduzida no momento, mas também características sintáticas e até estilísticas de todo o texto como um todo (mais precisamente, o corpus de textos sobre os quais é realizado o treinamento). E ainda hoje, dada a tendência dos modelos generativos a alucinar, os RNNs com LSTM não vão sair de cena. Eles dependem em grande parte de ferramentas para geração automatizada de código de programa, divisão de texto em palavras significativas, preenchimento automático de vários formulários e muitas outras ferramentas “inteligentes” para as quais o poder dos FFNNs universais acaba sendo excessivo. Além disso, esse poder, como já foi mencionado mais de uma vez, não é obtido de graça (e principalmente no sentido energético), e as RNNs, mesmo na forma de emulação computacional na memória de máquinas x86, são ainda mais econômicas.
⇡#Puxe sua língua
Se os RNNs são tão bons em analisar a estrutura de sequências de dados quase arbitrários – cotações de ações, textos literários/técnicos, composições musicais, um gráfico de mudanças sazonais de temperatura e umidade em uma determinada localização geográfica, etc. populares hoje? Modelos generativos baseados em FFNN em vez daqueles baseados em redes neurais recorrentes? Em grande parte porque as RNNs, em sua forma original, não estão focadas em fornecer informações significativas: elas lidam de maneira brilhante com a identificação de padrões, mas não com a destilação de significados. Os FFNNs (especialmente os mais relevantes, com o uso ativo de convoluções e transformadores), embora tenham alucinações de vez em quando, graças ao seu design multicamadas, arrebatam certos significados do conjunto de dados de treinamento e é justamente por isso que distinguem um gato de um cachorro na foto com bastante confiança. Sim, o próprio sistema de aprendizado de máquina não está ciente desses significados – os contornos de reflexão e introspecção estão ausentes em uma rede neural multicamadas. Mas o modelo generativo sem dúvida captura as ideias abstratas de certas “catness” e “dogness” como características objetivamente compreensíveis como resultado da análise de dezenas de milhares de imagens – no nível de vetores associados aos tokens correspondentes em um espaço substancialmente multidimensional. , determinado, por sua vez, pelos pesos nas entradas de seus numerosos perceptrons.

Diagrama esquemático da operação do SpikeGPT baseado em um modelo de linguagem, que é construído sobre os princípios de um valor-chave ponderado pela suscetibilidade – Receptance Weighted Key Value, RWKV (fonte: Universidade da Califórnia, Santa Cruz)
A RNN, por outro lado, está focada, antes, em isolar uma estrutura estendida no tempo na sequência de dados que lhe é oferecida, sejam barras de uma composição musical, palavras em uma frase ou operadores em um fragmento de código de programa – ou seja, a estrutura, não o conteúdo. É precisamente por isso que as redes neurais recorrentes são tão boas na “geração de absurdos” – quando baseadas em uma série de dados de origem alimentados ao modelo (peças de Shakespeare, artigos de uma enciclopédia on-line diretamente com marcação XML, ensaios sobre geometria algébrica em formato LaTeX, ou seja, diretamente com fórmulas e diagramas matematicamente corretos, etc.) RNN gera a saída primeiro. à primeira vista, indistinguível do original – em termos de gramática, sintaxe e até estilística – mas na maioria das vezes não contendo absolutamente nenhum significado. Tais frases, compostas por palavras de dicionário de acordo com todas as regras gramaticais, mas desprovidas de qualquer conteúdo substantivo – são representadas pelo exemplo conhecido por todos que estudaram filosofia da ciência, “a lua se multiplica quadrangularmente” – Bertrand Russell as classificou como “absurdo do segundo tipo” ” Externamente, não são muito diferentes das alucinações dos modelos generativos, mas num nível profundo a diferença é significativa. Uma coisa é um vetor falhar, que deveria apontar para uma determinada região bem definida (devido ao treinamento preliminar do modelo) no espaço latente, mas por um motivo ou outro foi perdido; a outra é obviamente e não envolveu qualquer “extração de significados” num estágio anterior, combinando elementos que não estão de forma alguma relacionados entre si (para uma determinada rede neural) de acordo com padrões formais bem estabelecidos (pela mesma rede neural). regras.
Porém, no atual estágio de desenvolvimento, os RNNs estão se aproximando em termos de “extração de significados” aos FFNNs baseados na arquitetura de transformadores, até o surgimento (até agora na forma de um experimental, inacessível ao público em geral, mas totalmente protótipo funcional) modelo generativo SpikeGPT, que opera com quantidades-chave ponderadas pela receptividade – valor-chave ponderado pela receptividade (RWKV). Os blocos RWKV abrem a possibilidade de treinamento acelerado (devido à paralelização de threads) para uma rede neural pulsada, mas um treinamento significativamente mais longo reduz o valor prático até mesmo de uma implementação puramente virtual de RNNs modernos em comparação com FFNNs. No entanto, uma das principais vantagens de uma rede neural recorrente é a dependência linear da complexidade computacional em escala (e não quadrática, como a dos transformadores), portanto os modelos RNN com um número comparável de parâmetros certamente serão mais eficientes em termos energéticos do que os atuais. sistemas geradores comuns construídos em arquitetura de transformador. Assim, o mencionado SpikeGPT em versões com 45 milhões e 216 milhões de parâmetros produziu, segundo seus criadores, vinte vezes menos operações computacionais do que seus rivais de complexidade comparável baseados em transformadores, ao mesmo tempo em que demonstrou resultados comparáveis em uma série de testes significativos para avaliar capacidades sistemas de aprendizado de máquina.

O princípio geral de operação da camada de autoatenção na arquitetura do transformador (fonte: The Illustrated Transformer)
De acordo com Mike Davies, diretor do Laboratório de Computação Neuromórfica da Intel, escalar redes neurais com picos para os grandes modelos de linguagem baseados em FFNN dominantes no mundo com transformadores continuará a ser um grande desafio até que uma base de hardware eficiente para RNNs seja proposta (ele falou ainda mais especificamente sobre computadores neuromórficos semicondutores: “Este será um caminho realmente emocionante neste domínio e, enquanto não estivermos lá ainda – precisaremos de uma iteração de silício para apoiá-lo”). E é claro por quê: emular redes neurais complexas na memória de computadores von Neumann é proibitivamente caro precisamente por causa da característica arquitetônica mais importante desses sistemas de computação. Ou seja, a separação física do armazenamento de dados (memória; em particular, RAM de alta velocidade) do nó (processador) que realmente executa os cálculos. Quanto mais complexa é uma rede neural, mais dados precisam ser movidos entre a RAM e a CPU para mantê-la funcionando – e a largura de banda limitada se torna uma das principais barreiras para dimensionar tal sistema. Os chips Loihi que já analisamos e uma série de implementações de semicondutores semelhantes de computadores neuromórficos são projetados precisamente colocando células de memória mais próximas de nós de processador primitivos, mas de alta velocidade, para aproveitar as vantagens dos RNNs usando tecnologias de fabricação de semicondutores já bem estabelecidas.
⇡#Problemas e soluções
Uma razão importante, entre outras, pela qual os mesmos chips Loihi 2 ainda não suplantaram os adaptadores de servidor Nvidia de data centers em todo o mundo que devoram centenas de watts de cada vez, é a dificuldade de treinar redes neurais recorrentes. Não basta criar uma base de hardware para o seu funcionamento energeticamente eficiente: se a máquina inteligente assim obtida começar a gerar respostas com uma percentagem significativamente superior de respostas incorretas do que o mesmo GPT-4o ou seus análogos, o próprio facto de é improvável que uma redução significativa na intensidade energética de tal dispositivo console seus usuários. O problema é que o método mais comum de treinamento de FFNN (perfeitamente adequado para modelos aprimorados com transformadores), a retropropagação, não pode ser aplicado diretamente no caso de RNN. Como as células de uma rede neural recorrente armazenam de alguma forma informações sobre estados anteriores, simplesmente alterar os pesos nas entradas não é suficiente – você também precisa influenciar a “memória” de seus valores passados, ou seja, aplicar retropropagação ao longo do tempo, BPTT.

Cada bloco RNN, mudando seu estado sob a influência do próximo impulso, retém a memória do passado – e ao treinar com retropropagação de erro, isso deve ser levado em consideração (fonte: Stanford.edu)
Mas também com isso nem tudo é simples e, no nível fundamental, matemático. A principal ferramenta de trabalho para a configuração de redes neurais – o gradiente – é um vetor de derivadas parciais da função perda sobre todos os pesos ajustados: é este vetor que indica a direção de maior crescimento da função perda sobre todo o conjunto de pesos de uma vez. As derivadas parciais refletem diferenças, muitas vezes extremamente fortes, entre os valores dos pesos individuais: isso é típico, aliás, não apenas para RNNs, mas também para FFNNs multicamadas. Como resultado, muitas vezes surgem situações desagradáveis quando o gradiente explode (gradiente explodindo) ou, inversamente, desaparece (gradiente desaparecendo), ou seja, seu valor ultrapassa o tipo de dados em que está armazenado ou diminui para um valor insignificante – e neste Nesse caso, o erro, como é fácil de entender, não se propaga mais, ou seja, o aprendizado realmente para. Eles combatem isso no caso do SNN, em particular, organizando o treinamento por meio da plasticidade de impulsos dependente do tempo (plasticidade dependente do tempo de pico, STDP), que, aliás, também é característico das redes neurais biológicas, mas para implementar o STDP, ao contrário do BPTT, algoritmos muito mais sofisticados, cujo desenvolvimento em si é semelhante à arte e é amplamente baseado nas características da implementação de hardware de um determinado sistema neuromórfico. Já estamos começando a falar sobre meta-aprendizado – isto é, sobre treinar redes neurais recorrentes não para resolver um problema específico, mas em geral sobre como elas próprias podem aprender a resolver tais problemas.
A lista de desafios enfrentados pelos desenvolvedores de sistemas neuromórficos é realmente enorme – e nós, veja bem, ainda nem começamos a considerar possíveis opções para sua implementação em hardware, exceto talvez semicondutores, usando o exemplo de Loihi dado no artigo anterior desta série . Basta apontar apenas alguns dos mais significativos:
- Complexidade técnica – um grande número de componentes interconectados, que (se não estamos falando de produção de semicondutores com bom funcionamento, e os computadores semicondutores neuromórficos têm suas próprias limitações) hoje são extremamente difíceis de produzir em escala em massa com o nível necessário de qualidade,
- Dificuldades na integração de sistemas neuromórficos com computadores semicondutores convencionais – por exemplo, para neuroprocessadores ópticos é necessário desenvolver nós para interligá-los com circuitos elétricos, e a fotônica, como já observamos, não é em si a mais simples engenharia e campo aplicado ,
- O dimensionamento de sistemas neuromórficos é complicado por um aumento múltiplo na complexidade técnica (em comparação com o protótipo original) e um aumento correspondente na probabilidade de falhas,
- Seu treinamento, como já foi observado, por si só representa um desafio considerável – devido à frequência significativa de explosões/desaparecimentos de gradientes e à necessidade de preparar matrizes especializadas de dados de treinamento e criar benchmarks de desempenho adequados, confundindo ainda mais o conceito de “qualidade de treinamento” ,
- A própria localização dos neuromórficos como um ramo da engenharia científica na intersecção da biologia (em termos de estudo das características dos protótipos naturais), cibernética, microeletrônica e muitas outras disciplinas apresenta exigências quase proibitivas para aqueles que querem tentar a sua sorte neste , e a falta de pessoal qualificado em nada contribui para a aceleração do progresso nessa direção,
- Sistemas neuromórficos de hardware, uma vez que quase nenhum deles é baseado em processos bem estabelecidos e de produção em massa, são extremamente propensos, para dizer o mínimo, à imperfeição – as características de desempenho de seus vários nós (do mesmo tipo!) podem diferir visivelmente em desempenho/confiabilidade e outras características, que afetam diretamente a qualidade de operação do sistema neuromórfico finalizado como um todo.

Montagem de 16 chips neuromórficos semicondutores criados como parte do programa DARPA SyNAPSE (Systems of Neuromorphic Adaptive Plastic Scalable Electronics): tecnologia de processo de 28 nm, 1 milhão de neurônios artificiais e 256 milhões de sinapses em cada chip (fonte: Wikimedia Commons)
No entanto, os investigadores não recuam: os benefícios potenciais da introdução de sistemas neuromórficos em uso regular são demasiado grandes, mesmo que sejam utilizados para uma gama limitada de tarefas e não substituam completamente as redes neurais FFNN construídas em transformadores. Mike Davis, mencionado anteriormente, em entrevista ao EE Times, deu o seguinte exemplo: em termos da métrica de atraso de energia (contabilidade combinada da energia gasta na execução de uma determinada tarefa e da latência ao executar esta tarefa em um circuito de computação), hardware os sistemas neuromórficos são capazes de fornecer superioridade sobre as redes neurais generativas executadas na memória das máquinas de von Neumann, em três ordens de magnitude decimais. Entre os problemas que podem ser resolvidos quase exclusivamente por computadores neuromórficos – e, num futuro ainda mais distante, por computadores quânticos (simplesmente porque o hardware convencional é muito ineficiente para resolvê-los) está a otimização binária quadrática irrestrita (QUBO). de aplicabilidade, bem como controle preditivo da robótica em tempo real. Talvez, na ausência de computadores neuromórficos colocados em funcionamento, não veremos robôs verdadeiramente inteligentes que operem adequadamente no ambiente em mudança do mundo real. Mas qual pode ser exatamente a base material para seus “cérebros” neuromórficos, analisaremos no próximo material da série – já existe um bom número de opções oferecidas hoje.
⇡#Materiais relacionados
- Uma Comissão do Congresso dos EUA propôs que as autoridades repetissem o Projeto Manhattan, mas agora para criar uma IA de nível humano.
- Sandia National Laboratories lançou o sistema Kingfisher AI em enormes chips Cerebras WSE-3.
- A UE publicou projetos de regras sob as quais existirá IA a nível humano.
- A Applied Materials deu a entender que a demanda por equipamentos para fabricação de chips será moderada.
- A Nvidia tem como alvo o mercado de robôs humanóides – ela lhes fornecerá “cérebros”.