
⇡#Caminhão e Oversize
Não faz muito tempo, no final de julho, os desenvolvedores de inteligência artificial generativa (IA) para visualizar prompts de texto do Stability.ai anunciaram o lançamento de seu próximo modelo básico, Stable Diffusion XL (SDXL) versão 1.0 (suas versões preliminares) já estiveram disponíveis para testes extensivos por entusiastas antes). As diferenças entre as arquiteturas do SDXL e dos modelos anteriores (SD 1.4, SD 1.5, SD 2.1) são profundas o suficiente para merecer consideração especial. Na prática, é importante que o bom e velho Lorry, que mesmo o SD 2.1 aparentemente muito mais progressivo não conseguiu empurrar do pedestal em muitos meses, continue sendo a opção preferida para desenho de IA local por um bom tempo.

Ferramentas on-line para robôs de desenho de IA (e mais!) Com base no modelo SDXL 1.0 estão disponíveis, embora com limitações, para qualquer pessoa interessada (fonte: captura de tela clipdrop.co)
Precisamente local: os recursos de nuvem que oferecem acesso ao SDXL (principalmente o site clipdrop.co com suporte Stability.ai ou o conhecido mage.space, onde o SDXL 1.0 agora se tornou o modelo básico padrão) certamente serão mais populares entre uma ampla gama de interessados em arte do que sites semelhantes que fornecem acesso a pontos de verificação com base no SD 1.5. A razão é simples: na configuração básica, o SDXL produz objetivamente imagens mais atraentes baseadas em pistas mais concisas e descomplicadas do que o Lorry.
Atraente em um sentido bastante amplo: é uma melhor elaboração de pequenos elementos (a resolução padrão original da imagem criada para SDXL 1.0 é 1024 × 1024, para SD 1.5 é 512 × 512) e uma iluminação mais convincente do gerado cenas, incluindo reflexos de luz confiáveis em superfícies de várias texturas e contraste e brilho próximos ao natural de imagens fotorrealistas. O novo modelo ainda gera mãos longe de ser sempre ideais (embora tenha sucesso objetivamente com mais frequência do que o Lorry, especialmente o modelo básico SD 1.5, que não passou por treinamento adicional), mas lida com textos ao contrário de seus antecessores . E, em geral, o fato de o SD 1.5 inicialmente ter treinado em uma matriz de aproximadamente 90 milhões de imagens anotadas e o SDXL 1.0 em uma amostra de 6,6 bilhões (mais precisamente, 3,

No entanto, no Civitai – provavelmente o repositório mais popular de modelos de IA distribuídos gratuitamente na Web hoje para converter texto em imagens – a versão básica do SDXL 1.0 no início de agosto tinha 1,5 mil “curtidas” e 22 mil downloads, então como um Um dos checkpoints mais populares baseados em SD 1.5, DreamShaper, tem 29.000 curtidas e 411.000 downloads. E nem tanto porque a primeira página está ativa há pouco mais de uma semana, enquanto a segunda está ativa desde janeiro de 2023. Muitos entusiastas, ao decidir baixar o SDXL 1.0 para rodar em uma máquina local, enfrentam uma série de dificuldades, que vão desde problemas com a integração deste modelo no AUTOMATIC1111 até a falta de uma ampla gama de ferramentas adicionais, como inversões de texto, LoRA , upscalers que usam memória de vídeo com moderação, etc. P.
É claro que estamos falando principalmente de dores de crescimento: em um ou dois meses, a comunidade de entusiastas provavelmente desenvolverá para o novo Oversize (SDXL) versão 1.0 ferramentas quase mais extensas do que para SD 1.5 no mesmo período de tempo desde o modelo foi colocado em acesso geral. No entanto, faz sentido continuar estudando os meios de otimizar os desenhos emitidos pela AI por enquanto com base no bom e velho “Caminhão” – e no âmbito do ambiente de trabalho AUTOMATIC1111, que já é bem conhecido dos leitores de nossos “Workshops” anteriores sobre este tópico: COMO FAZER: como instalar e configurar sua própria IA em um PC para jogos e oficina de pintura de IA, parte dois.
Para SDXL 1.0, se de repente alguém quiser experimentá-lo em seu estado atual, podemos recomendar o ambiente de trabalho ComfiUI: não com a interface mais antiga, mas programaticamente otimizada perfeitamente especificamente para Oversize, até o fato de que em placas de vídeo com 6 GB de memória, o modelo funciona em uma velocidade bastante aceitável.
⇡#Comparamos relógios
Embora todas as etapas de geração de imagens e sua melhoria subsequente com a ajuda de IA descritas na estrutura deste “Workshop” sejam bastante viáveis em versões anteriores do AUTOMATIC1111, no caso geral seria razoável atualizar para o mais recente – pelo menos no início de agosto, seu número 1.5.1. Além disso, é metodologicamente útil aprender a atualizar manualmente os pacotes de software instalados via Git (ou semi-automaticamente por meio de um arquivo BAT de inicialização, como será demonstrado a seguir) – isso pode ser útil não apenas em um aplicativo para desenho de IA.
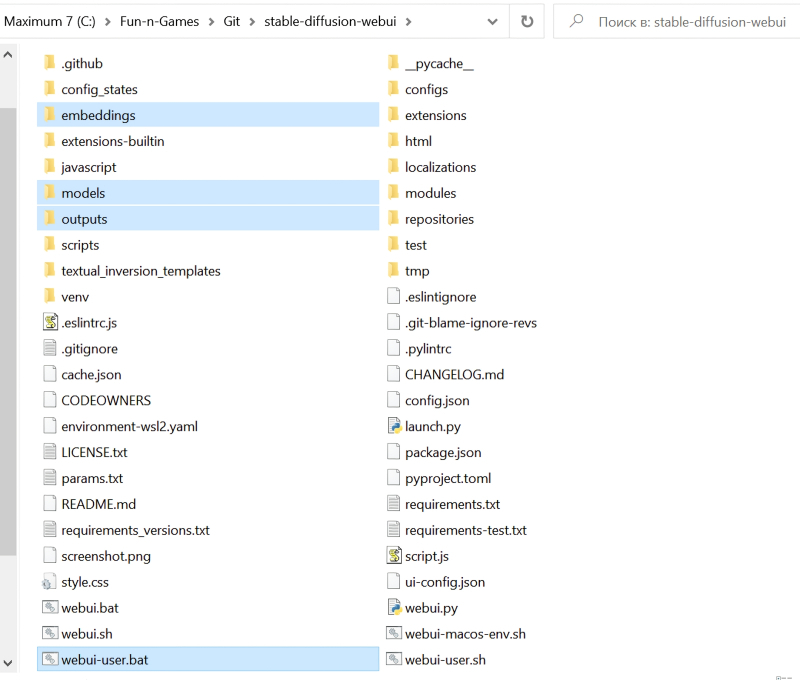
Esta captura de tela destaca os elementos do diretório de instalação AUTOMATIC1111 que seria útil copiar para uma mídia externa antes de atualizar a versão atual
A primeira coisa que todo entusiasta de qualquer atividade que resulte em arquivos hospedados em um PC local deve mostrar preocupação ativa é com o backup. O processo de atualização das versões do ambiente de trabalho AUTOMATIC1111 não prevê a substituição completa do diretório de origem e, mais ainda, a exclusão de imagens geradas anteriormente e armazenadas nele, mas neste caso é muito melhor exagerar do que não faça isso. Em qualquer meio de armazenamento externo ao drive lógico no qual o cliente Git e este ambiente de trabalho estão implantados, copie a pasta embeddings do diretório principal stable-diffusion-webui (há inversões de texto), models (os modelos são diferentes, mas no decorrer das lições anteriores, carregamos principalmente LoRA e checkpoints em seus subdiretórios; pré-treinado e otimizado para reduzir o tamanho da versão SD 1.5 do modelo básico), saídas (isso é simplesmente inestimável – todas as nossas imagens da geração anterior estão aqui por padrão!), Bem como o arquivo webui-user.bat com parâmetros de inicialização modificados. Um backup pode exigir várias dezenas de GB, tudo é determinado pelo tamanho da pasta com pontos de verificação e, em muito menor grau, pelo diretório com imagens prontas.

O próximo passo é cuidar das configurações da interface da web, que podem cair inadvertidamente durante a atualização. Além disso, aproveitando esta oportunidade, seria bom otimizar várias dessas configurações ao mesmo tempo. Portanto, na seção “Configurações”, o primeiro dos subitens alinhados à esquerda em uma coluna, “Salvando imagens / grades”, contém um campo para definir “Padrão de nome de arquivo de imagens” – padrões de nomenclatura de arquivo.
Por padrão, esse modelo é trivial: as imagens são colocadas em uma pasta dentro do diretório de saídas correspondente à forma como foram geradas (“txt2img-images”, por exemplo, para imagens obtidas diretamente de prompts de texto) e em uma subpasta cujo nome é determinado pela data atual (digamos, “2023-08-02”). Dentro dessa pasta de nível inferior, cada foto sucessiva daquelas que ali caem sequencialmente recebe um número de série, seguido de um hífen seguido do valor de “semente” – a semente que serviu de base para o procedimento de extração de um significativo (no olho humano) imagem dos abismos ctônicos do espaço latente. Esta, de fato, é a essência da geração de IA pelo método de espalhamento estável [retrocesso] – difusão estável.
Como pretendemos experimentar mais, faz sentido atribuir nomes às imagens de acordo com uma legenda mais detalhada, indicando no nome do arquivo correspondente não apenas a semente, mas também o número de etapas e CFG (orientação gratuita do classificador, ” parâmetro do classificador livre” – veja o anterior para mais detalhes). lançamento do “Workshop” no desenho AI). Portanto, no campo “Padrão de nome de arquivo de imagens”, você deve definir o seguinte padrão:
[Semente]-[passos]-[cfg]
Lá, na página, há um link para o Wiki, que é baseado diretamente no GitHub – quem estiver interessado pode estudar a convenção de nomenclatura com mais detalhes a qualquer momento. Também vamos garantir que as caixas de seleção estejam nas posições “Adicionar número ao nome do arquivo ao salvar” e “Sempre salvar todas as grades de imagem geradas”. Este último será útil quando se trata de criar de uma só vez não imagens únicas, mas todos os seus conjuntos ordenados (grades) de acordo com regras pré-especificadas. É útil formar esses conjuntos para estudar as possibilidades de pontos de verificação, inversões de texto, vários parâmetros nos campos de dicas de texto – em uma palavra, para experimentação.
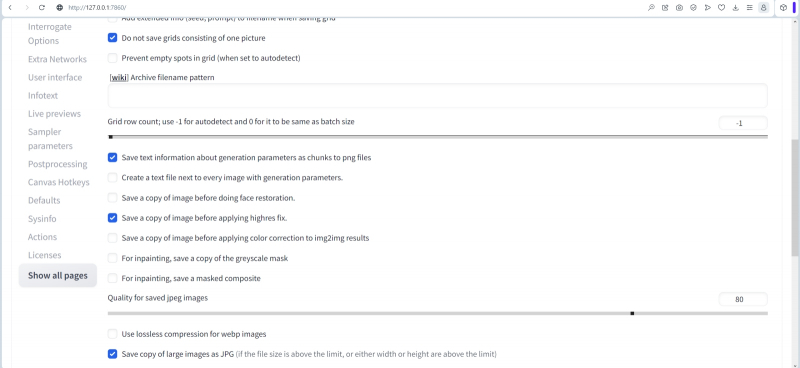
Abaixo, na mesma página, você precisará marcar (ou confirmar por si mesmo se já estão nas posições corretas) os seguintes itens:
- «Salve as informações de texto sobre os parâmetros de geração como blocos em arquivos png” – isso é importante para salvar os dados de geração dentro da imagem. Também pode ser útil ativar o item “Criar um arquivo de texto ao lado de cada imagem com parâmetros de geração”: como resultado, na pasta com fotos, cada imagem (por padrão, um arquivo em formato PNG) também será acompanhada por um arquivo TXT com o mesmo nome e explicitamente os parâmetros de geração prescritos nele. Sim, não é difícil obter esses parâmetros de qualquer maneira arrastando a imagem gerada com o mouse para o campo apropriado na guia Informações do PNG – já fizemos esse truque várias vezes nos Workshops anteriores. Mas às vezes um arquivo de texto separado, já pronto para visualização rápida, pode ser útil.
- «Salve uma cópia da imagem antes de aplicar a correção de alta resolução ”- útil se esse mesmo ajuste for aplicado com um aumento na resolução (submenu “Correção de alta resolução” na guia “txt2img”). Anteriormente, não usávamos tal ajuste, preferindo mover a imagem gerada em baixa resolução para a guia “img2img” e trabalhar com ela explicitamente, manualmente. No entanto, os autores de alguns pontos de verificação recomendam diretamente o uso da correção Highres toda vez que você criar uma nova imagem. Nesse caso, será útil poder comparar o que era a imagem gerada originalmente e o que ela se tornou após a aplicação do ajuste automatizado.
- «Salvar cópia de imagens grandes como JPG” – esta opção será muito útil ao gerar grandes conjuntos ordenados de imagens, por exemplo, usando o script “X/Y/Z Plot” embutido no AUTOMATIC1111. Salvas como PNG, grandes tabelas de resumo de imagens criadas com parâmetros diferentes são convenientes para comparação detalhada, mas nem todas as placas de vídeo (e nem todos os visualizadores de imagens!) Abrirão um arquivo de, digamos, 120-130 MB. A criação automática de sua cópia em JPG, e mesmo com compressão, facilita muito o estudo posterior do material resultante.
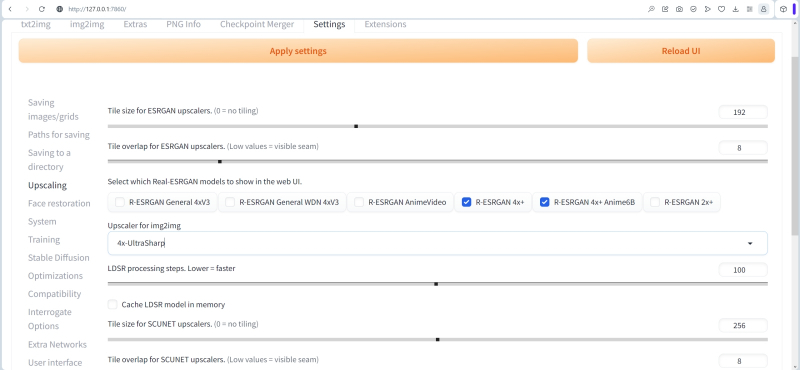
Tudo na mesma aba “Configurações”, mas já na linha “Upscaling”, é razoável começar a agilizar a variedade de opções oferecidas pelo sistema. Em particular, para aumentar a resolução da imagem com maior detalhe (upscaling), deixaremos apenas os upscalers da família R-ESRGAN 4x+, mencionados na última edição do “Workshop”. Como upscaler padrão na guia “Img2img” – seletor Upscaler para img2img – selecione 4x-UltraSharp.
⇡#Afinação
Na linha de seleção do grupo de configurações “Difusão estável”, na parte inferior da página, há uma opção “Fonte do gerador de números aleatórios”.
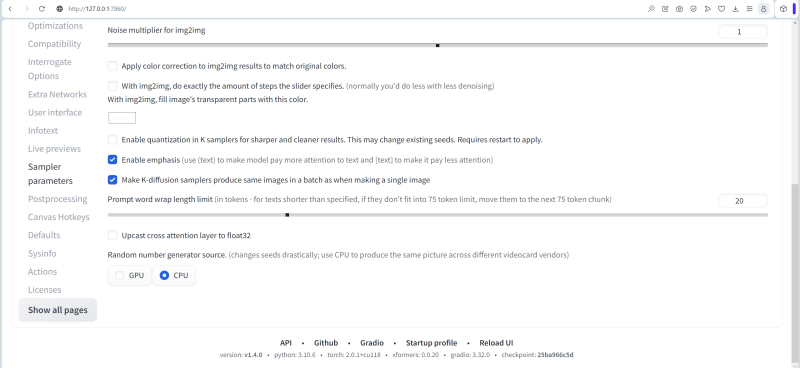
Seu significado como um todo é óbvio: os geradores de números aleatórios estão disponíveis tanto nos processadores centrais quanto nos gráficos. Uma dica de ferramenta do autor de AUTOMATIC1111 informa inequivocamente: “Muda as sementes drasticamente; usar a CPU para produzir a mesma imagem em diferentes fornecedores de placas de vídeo”. Em outras palavras, a obtenção de sementes para posterior criação de imagens em GPUs de diferentes fornecedores é implementada de maneiras diferentes. Portanto, se houver o desejo de garantir a reprodutibilidade conhecida dos resultados obtidos uma vez – uma combinação bem escolhida de dicas de texto, semente, número de etapas de geração, CFG – é razoável mudar essa chave para a posição da CPU. E então, em computadores diferentes (com placas de vídeo diferentes), a mesma semente geralmente gera a mesma imagem inicial, aquele tapete heterogêneo de manchas multicoloridas, que é então convertido em uma imagem de acordo com os parâmetros de entrada do sistema. Mas se você confiar esta geração à GPU, as opções já são possíveis.
Na seção Compatibilidade, costuma-se marcar a caixa “Não torne o DPM++ SDE determinístico em diferentes tamanhos de lote”. Nesse caso, isso é de alguma importância, pois estamos nos concentrando na estrutura deste “Workshop” no DPM ++ SDE (na variante Karras) como o principal amostrador de trabalho. Para experimentar e dominar o AUTOMATIC1111, esta caixa de seleção não é tão importante, mas sua presença torna-se novamente fundamental se o usuário deseja reproduzir no sistema local uma determinada imagem, cujos parâmetros ele conhece com certeza: por exemplo, existem muitos de imagens nas galerias do já mencionado repositório Civitai com dados de geração inicial estritamente fixos.
A história desta opção é bastante instrutiva. Em algum lugar no início de 2023, o autor de AUTOMATIC1111 corrigiu um bug devido ao qual imagens com os mesmos parâmetros iniciais eram geradas por amostradores DPM ++ SDE de maneira um pouco diferente, dependendo se o operador definiu a criação de uma única imagem ou sua série de uma só vez ( lote) – com a mesma semente inicial. Em meados de fevereiro, o bug foi corrigido, mas descobriu-se que muitas das imagens criadas anteriormente não podem ser reproduzidas uma a uma. Portanto, essa opção de compatibilidade apareceu nas configurações. É útil para usuários iniciantes deste ambiente de trabalho saber disso, pelo menos para não se culpar ou ao sistema,
Na seção “Interface do usuário”, verifique se a “Lista de configurações rápidas” contém pelo menos estas três opções: “sd_model_checkpoint, sd_vae, CLIP_stop_at_last_layer”. Para que eles são necessários, já descobrimos em edições anteriores do “Workshop”; neste caso, é importante que essas configurações sobrevivam com sucesso à próxima atualização do AUTOMATIC1111.
Na seção “LivePreviews”, você pode configurar quais versões intermediárias da imagem final serão mostradas durante a geração. Quanto mais lento o computador (neste caso, quanto mais antiga e menos rica em memória for sua placa gráfica), mais tempo essas criações inacabadas do artista de IA ficarão diante dos olhos do usuário. Portanto, a abordagem para escolher os parâmetros nesta seção deve ser mais estética do que prática.
Embora na prática a visualização possa ser muito útil: no exemplo com dois robôs, que analisaremos a seguir, o objetivo da geração inicial será escolher uma imagem em que ambos os andróides sejam representados em pleno crescimento (em casos extremos, joelho -profundo). Portanto, se já é perceptível em uma visualização embaçada que uma figura emergindo das profundezas do espaço latente é mostrada na cintura ou no peito, e o desenho é iniciado em um loop infinito (pressionando o botão oculto “Gerar para sempre”) , seria lógico economizar tempo do computador e recursos da placa de vídeo clicando em “Ignorar” e, assim, pular a geração atual para um final completo.
Na seção “Parâmetros do amostrador”, há liberdade absoluta para o sabor mais puro. Os samplers Euler a e DPM++ SDE Karras devem ser deixados em qualquer caso: o primeiro, como o mais popular, é sempre necessário, e o segundo usaremos constantemente no âmbito deste “Workshop”. Samplers “Ancestrais” – ancestrais; é a partir daí que a letra “a” nos nomes se distingue pela maior variabilidade ao trabalhar com uma determinada semente (semente): imagens com diferentes números de etapas de geração e com diferentes CFGs, mas com a mesma semente, às vezes podem parecer completamente diferentes um do outro. De uma forma ou de outra, quais samplers deixar na interface AUTOMATIC1111 à vista e quais usar é uma questão de preferência pessoal. Você pode estudar visualmente o comportamento de diferentes amostradores dependendo de diferentes parâmetros de entrada usando o script X/Y/Z Plot,
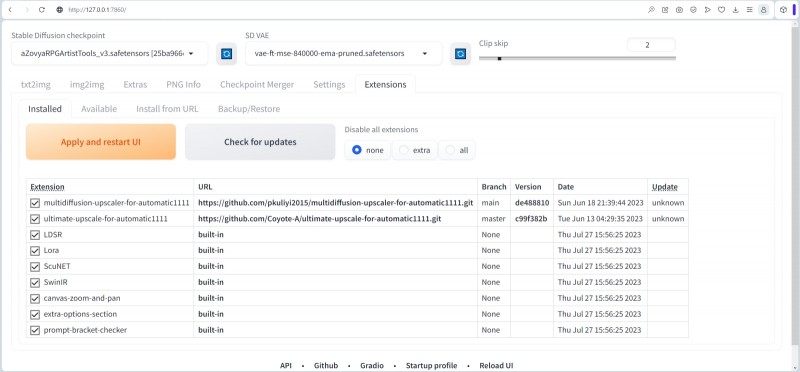
Em seguida, na guia “Extensões”, verificamos quais extensões adicionamos anteriormente ao sistema. Quem reproduziu na prática os passos dados na segunda edição do “Workshop” sobre desenho de IA, com certeza verá pelo menos uma extensão instalada nesta seção – Ultimate SD upscale; vem em segundo lugar nesta captura de tela. Quanto ao primeiro upscaler Multidiffusion, se você ainda não o tem, tudo bem: logo chegará a hora de tratá-lo de perto.
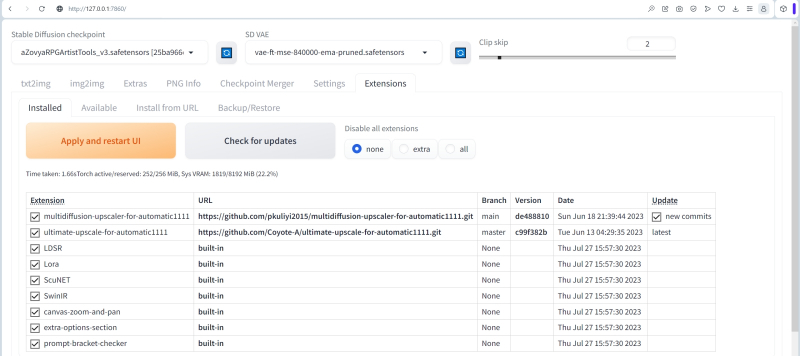
O espaço de trabalho AUTOMATIC1111, ao contrário do nome, não faz tudo automaticamente. No entanto, do ponto de vista de grande parte dos entusiastas que lidam com software livre, é o melhor: muitos preferem tomar uma decisão consciente e informada sobre o que e quando atualizá-los. Em particular, na mesma guia “Extensões – Instaladas”, é fornecida uma verificação manual de atualizações para extensões instaladas: você precisa clicar no botão grande “Verificar atualizações”. Nesse caso, descobriu-se que apenas o upscaler Multidiffusion tinha uma atualização (denotada como “novos commits”). E é fácil de instalar marcando a coluna “Atualizar” e clicando no banner laranja “Aplicar e reiniciar a interface do usuário”.
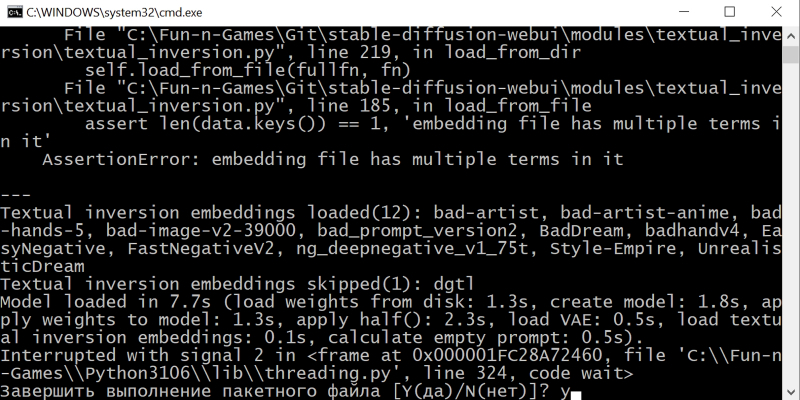
Bem, na verdade, isso é tudo para verificar o estado da interface. Feche a aba do navegador com AUTOMATIC1111; na janela da linha de comando que se abriu após a execução do arquivo webui-user.bat, pressione Ctrl + C e, após o prompt aparecer, o latino “y” sem aspas – e depois Enter.
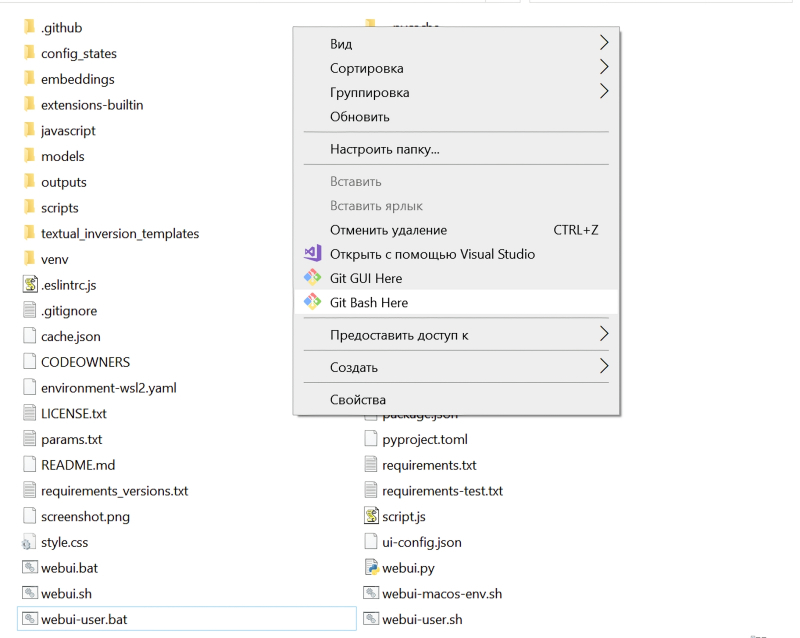

Depois disso, você precisa digitar o comando “git pull” sem aspas na janela que se abre, pressionar o botão “Enter” do teclado e … na verdade, é isso. O processo de atualização da distribuição baixada do Git será iniciado. Leva muito pouco tempo: a coisa mais “pesada” no kit de ferramentas de um pintor de IA são os pontos de verificação, e o próprio espaço de trabalho AUTOMATIC1111 não os contém.
Alguns entusiastas recomendam (semi)automatizar o processo de atualização regular de um determinado workbench simplesmente adicionando “git pull” ao seu arquivo inicial, webui-user.bat, no final, entre as linhas “set COMMANDLINE_ARGS” e “call webui.bat “. Às vezes, realmente faz sentido: digamos, após uma atualização recente para a versão 1.5.0, ficou imediatamente claro que o AUTOMATIC1111 começou a trabalhar com LoRA e outras ferramentas não exatamente da maneira esperada, e uma correção foi lançada rapidamente depois disso remendo, 1.5.1. E se alguém baixou manualmente a versão 1.5.0 e depois começou a tirar fotos e parou de seguir a vida agitada da comunidade Stable Diffusion (por exemplo, no Reddit), ele teve todas as chances de ficar com o LoRA que funciona de maneira torta por um longo tempo. Por outro lado, quando os usuários são bastante estáveis, a versão 1.4. 0 (devido à atualização automática configurada anteriormente) de repente tiveram os mesmos problemas, eles tiveram que reverter manualmente para a versão anterior ou suportar vários dias antes da publicação da correção. Em geral, a instalação manual e automática de atualizações tem prós e contras. O principal é que não é nada difícil organizar os dois.

Agora é a hora de reabrir http://127.0.0.1:7860 no navegador – e certifique-se, rolando até o final da página, que o número da versão atual de AUTOMATIC1111 é exibido exatamente como 1.5.1 (ou o que for estará lá no momento em que você produzir sua atualização). É hora de passar da renovação para a prática!
⇡#O que fazer?
E agora, após a atualização, é hora de explicar que tipo de extensão é na aba “Extensões”, multidiffusion-upscaler-for-automatic1111, e de onde veio. Inicialmente se chamava Multidiffusion Upscaler, mas agora o projeto se chama oficialmente Tiled Diffusion & VAE, e seu código (mais notas introdutórias do autor, mais discussões de membros da comunidade) também está localizado no GitHub, como no caso do AUTOMÁTICO1111.
No entanto, não há necessidade de baixá-lo de lá e implantá-lo manualmente. Na mesma guia “Extensões”, ao lado da subguia “Instalado”, na qual acabamos de verificar se há atualizações para as extensões baixadas anteriormente, há outra subguia – “Disponível”. Entrando lá e clicando no enorme botão laranja “Carregar de”, obteremos uma lista de extensões disponíveis para instalação no repositório oficial AUTOMATIC1111, assim como na edição anterior do Workshop, quando baixamos a extensão upscale Ultimate SD.

AVISO: a captura de tela foi tirada durante a instalação da versão original do Multidiffusion Upscaler, cujo nome era diferente do atual
Nesta lista, você precisa encontrar a linha desejada pela palavra-chave “Ladrilhos”, clicar no botão cinza “Instalar” à direita e, em seguida, rolar a mesma página até o topo, “Aplicar e reiniciar a interface do usuário”.
Após a reinicialização, na guia principal de trabalho do AUTOMATIC1111, “txt2img”, dois novos submenus suspensos aparecerão imediatamente abaixo da janela de entrada do valor inicial: “Tiled Diffusion” e “Tiled VAE”. Agora vamos trabalhar com eles.
Por que, em princípio, você precisa de uma divisão adicional da imagem em ladrilhos (ladrilhos)? Essa é uma das maneiras mais eficazes de superar uma desvantagem inerente do SD 1.5 e até 2.1 como capacidade francamente fraca de criar imagens não quadradas. O sistema foi treinado em dezenas de milhões de figuras quadradas, e neste formato (em sua versão básica) está mais ou menos pronto para formar imagens adequadas. Assim que a tela é ligeiramente esticada em uma das direções, a probabilidade de artefatos aumenta drasticamente.

SD versão 2.1 “entende” exatamente o que desenhar no prompt “snegurochka” no formato paisagem, mas muitas vezes retrata (quase) a mesma coisa duas vezes – porque é treinado em quadrados, que cabem quase dois em um retângulo 16: 9 ( fonte: geração AI com modelo SD 2.1)
Com uma proporção de 4:5, isso ainda é um pouco perceptível, mas em um retângulo de 2:3 em diante, obter o dobro do objeto indicado na dica de texto fica mais fácil do que nunca. E essa duplicação ocorre porque a rede neural treinada em amostras quadradas “tende a ver” em qualquer retângulo dois – pelo menos dois – quadrados parcialmente sobrepostos. E também é bom se o retângulo for horizontal: em vez de um, digamos, uma pessoa indicada em uma dica de texto, provavelmente dois quase gêmeos aparecerão na imagem. Se a tela for esticada verticalmente, o modelo SD 1.5 original (antes dos primeiros checkpoints treinados por entusiastas começarem a aparecer na Web) sem hesitação dobrou os torsos e / ou cabeças nos retratos, combinando de forma bastante orgânica, digamos, a cintura com o pescoços … br-r. Eu não quero lembrar.
Portanto, o principal objetivo do Tiled Diffusion & VAE é lidar com esse problema, quebrando a tela original em blocos quadrados (na maioria das vezes 512×512) e forçando, de fato, o SD 1.5 a gerar uma imagem em pedaços quadrados, como ela gosta. Mas, ao mesmo tempo, a imagem sai mutuamente consistente – já que o sistema tem a oportunidade de “olhar” para os quadrados vizinhos em uma determinada profundidade. É claro que uma divisão tão múltipla da tela, e mesmo com a imposição de “zonas de atenção” nas praças vizinhas, requer recursos de tempo de computador significativos: gerar uma única imagem com Tiled Diffusion & VAE pode levar duas ou três vezes mais tempo como sem esta extensão. Mas o limite superior do tamanho de tal imagem, como garante o autor da extensão, faz 16384×16384 pontos quase impensáveis - e isso é em uma passagem; sem qualquer upscaling adicional.
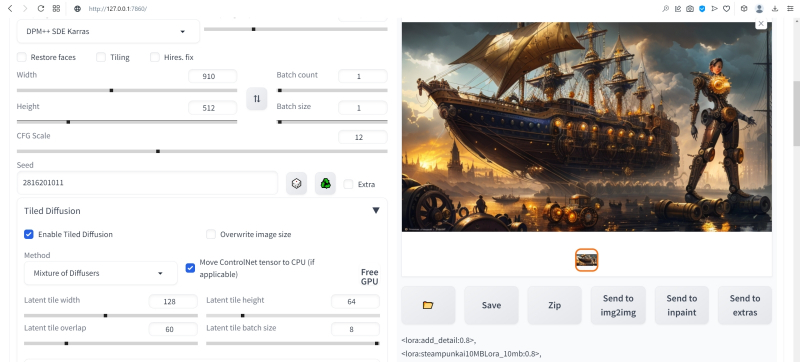
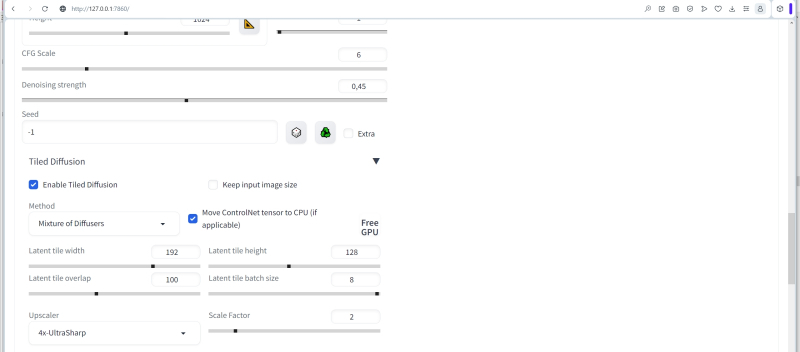
Então, abra o submenu suspenso “Tiled Diffusion” e ative a extensão marcando a caixa “Enable Tiled Diffusion”. Perto está uma opção extremamente interessante “Substituir tamanho da imagem”. É ela a responsável por “inflar” a imagem original a um tamanho alucinante sem perder a consistência da composição (dentro dos limites estabelecidos pelas capacidades desse ponto de verificação e pelo conteúdo dos prompts de texto, é claro). Ainda não vamos ativá-lo, porque no primeiro estágio precisaremos do poder do Tiled Diffusion & VAE para resolver uma tarefa mais mundana, ou seja, obter um espaço em branco para o futuro papel de parede do computador “Desktop”.
E como a grande maioria dos monitores modernos é caracterizada por uma proporção de 16:9, tomando para o lado menor o tamanho característico do quadrado base do modelo SD 1.5, ou seja, 512 pixels, para o lado maior obtemos 912. Mais precisamente, 910, mas devido a certos recursos de implementação dessa extensão do comprimento dos lados em suas configurações, na verdade, sempre acaba sendo um múltiplo de 4. Você pode verificar isso se não inserir manualmente “910” em a caixa correspondente, mas tente obter esse número clicando nas minúsculas setas para cima e para baixo localizadas no lado direito: para “ 904″ seguido imediatamente de “912”. Sim, é possível inserir “910” manualmente, mas na verdade o sistema arredondará esse valor para o anterior adequado mais próximo, ou seja, até 904 – você pode verificar isso abrindo a imagem resultante em qualquer editor gráfico, que mostrará suas dimensões exatas. E como o 912 ainda está mais próximo do 910 do que do 904, é melhor parar no 912.

Se você observar o espaço latente por tempo suficiente… (fonte: geração de IA com modelo SD 1.5)
Nota importante: o espaço latente não tolera confusão. Ao começar a gerar, mesmo no estágio inicial de configuração do ambiente de trabalho, deve-se ter clareza: para que será usada a imagem de sucesso resultante? Basta colocá-lo em uma pasta para que você possa assisti-lo mais tarde e admirá-lo? Então faz sentido desenhar um quadrado despretensioso; O “um e meio” é otimizado para isso, e os modelos treinados com base nele, no caso geral, darão resultados mais agradáveis u200bu200baos olhos, quanto mais próxima for a proporção da tela de um. Você precisa de um retrato de um determinado personagem – por exemplo, de um jogo de tabuleiro de fantasia, que você vai jogar? Uma proporção de 3:2 em formato de livro serve aqui. Eu gostaria de gerar uma bela paisagem, ou uma visão do desenvolvimento urbano, ou a comitiva de uma determinada sala – idealmente 2: 3, formato de paisagem.
É o Tiled Diffusion & VAE que permite gerar uma imagem com a relação de aspecto necessária imediatamente, de uma só vez, sem perder tempo com múltiplas outpainting, a que recorremos na segunda parte deste “Workshop”. É claro que, mesmo neste caso, é improvável que em pouco tempo alguém consiga tropeçar em uma imagem absolutamente ideal em termos de composição e detalhes: o espaço latente exige sacrifício. Certamente será necessário aplicar redesenho parcial (inpainting) e, possivelmente, refinamento manual de alguns fragmentos muito complexos (como todas as mesmas mãos ou – aqui está um paradoxo – as alças de bules; SD 1.5 por algum motivo prontamente gera bules magníficos e elegantes com dois bicos com muito mais frequência do que com um bico e uma alça normal) no editor de fotos.

Pincéis são como pincéis, um bule é como um bule – no espaço latente há outra coisa (fonte: geração de IA com modelo SD 1.5)
Além disso, é claro, no estágio final, não se pode prescindir da ampliação com detalhes aumentados – usando o script de upscale Ultimate SD, como fizemos da última vez, ou com as ferramentas integradas do próprio Tiled Diffusion & VAE. Mesmo assim, a aparência de uma imagem inicialmente bem-sucedida e essencialmente não quadrada na ausência dessa extensão é extremamente improvável e, portanto, seu uso é mais do que justificado apenas para papéis de parede.
⇡#Mais ladrilhos para o deus dos ladrilhos
Vamos definir esses valores de largura (Width) e altura (Height) da tela, que acabamos de discutir em relação ao papel de parede para monitores 16:9: 912 e 512, respectivamente.
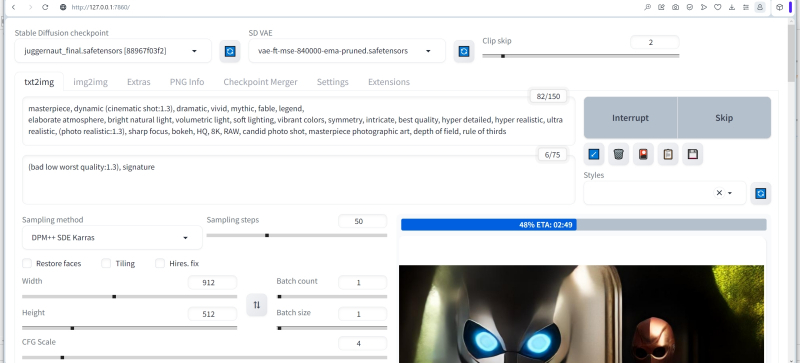
Em seguida, você precisa selecionar no menu suspenso “Método” o método real de espalhar tudo o que é supérfluo da “imagem inicialmente ruidosa”, que é o princípio de operação da Difusão Estável – “Multidifusão” ou “Mistura de difusores”. O autor da extensão não dá explicações claras sobre qual é exatamente a diferença entre eles, mas a prática mostra que o primeiro método desse par funciona mais rápido, mas os resultados são um pouco menos atraentes (em sentido amplo) que o segundo. De qualquer forma, faz sentido para os entusiastas da pintura de IA tentarem os dois métodos – com todos os outros parâmetros de geração iguais, é claro, incluindo semente, número de etapas e CFG – e decidirem por si mesmos qual é geralmente o melhor. Neste caso, colocaremos em serviço “Mistura de difusores”.
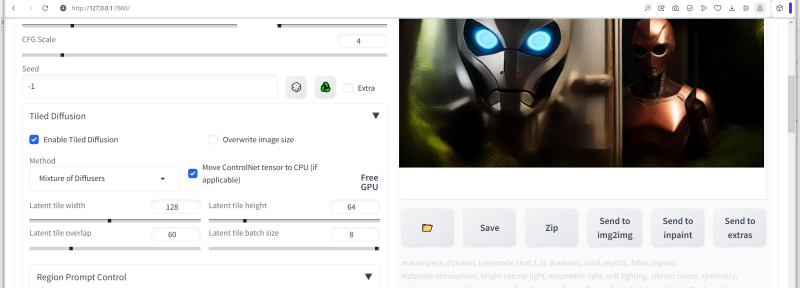
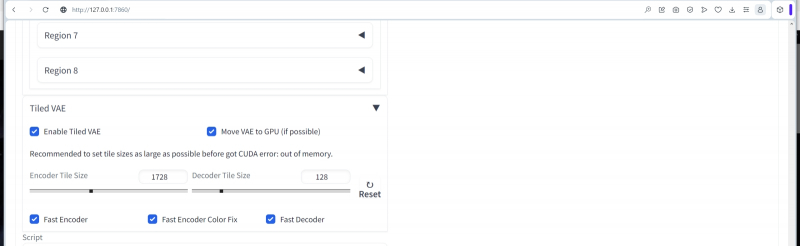
Em seguida, você precisa definir as dimensões do ladrilho único (ladrilho latente), no qual a tela será dividida para gerar uma única imagem – um ladrilho por vez. É graças a esta ferramenta que mesmo em uma GPU com pouca memória de vídeo, esta extensão permite criar extensas telas digitais – até mesmo para papéis de parede da área de trabalho, até mesmo para impressão em alta resolução. A regra geral fornecida pelos usuários hardcore do Tiled Diffusion & VAE é que deve haver aproximadamente 8,5 a 10 blocos em cada lado da tela – neste caso, a autoconsistência da imagem final certamente está no topo. Por esse motivo, em nosso caso, é lógico definir o valor de “Largura latente do ladrilho” para 128 e “Altura latente do ladrilho” para 64.
O valor “Latent ladrilho sobreposto” determina quantos pixels de ladrilhos adjacentes se sobrepõem, fornecendo integridade de composição de ponta a ponta da imagem final. Em geral, é óbvio que quanto maior esse parâmetro (dentro de limites razoáveis, é claro, sem ultrapassar o tamanho característico de uma única telha), melhor será o acordo mútuo em grande escala. Mas o tempo de geração obviamente aumenta em um fator do que é necessário para preencher uma única tela do mesmo tamanho sem sobreposições. Um compromisso razoável aqui parece ser um valor um pouco menor que o tamanho mínimo do ladrilho – em nosso caso, será, digamos, 60.
O parâmetro “Tamanho latente do lote de ladrilhos” define o número de ladrilhos gerados pelo sistema ao mesmo tempo. Tudo aqui depende diretamente da quantidade de memória de vídeo: quantos dados cabem nela – mas quanto mais, melhor. Isso não afeta a qualidade da imagem, mas determina diretamente o tempo de geração e, portanto, é melhor começar com no máximo 8 e diminuir esse valor apenas em caso de erros devido ao estouro da memória de vídeo.
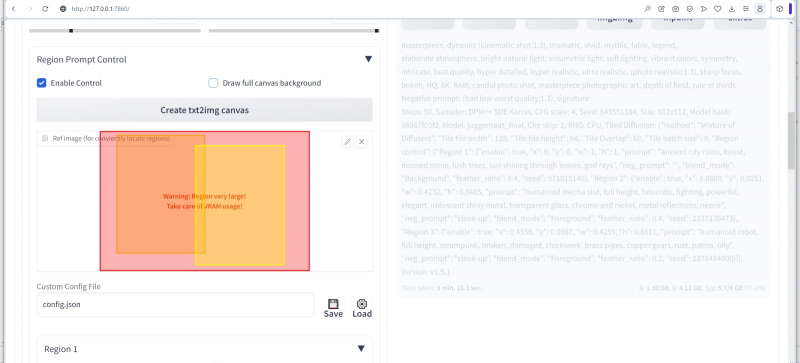
O bloco “Tiled Diffusion” é completado por outro submenu suspenso, “Region prompt control”, que é altamente recomendado para aprimorar a coerência da composição de imagens substancialmente não quadradas. Até o momento, controles de conectividade de composição mais poderosos foram criados para SD 1.5, principalmente ControlNet, com os quais nos familiarizaremos no futuro. Mas, em primeiro lugar, dicas ligadas a zonas (regiões) são funcionalidades integradas no Tiled Diffusion & VAE; Não requer nenhuma instalação adicional para sua implementação. E, em segundo lugar, o ControlNet funciona bem junto com os prompts de zona, o que aumenta muito os recursos de ambas as ferramentas.
Tendo aberto o menu suspenso “Region prompt control”, primeiro ativamos este elemento com a marca de seleção correspondente e, ao mesmo tempo, marcamos “Draw full canvas background”. Esta opção é necessária para que o fundo no qual os elementos da imagem espalhados pelas zonas serão localizados se torne comum a toda a imagem para que não se desfaça em zonas completamente independentes. Abaixo está um longo botão cinza “Criar tela txt2img”: após pressioná-lo, aparecerá uma janela na qual você pode mover, de fato, as zonas mencionadas mais de uma vez – em uma representação visual de retângulos translúcidos coloridos.
Se você clicar em um botão pequeno e quase imperceptível com um lápis no canto superior direito da janela de desenho, um fundo de xadrez característico marcará os limites de toda a imagem futura, uma espécie de layout. Como alternativa, você pode simplesmente arrastar qualquer imagem pronta com uma proporção adequada para esta janela – por exemplo, se ela for usada como referência para organizar os objetos do desenho gerado por IA como uma amostra.
Um ponto importante: as zonas destinadas ao uso de dicas zonais podem ser arrastadas com o mouse sobre este campo e com o mouse, agarrado ao lado ou canto, alterar seu tamanho. Porém, após a próxima alteração ser reconhecida como final, e imediatamente antes de prosseguir para o início da geração da imagem, você precisa clicar novamente em “Criar tela txt2img”, caso contrário, o sistema pode não captar corretamente as coordenadas dos limites zonais alterados.

Concretizamos a imagem desejada para nós mesmos – isso nos permitirá posteriormente compor uma dica de texto com mais precisão – da seguinte maneira: um robô futurista descobre seu antecessor de longa data da era steampunk em algumas ruínas condicionais. Para maior dinamismo, que sejam figuras de pé; pelo menos três quartos da altura (na altura dos joelhos), mas melhor na altura total. Ao mesmo tempo, os robôs devem ser claramente distinguíveis externamente à primeira vista: um é mais moderno e em movimento; o outro é arcaico e estático.

As imagens da mama também podem ser dinâmicas, como se o espaço latente estivesse nos ensinando (fonte: geração de IA com modelo SD 1.5)
No campo superior para inserir uma dica positiva, vamos coletar o conjunto de gatilhos verbais geralmente aceitos na comunidade de desenho de IA, que deve ser responsável pela formação de uma imagem fotorrealista, clara e altamente detalhada:
Obra-prima, dinâmico (plano cinematográfico: 1.3), dramático, vívido, mítico, fábula, lenda,
Atmosfera elaborada, luz natural brilhante, luz volumétrica, iluminação suave, cores vibrantes, simetria, intricado, melhor qualidade, hiper detalhado, hiper realista, ultra realista, (foto realista: 1.3), foco nítido, bokeh, HQ, 8K, RAW, foto espontânea, obra-prima da arte fotográfica, profundidade de campo, regra dos terços
Observe que não há nenhuma palavra aqui sobre robôs ou o ambiente em que eles deveriam estar, apenas as características qualitativas da imagem como um todo (incluindo termos especiais como “raios volumétricos” ou “regra dos terços”). A dica negativa é ainda mais simples:
(Má baixa pior qualidade:1.3), assinatura
Definimos o amostrador DPM++ SDE Karras, o número de etapas é 40, o valor CFG é 4,5.
Já definimos os parâmetros no bloco principal “Difusão lado a lado”, agora vamos fazer um controle zonal mais detalhado.
⇡#Encontrado no abismo
Abra o menu suspenso “Região 1”, ative esta zona (“Ativar”) e defina os seguintes parâmetros: no menu “Tipo”, deixe “Fundo” x = 0, y = 0, w = 1, h = 1. Deixe Seed – 1, claro, como no caso de uma dica geral para toda a imagem como um todo.
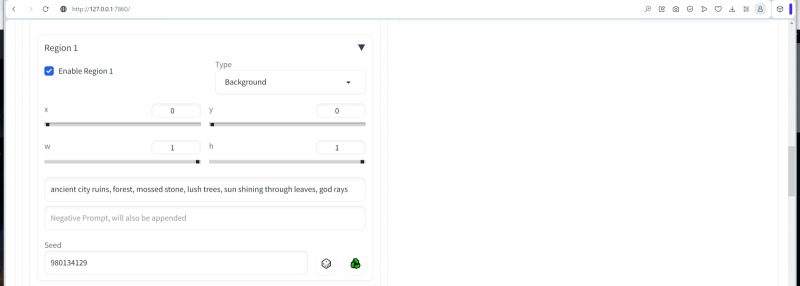
Nesse caso, um determinado valor da semeadura zonal é indicado, mas inicialmente deve ser deixado neste campo “-1”
Aqui (x, y) são as coordenadas do canto superior esquerdo do retângulo gerado e (w, h) são sua largura e comprimento em frações dos lados correspondentes da tela como um todo. Obviamente, desta forma formamos uma zona de fundo que cobre completamente toda a imagem. Nos campos destinados à entrada de texto, escreveremos uma dica zonal positiva –
Ruínas da cidade antiga, floresta, pedra coberta de musgo, árvores exuberantes, sol brilhando através das folhas, raios divinos
E deixe o campo negativo vazio.
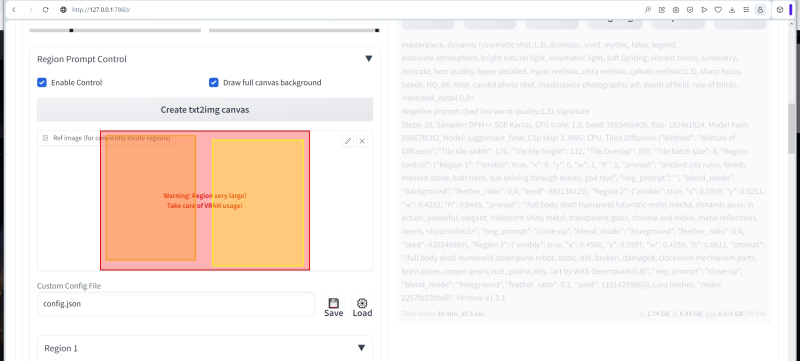
Se agora rolarmos a página um pouco mais alto, ficará claro que um retângulo rosado apareceu na representação gráfica da estrutura zonal de nossa imagem futura, estendendo-se por toda a área da tela.
Um ponto importante: tudo o que é indicado nos campos de texto de cada uma das zonas não substitui a dica comum a toda a imagem, mas é adicionado a ela. Em outras palavras, seria possível transferir a descrição da primeira zona para a dica de ferramenta principal e geralmente dispensar uma zona separada para o fundo, especialmente porque ativamos a opção “Desenhar fundo de tela inteira” anteriormente, para que mesmo em tais uma maneira implícita de que o plano de fundo fornecido seria comum a todas as zonas (com base em uma dica geral).
No entanto, a prática mostra que é melhor deixar apenas uma descrição geral de como a imagem deve ficar na dica principal e transferir tudo o que está representado nela para a zona (incluindo a de fundo), separando efetivamente as moscas latentes das as mesmas costeletas.
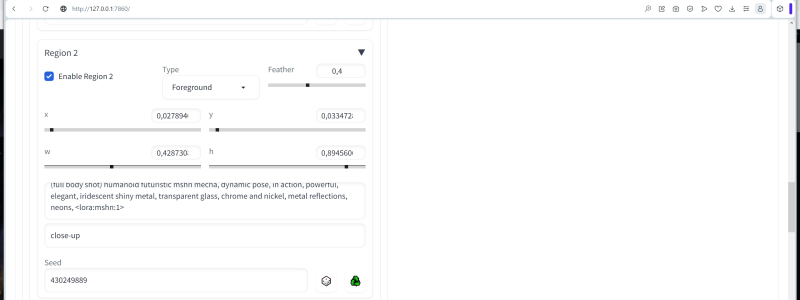
Agora ative “Região 2”, mas torne-a um “primeiro plano” condicional (opção “Foreground” no menu suspenso) com um desfoque de 0,4. O coeficiente de desfoque adimensional indica até que ponto o objeto deve se fundir com o fundo: em zero, ele é completamente e claramente delimitado por ele, como explica o autor de Tiled Diffusion & VAE em seu comentário; quando convertido em uma unidade, dissolve-se completamente nela. Conseqüentemente, um objeto com um desfoque de 0,4 deve dar a impressão de estar em algum lugar no meio entre o verdadeiro primeiro plano da imagem finalizada e seu verso. E que esse objeto seja apenas um robô futurista (mais precisamente, nem mesmo um robô, mas um mecha – um traje mecanizado) – com uma dica zonal tão positiva:
(Tiro de corpo inteiro) mecha futurista humanóide, pose dinâmica, em ação, poderoso, elegante, metal brilhante iridescente, vidro transparente, cromo e níquel, reflexos de metal, neons
E um negativo curto, que além do que acabamos de indicar (foto de corpo inteiro) proíbe o tiro de perto:
Fechar-se
Os limites da segunda zona são definidos da seguinte forma:
“
Mais precisamente, eles são definidos, é claro, a olho nu, movendo retângulos multicoloridos na janela correspondente um pouco mais alto, e o sistema insere corretamente os valores numéricos das bordas nos campos obrigatórios e os salva nas propriedades do arquivo PNG final, o que permite reproduzir facilmente suas imagens favoritas.
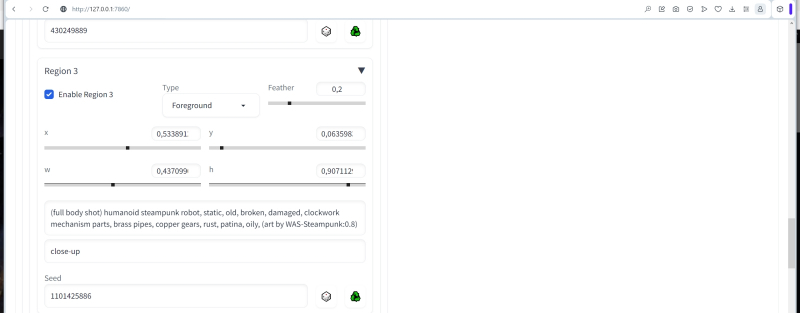
A terceira zona é também um “primeiro plano” condicional, também com desfoque, mas com um menor, nomeadamente 0,2, de forma a colocar este objeto mais próximo do observador. O objeto aqui será um robô steampunk:
(Tiro de corpo inteiro) robô humanóide steampunk, estático, velho, quebrado, danificado, peças de mecanismo de relógio, tubos de latão, engrenagens de cobre, ferrugem, pátina, oleoso
Com a mesma pista negativa
Fechar-se
E com bordas
“
Isso é suficiente em termos de dicas de zona, embora a extensão ofereça até oito zonas na imagem gerada.
Agora abra o menu suspenso “Tiled VAE” e ative este elemento. O princípio aqui é o mesmo do ponto de verificação principal – dividir toda a imagem em ladrilhos e gerá-los separadamente. Apenas não para o modelo principal pré-treinado (no nosso caso, juggernaut.final), mas para o autoencoder variacional (VAE), uma pequena rede neural adicional que atua sobre o ponto de verificação e melhora a qualidade geral da imagem gerada por o tema em termos de saturação de cores, nitidez de linhas, contraste.
Se a quantidade de RAM permitir (para 8 GB permite), o VAE deve ser movido inteiramente para a memória de vídeo para acelerar as operações correspondentes – coloque uma marca de seleção aqui. Os controles deslizantes com números geralmente não precisam ser tocados até que o próprio sistema dê a dica apropriada, mas se a codificação acelerada (“Fast Encoder”) for selecionada para economizar tempo, então “Fast Encoder Color Fix” também deve ser ativado, caso contrário, a saída a cor vai sofrer.

Quanto tempo, quão curto, mas então surge uma imagem em que quase tudo está bem, com exceção de um robô futurista. Ou seja, em geral, ele não é nada, mas duas listras escuras nas laterais o flanqueiam tão sem sucesso que arrancam parcialmente o objeto do fundo, principalmente a mão direita; enquanto as pernas continuam a permanecer com confiança em um lugar lógico apenas para o fundo. Como salvar a situação?
Sim, em geral, não é tão difícil. Pegamos a imagem resultante, transferimos para a guia “PNG Info” – e obtemos três sementes da saída de texto dos parâmetros de geração: para a imagem inteira como um todo (3583469409), para a primeira zona (fundo) (980134129 ) e para o terceiro (robô steampunk; 1101425886). Transferimos esses números para os campos “Seed” correspondentes a eles na guia “txt2img” (na verdade, essas sementes podem ser vistas em várias capturas de tela acima), e não há necessidade de sair do “Gerar para sempre” modo: tudo continua a funcionar silenciosamente. Como resultado, três sementes permanecem fixas durante as gerações subsequentes e uma – para a zona nº 2 – continua sendo gerada aleatoriamente a cada vez, gerando cada vez mais novas versões de robôs futuristas.

Depois de algum tempo, duas listras incompreensíveis se transformaram em fragmentos de uma porta ou portal, e a composição como um todo (com a semente 430249889 para a zona nº 2) tornou-se muito mais aceitável. Embora o resto de suas partes, e não apenas a zona com um robô futurista, tenha sofrido algumas mudanças. Não se deve esquecer que esta ainda é a geração de uma única imagem dividida em ladrilhos e, acima deles, em zonas: é por isso que é impossível, tendo fixado rigidamente até três das quatro sementes de trabalho, garantir a completa imutabilidade das imagens que formam. E, no entanto, graças ao controle de zona, a quantidade de gerações necessárias para obter uma imagem esteticamente aceitável é significativamente reduzida em comparação com o que teria que ser feito com uma única dica que menciona ruínas antigas e dois robôs de aparência completamente diferente,
⇡#Não há limite para a perfeição
Uma rede neural treinada para criar imagens com base em prompts de texto, com todo o desejo, não pode ser ensinada tudo de uma vez. Não haverá materiais preparados suficientes (imagens detalhadas anotadas), nem capacidade de computação e tempo adequados, nem recursos humanos. No entanto, retreinar o modelo sequencialmente, repetidamente adicionando novo “conhecimento” a ele (mais precisamente, “intuição”, já que o aprendizado de máquina envolve a formação de links associativos, e não a estruturação profunda e consciente da informação), também não é um opção: ficará cada vez mais pesado e, muito provavelmente, no processo de formação de novos laços, alguns dos antigos se enfraquecerão (isso terá que ser especialmente monitorado).
No início de 2023, foi encontrado um método para treinamento adicional rápido e bastante simples de modelos generativos para converter texto em imagens, além disso, em um conjunto bastante estreito de imagens iniciais anotadas, até dezenas e até unidades, – LoRA (de Baixo -rank Adaptation: significando que, para gerar links associativos adicionais, menos parâmetros e iterações são necessários aqui do que no curso do treinamento primário padrão de um modelo generativo). O sistema assim treinado tem a oportunidade de aplicar o estilo que domina (estilo de desenho, paleta de cores, até certo nível de detalhe da imagem) e/ou o conceito de certos objetos (um certo animal, personagem, objeto) a qualquer outras gerações, como se passasse a emissão de um checkpoint básico por um filtro adicional.

LoRA facilita muito a criação de várias imagens com o mesmo personagem específico: neste caso, Ruri Goko, também conhecido como “Kuroneko”, da light novel e anime Ore no Imouto ga Konna ni Kawaii Wake ga Nai (fonte: AI generation with modelo SD 1.5)
Entre as vantagens incondicionais do LoRA (comparado ao DreamBooth, por exemplo, uma incorporação anterior da mesma ideia, mas com meios algorítmicos ligeiramente diferentes) estão a alta velocidade de formação de links associativos, literalmente alguns minutos em uma boa placa de vídeo moderna, um tamanho modesto do arquivo de saída do modelo (dezenas, raramente centenas de MB) e a penalidade mínima de tempo para gerar uma única imagem em comparação com o modelo básico sem mini-redes neurais adicionais. Existe, infelizmente, uma desvantagem: LoRA não é muito confiante em lidar com rostos humanos. Essa tecnologia permite reproduzir quase um a um personagem de um anime ou jogo de computador, mas para pessoas reais, alguma “plasticidade” é marcante, principalmente em imagens que fingem ser fotografias realistas. Desenhar “sob fotorrealismo” é outra questão; aqui recorrer ao LoRA é mais do que apropriado.
Negativo mesmo – sem alteração
A primeira impressão do aplicativo antes mesmo de obter a imagem real, o tempo de geração única da imagem aumentou visivelmente – cerca de minutos antes da refeição, com a avaliação do sistema do tempo decorrido e restante na captura de tela fornecida na parte inferior direita. a imagem é gerada sem divisão em zonas, mas o carregamento do G permanece o mesmo nível – na área

Fonte&geração com modelo
A imagem melhorou claramente em geral, não apenas na zona da aparência de um robô futurista Novamente, como na situação com uma semente variável em quatro, a ativação de apenas uma das zonas inevitavelmente afeta o resto
Não há misticismo aqui, o próprio conceito implica a troca de informações entre ladrilhos adjacentes através de sua sobreposição mútua parcial, de modo que, em essência, para encaixar organicamente na composição geral qualquer mudança mais ou menos séria na água das zonas , cujos limites estão localizados arbitrariamente em relação aos limites dos ladrilhos, o sistema acaba precisando mudar algo não apenas nos ladrilhos que o compõem no todo ou em parte, mas e no vizinho eles são um pouco mais fracosvizinhosvizinhosetc
Observe que muitas vezes o aplicativo geralmente é ativado por uma ou outra palavra-chave, neste caso, é “” No entanto, neste caso, como observa o autor do projeto na página, isso nem é necessário
Agora vamos baixar o portal com outro nome sugestivo e colocar o arquivo do modelo no mesmo diretório enquanto anotamos a chamada——já a dica principal do nosso projeto, onde é descrito o estilo geral da imagem resultante. A dica principal agora parece assim, a parte positiva—
Negativo-

Fonte&geração com modelo
E, de fato, os detalhes ficaram muito maiores, o robô futurista ainda é dinâmico, embora tenha mudado um pouco sua pose, variando a força da ação de cada um dos mesmos parâmetros após o segundo dois pontos, que no primeiro caso é igual no segundo, você pode experimentar e depois tentar alcançar o mais aceitável com o artístico de várias maneiras subjetivas do ponto de vista estatístico do resultado Agora vamos continuar o experimento baixar arquivos invertidos de texto e placemey Ativado com força para a zona # onde o robô steampunk é desenhado
—Esta é uma dica positiva agora um antigo negativo

Fonte&geração com modelo
E aqui está certo, está tudo bem.Sim, o robô futurista tornou-se um tanto pesado primavera da lei da inversão de texto steampunk.

Fonte&geração com modelo
Aliás, principalmente para os interessados, eis o que acontece se a chamada para inversão de texto for apenas movida do prompt zonal para o principal, nada mais nas configurações, tocando no direto “Sherlock Holmes com histórias não contadas” vitoriano patrulha de robôs nas ruas estreitas de Londres – até o nevoeiro está presente graças à frase “” escrevendo o estilo geral Agora quero acreditar na importância do posicionamento correto de ferramentas adicionais para converter o texto em imagem, ou seja, as inversões de texto tornaram-se óbvio

Fonte&geração com modelo
O próximo passo em nosso “Workshop”, quase concluído hoje, será usar os recursos de & para ampliar imagens enquanto aumentamos os detalhes sem usar o script “” que nos ajudou a lidar com essa tarefa da última vez Na guia “”, nós retornará à seção “” e marcará a caixa “” Dois controles deslizantes aparecerão imediatamente – defina-os nas posições para a largura e para a altura da imagem, alteraremos os valores de “” – para “” – para “” – na seção “” ainda não tocaremos em nada E – novamente clique em “” O processo leva um pouco mais de uma hora na máquina

Fonte&geração com modelo
É por isso que vale a pena mexer e, claro, ao ampliar a imagem, e a sobreposição de ladrilhos foi diferente do que ao gerar a pequena variante original de uniformidade com as mesmas sementes e outro conjunto de parâmetros, então a imagem final é não apenas uma cópia ampliada do Não primário e a dinâmica do estresse e da história nele, talvez até mais, basta olhar para o robô urístico do pé esquerdo ausente, algum tipo de arma claramente comprável em seu braço direito e um brilho estranhamente ameaçador perto do antebraço de um andróide steampunk
De qualquer forma, enviamos a imagem resultante com resolução x para a guia “” com o botão correspondente, localizado à direita, abaixo da janela de visualização das imagens geradas. Definimos uma dica geralmente positiva
Este último é especialmente projetado para gerar robôs Borg altamente detalhados e outras estruturas semelhantes a humanos quanto possível. Ele dispara e a ausência de palavras-chave
A dica negativa será com o uso da inversão textual, cujo autor se propôs a reunir o feno e os conceitos mais usados nessa categoria para facilitar a vida dele e de outros e entusiastas A dica toda fica assim
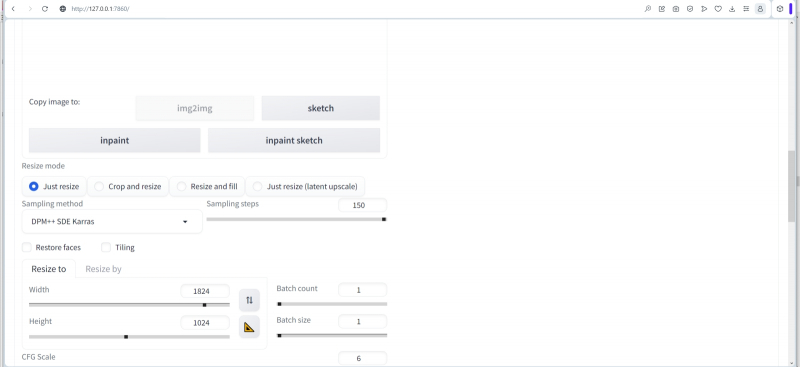
Agora vamos definir o método de amostragem—o já familiar número de etapas——quando for ampliado, rajadas criativas e melhor mantido sob controle mais confiável do que na geração inicial daqui—aumento—que está próximo a um equilíbrio razoável muito mais baixo—detalhes adicionais irão aparecem visivelmente mais quando ampliados – haverá tantos que a composição inicial será perturbada semente – valor aleatório “”
É importante neste caso que não seja necessário usar o mecanismo embutido para aumentar a resolução, recorrendo a ele novamente, ligue e desmarque a opção “” definir “” para o valor.

Fonte&geração com modelo
Kolkakyatopyatopovolino -reservatório de um reservatório de uma carga – uma produção baseada em impacto da publicação baseada em tecnologia de uma abundância de Umhenovorginal -em -processamento, habita de um impacto -meshocarticaricaponomelkimelkimolimolsostimpanovsky -navegável -apropriado é uma remontagem -livre -rendil -absorção do Autonarial – reatribuição do Autonomus perto do hikoriginaloparamet “”
Mas existe outra maneira de dobrar a resolução das imagens – a mesma que analisamos da última vez com o uso do script “” e exatamente os mesmos parâmetros de dicas para o número de etapas e verificação de & apenas

Fonte&geração com modelo
Aqui, o sistema conta mais rápido em menos de uma hora, mas também com carga máxima GPU humor mais detalhes finos novamente um pouco mais confuso do que no local mais naturalista – mas novamente, a menos que a imagem tenha piorado No tamanho original é disponível neste link
A busca do ideal no espaço latente está fadada ao fracasso toda vez que o operador parece encontrar algum ótimo – a pista de texto mais correta, o mais adequado, os parâmetros de geração mais bem-sucedidos – de repente, verifica-se que a mudança mínima na literalmente água em um um único lugar gera uma nova imagem e há uma chance muito pequena de parecer ainda mais atraente do que o primeiro
É por isso que os verdadeiros entusiastas da arte não gostam de confiar em recursos online para geração gratuita, geralmente há restrições extremamente rígidas, e o pago inevitavelmente ganha um bom dinheiro, você só precisa começar a brincar seriamente com os parâmetros disponíveis. , nas últimas três aulas do “Workshop” até agora, apenas abrimos ligeiramente a porta para este mundo incrível que nasce da espuma das possibilidades fervilhantes do espaço latente