
A verdade matemática, seja em Paris ou Toulouse, é a mesma.
Blaise Pascal
A regressão logística é um algoritmo com um segredo. Precisamos de uma pequena introdução sobre problemas de aprendizado de máquina em geral para entender o propósito para o qual esse algoritmo é usado. É uma regressão, certo? Vamos descobrir.
Quais tarefas o aprendizado de máquina resolve:
⇡#O que é regressão logística?
A regressão logística, como a regressão linear, foi emprestada da estatística. A marca registrada da regressão logística é que o valor da função é uma probabilidade. Probabilidade de quê? Pergunta legítima. Vamos falar sobre tudo em ordem.
Na entrada, a regressão logística, como a regressão linear, pega uma ou mais variáveis independentes (características do conjunto de dados) e calcula sua relação com a variável dependente. A diferença é que a regressão logística usa uma função sigmóide (também conhecida como função logística ou logit), que permite prever uma variável contínua com valores no intervalo [0, 1] para quaisquer valores das variáveis independentes . Na verdade, esta é a distribuição de Bernoulli (para quem estiver interessado).
Agora é hora de responder as perguntas acima.
A regressão logística calcula a probabilidade de um determinado valor de entrada pertencer a uma determinada classe. É usado para problemas de classificação: estima as probabilidades posteriores de um determinado objeto pertencer a uma determinada classe.
A regressão logística utiliza o método de máxima verossimilhança para avaliar o modelo. Baseia-se na suposição de que todas as informações sobre uma amostra estatística estão contidas na função de verossimilhança. Vamos tentar “nos dedos” formular seu princípio de ação. O objetivo do método é estimar os parâmetros da distribuição de probabilidade. O jeito é maximizar a função de verossimilhança. Esta função apenas determina a probabilidade dos valores dos parâmetros do modelo de regressão para um determinado valor da variável independente x=X:
P (θ) = P (x = X | θ),
Onde θ é o valor do parâmetro do modelo, P(θ) é a probabilidade de ocorrência do valor θ, X é o valor da variável independente x, para a qual a probabilidade condicional θ é determinada.
O problema é encontrar tais valores de parâmetros Θ = (θ1, θ2,…,θn) que maximizem a função de verossimilhança L(x|Θ). Para isso, são determinadas estimativas de máxima verossimilhança, para as quais os valores dos parâmetros são os mais “prováveis” em relação aos dados observados.
Se você quiser ainda mais matemática, recomendamos ler sobre o discriminante linear de Fisher.
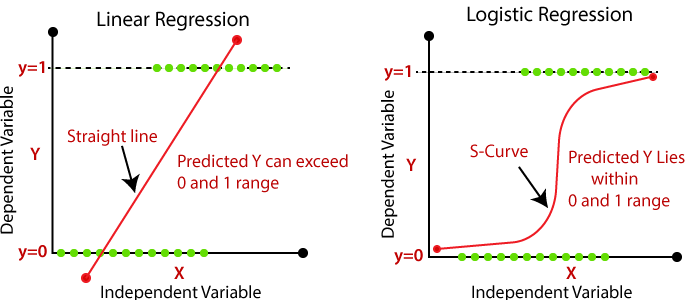
⇡#Regressão Linear e Regressão Logística: Semelhanças e diferenças frequentemente questionadas em entrevistas
Ambos os algoritmos são o alfa e o beta do aprendizado de máquina e da ciência de dados. Vejamos seus gráficos de funções:
Similaridade
Ambos os modelos são algoritmos de aprendizado de máquina supervisionados e usam equações lineares para previsões. Essa é toda a semelhança.
⇡#Diferenças
⇡#Por que regressão logística e o que nos importa?
Primeiro, é uma ótima maneira de começar no aprendizado de máquina. Faça qualquer curso de aprendizado de máquina e veja onde ele começa. Muito provavelmente será linear e depois regressão logística. O fato é que eles incorporam os dois principais métodos de aprendizado supervisionado – classificação e regressão. Ao estudar esses dois algoritmos, você se familiariza com os conceitos básicos, processos e problemas de aprendizado de máquina, aprende como preparar dados para processamento, selecionar recursos, avaliar o modelo de acordo com várias métricas (precisão – a proporção de respostas corretas, precisão – precisão, recall – completude, F-measure – F-measure, curva ROC – curva, correlação de Pearson – correlação de Pearson, erro quadrático médio – erro quadrático médio). Esses termos em inglês já estão em uso, então os apresentamos aqui.
Assim, você pode aprender tudo o que precisa sem uma arquitetura complexa e desordenada. Se você dedicar um tempo para fazer isso, entender completamente a regressão linear e logística e escrever o código, também poderá lidar com os mais recentes e poderosos algoritmos de IA. E sim, o aprendizado de máquina é um subconjunto da inteligência artificial. O Instituto de Tecnologia de Massachusetts também assume essa posição.
As redes neurais também se submeterão a você, porque cada neurônio individual é uma espécie de regressão logística. Um neurônio artificial imita o trabalho de uma célula nervosa viva, que soma todas as influências recebidas, e se o potencial elétrico da soma for maior que um certo limiar, então um potencial de ação (“pico”) se propagará através do neurônio receptor. Esta também é uma classificação binária, onde 0 e 1 são previstos, e em biologia esse princípio é chamado de “tudo ou nada”.
Portanto, muitas vezes acontece que a regressão logística é suficiente para resolver o problema. Devido à conveniência de interpretar os resultados, bem como sua capacidade de identificar as características mais significativas e significativas de um conjunto de dados, o LR é usado com sucesso, por exemplo, em finanças e negócios para avaliar a solvência de mutuários, segmentação de usuários (adquirir – não vai comprar um produto ou serviço), classificação de texto (spam – não spam, um comentário tóxico não é tóxico, etc.), em medicina para avaliar a probabilidade de desenvolver uma determinada doença e para muitas outras tarefas. Normalmente estamos falando de uma classificação binária, mas no caso de regressão logística múltipla (multinomial), a variável dependente pode ter várias categorias.
Essas informações devem ser suficientes para começar a aprender a regressão logística por conta própria. Recomendamos usar a biblioteca scikit-learn e experimentar. Desejamos-lhe sucesso!
Outros materiais do ciclo:
- Inteligência Artificial: Regressão Linear e seus Métodos de Treinamento
- Inteligência Artificial: Algoritmo Genético e Suas Aplicações
- Inteligência artificial: algoritmos de busca
- Eu quero estudar inteligência artificial!
- Ramos e direções da inteligência artificial: uma visão panorâmica
- Inteligência artificial e consciência: jogo de imitação
- Introdução à inteligência artificial
Fontes: